 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
Relative-Absolute Fusion: Rethinking Feature Extraction in Image-Based Iterative Method Selection for Solving Sparse Linear Systems
Oct 01, 2025Iterative method selection is crucial for solving sparse linear systems because these methods inherently lack robustness. Though image-based selection approaches have shown promise, their feature extraction techniques might encode distinct matrices into identical image representations, leading to the same selection and suboptimal method. In this paper, we introduce RAF (Relative-Absolute Fusion), an efficient feature extraction technique to enhance image-based selection approaches. By simultaneously extracting and fusing image representations as relative features with corresponding numerical values as absolute features, RAF achieves comprehensive matrix representations that prevent feature ambiguity across distinct matrices, thus improving selection accuracy and unlocking the potential of image-based selection approaches. We conducted comprehensive evaluations of RAF on SuiteSparse and our developed BMCMat (Balanced Multi-Classification Matrix dataset), demonstrating solution time reductions of 0.08s-0.29s for sparse linear systems, which is 5.86%-11.50% faster than conventional image-based selection approaches and achieves state-of-the-art (SOTA) performance. BMCMat is available at https://github.com/zkqq/BMCMat.
Advancing Loss Functions in Recommender Systems: A Comparative Study with a Rényi Divergence-Based Solution
Jun 18, 2025Loss functions play a pivotal role in optimizing recommendation models. Among various loss functions, Softmax Loss (SL) and Cosine Contrastive Loss (CCL) are particularly effective. Their theoretical connections and differences warrant in-depth exploration. This work conducts comprehensive analyses of these losses, yielding significant insights: 1) Common strengths -- both can be viewed as augmentations of traditional losses with Distributional Robust Optimization (DRO), enhancing robustness to distributional shifts; 2) Respective limitations -- stemming from their use of different distribution distance metrics in DRO optimization, SL exhibits high sensitivity to false negative instances, whereas CCL suffers from low data utilization. To address these limitations, this work proposes a new loss function, DrRL, which generalizes SL and CCL by leveraging R\'enyi-divergence in DRO optimization. DrRL incorporates the advantageous structures of both SL and CCL, and can be demonstrated to effectively mitigate their limitations. Extensive experiments have been conducted to validate the superiority of DrRL on both recommendation accuracy and robustness.
GUI-Robust: A Comprehensive Dataset for Testing GUI Agent Robustness in Real-World Anomalies
Jun 17, 2025



The development of high-quality datasets is crucial for benchmarking and advancing research in Graphical User Interface (GUI) agents. Despite their importance, existing datasets are often constructed under idealized conditions, overlooking the diverse anomalies frequently encountered in real-world deployments. To address this limitation, we introduce GUI-Robust, a novel dataset designed for comprehensive GUI agent evaluation, explicitly incorporating seven common types of anomalies observed in everyday GUI interactions. Furthermore, we propose a semi-automated dataset construction paradigm that collects user action sequences from natural interactions via RPA tools and then generate corresponding step and task descriptions for these actions with the assistance of MLLMs. This paradigm significantly reduces annotation time cost by a factor of over 19 times. Finally, we assess state-of-the-art GUI agents using the GUI-Robust dataset, revealing their substantial performance degradation in abnormal scenarios. We anticipate that our work will highlight the importance of robustness in GUI agents and inspires more future research in this direction. The dataset and code are available at https://github.com/chessbean1/GUI-Robust..
DualBreach: Efficient Dual-Jailbreaking via Target-Driven Initialization and Multi-Target Optimization
Apr 21, 2025Recent research has focused on exploring the vulnerabilities of Large Language Models (LLMs), aiming to elicit harmful and/or sensitive content from LLMs. However, due to the insufficient research on dual-jailbreaking -- attacks targeting both LLMs and Guardrails, the effectiveness of existing attacks is limited when attempting to bypass safety-aligned LLMs shielded by guardrails. Therefore, in this paper, we propose DualBreach, a target-driven framework for dual-jailbreaking. DualBreach employs a Target-driven Initialization (TDI) strategy to dynamically construct initial prompts, combined with a Multi-Target Optimization (MTO) method that utilizes approximate gradients to jointly adapt the prompts across guardrails and LLMs, which can simultaneously save the number of queries and achieve a high dual-jailbreaking success rate. For black-box guardrails, DualBreach either employs a powerful open-sourced guardrail or imitates the target black-box guardrail by training a proxy model, to incorporate guardrails into the MTO process. We demonstrate the effectiveness of DualBreach in dual-jailbreaking scenarios through extensive evaluation on several widely-used datasets. Experimental results indicate that DualBreach outperforms state-of-the-art methods with fewer queries, achieving significantly higher success rates across all settings. More specifically, DualBreach achieves an average dual-jailbreaking success rate of 93.67% against GPT-4 with Llama-Guard-3 protection, whereas the best success rate achieved by other methods is 88.33%. Moreover, DualBreach only uses an average of 1.77 queries per successful dual-jailbreak, outperforming other state-of-the-art methods. For the purpose of defense, we propose an XGBoost-based ensemble defensive mechanism named EGuard, which integrates the strengths of multiple guardrails, demonstrating superior performance compared with Llama-Guard-3.
ControlNET: A Firewall for RAG-based LLM System
Apr 13, 2025Retrieval-Augmented Generation (RAG) has significantly enhanced the factual accuracy and domain adaptability of Large Language Models (LLMs). This advancement has enabled their widespread deployment across sensitive domains such as healthcare, finance, and enterprise applications. RAG mitigates hallucinations by integrating external knowledge, yet introduces privacy risk and security risk, notably data breaching risk and data poisoning risk. While recent studies have explored prompt injection and poisoning attacks, there remains a significant gap in comprehensive research on controlling inbound and outbound query flows to mitigate these threats. In this paper, we propose an AI firewall, ControlNET, designed to safeguard RAG-based LLM systems from these vulnerabilities. ControlNET controls query flows by leveraging activation shift phenomena to detect adversarial queries and mitigate their impact through semantic divergence. We conduct comprehensive experiments on four different benchmark datasets including Msmarco, HotpotQA, FinQA, and MedicalSys using state-of-the-art open source LLMs (Llama3, Vicuna, and Mistral). Our results demonstrate that ControlNET achieves over 0.909 AUROC in detecting and mitigating security threats while preserving system harmlessness. Overall, ControlNET offers an effective, robust, harmless defense mechanism, marking a significant advancement toward the secure deployment of RAG-based LLM systems.
MSL: Not All Tokens Are What You Need for Tuning LLM as a Recommender
Apr 05, 2025Large language models (LLMs), known for their comprehension capabilities and extensive knowledge, have been increasingly applied to recommendation systems (RS). Given the fundamental gap between the mechanism of LLMs and the requirement of RS, researchers have focused on fine-tuning LLMs with recommendation-specific data to enhance their performance. Language Modeling Loss (LML), originally designed for language generation tasks, is commonly adopted. However, we identify two critical limitations of LML: 1) it exhibits significant divergence from the recommendation objective; 2) it erroneously treats all fictitious item descriptions as negative samples, introducing misleading training signals. To address these limitations, we propose a novel Masked Softmax Loss (MSL) tailored for fine-tuning LLMs on recommendation. MSL improves LML by identifying and masking invalid tokens that could lead to fictitious item descriptions during loss computation. This strategy can effectively avoid the interference from erroneous negative signals and ensure well alignment with the recommendation objective supported by theoretical guarantees. During implementation, we identify a potential challenge related to gradient vanishing of MSL. To overcome this, we further introduce the temperature coefficient and propose an Adaptive Temperature Strategy (ATS) that adaptively adjusts the temperature without requiring extensive hyperparameter tuning. Extensive experiments conducted on four public datasets further validate the effectiveness of MSL, achieving an average improvement of 42.24% in NDCG@10. The code is available at https://github.com/WANGBohaO-jpg/MSL.
Towards Label-Only Membership Inference Attack against Pre-trained Large Language Models
Feb 26, 2025Membership Inference Attacks (MIAs) aim to predict whether a data sample belongs to the model's training set or not. Although prior research has extensively explored MIAs in Large Language Models (LLMs), they typically require accessing to complete output logits (\ie, \textit{logits-based attacks}), which are usually not available in practice. In this paper, we study the vulnerability of pre-trained LLMs to MIAs in the \textit{label-only setting}, where the adversary can only access generated tokens (text). We first reveal that existing label-only MIAs have minor effects in attacking pre-trained LLMs, although they are highly effective in inferring fine-tuning datasets used for personalized LLMs. We find that their failure stems from two main reasons, including better generalization and overly coarse perturbation. Specifically, due to the extensive pre-training corpora and exposing each sample only a few times, LLMs exhibit minimal robustness differences between members and non-members. This makes token-level perturbations too coarse to capture such differences. To alleviate these problems, we propose \textbf{PETAL}: a label-only membership inference attack based on \textbf{PE}r-\textbf{T}oken sem\textbf{A}ntic simi\textbf{L}arity. Specifically, PETAL leverages token-level semantic similarity to approximate output probabilities and subsequently calculate the perplexity. It finally exposes membership based on the common assumption that members are `better' memorized and have smaller perplexity. We conduct extensive experiments on the WikiMIA benchmark and the more challenging MIMIR benchmark. Empirically, our PETAL performs better than the extensions of existing label-only attacks against personalized LLMs and even on par with other advanced logit-based attacks across all metrics on five prevalent open-source LLMs.
Uncertainty-Aware Graph Structure Learning
Feb 19, 2025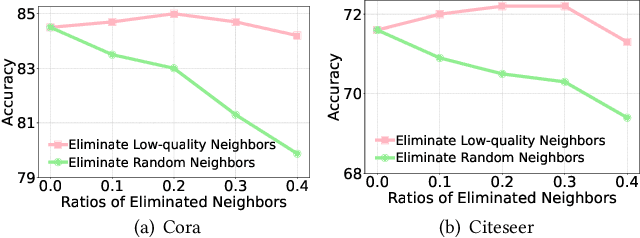
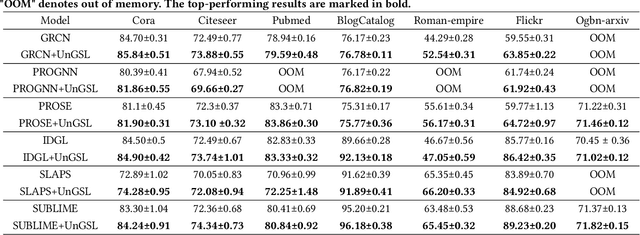
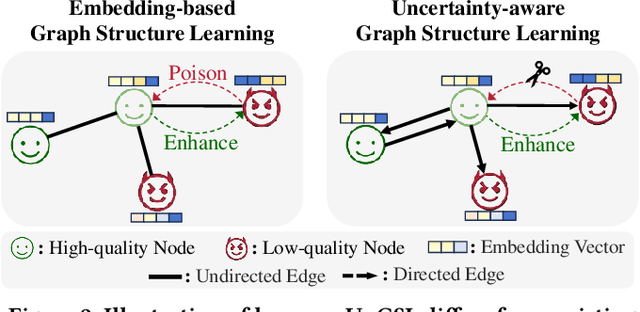
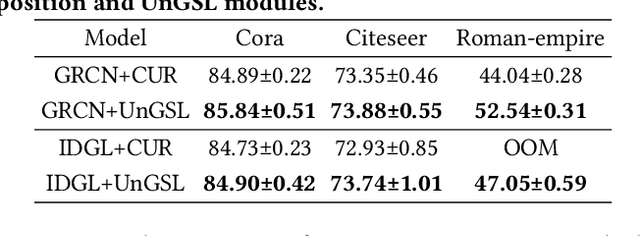
Graph Neural Networks (GNNs) have become a prominent approach for learning from graph-structured data. However, their effectiveness can be significantly compromised when the graph structure is suboptimal. To address this issue, Graph Structure Learning (GSL) has emerged as a promising technique that refines node connections adaptively. Nevertheless, we identify two key limitations in existing GSL methods: 1) Most methods primarily focus on node similarity to construct relationships, while overlooking the quality of node information. Blindly connecting low-quality nodes and aggregating their ambiguous information can degrade the performance of other nodes. 2) The constructed graph structures are often constrained to be symmetric, which may limit the model's flexibility and effectiveness. To overcome these limitations, we propose an Uncertainty-aware Graph Structure Learning (UnGSL) strategy. UnGSL estimates the uncertainty of node information and utilizes it to adjust the strength of directional connections, where the influence of nodes with high uncertainty is adaptively reduced. Importantly, UnGSL serves as a plug-in module that can be seamlessly integrated into existing GSL methods with minimal additional computational cost. In our experiments, we implement UnGSL into six representative GSL methods, demonstrating consistent performance improvements.