 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubspace-Guided Semantic and Topological Invariant Registration for Annotation-Free Ultrasound Plane Quality Control
May 25, 2026Reliable quality control (QC) of ultrasound images is essential for both real-time acquisition guidance and retrospective clinical audit, yet existing approaches rely heavily on per-plane annotations, or employ pseudo-labeling prone to systematic bias under spatial deformations inherent in clinical acquisition. We present STRIQ, a registration-driven framework that recasts annotation-free US plane quality control as a subspace-guided consistency measurement problem. Specifically, STRIQ introduces a Latent Registration Aligner (LRA) to establish hierarchical feature space correspondences between query images and variance-driven anchors, which are autonomously distilled from unlabeled data via a variance spectrum criterion to serve as structurally stable prototypes. To further disambiguate anatomical planes and mitigate negative knowledge transfer, we propose an Orthogonal Knowledge Subspace (OKS) module. The OKS decomposes plane-specific representations into mutually orthogonal subspaces, enabling fine-grained expert collaboration while preventing inter-plane interference, ensuring that the quality metric is grounded in principled subspace proximity. Extensive experiments on the in-house US4QA and public CAMUS datasets demonstrate that STRIQ achieves state-of-the-art correlation with clinical quality scores, establishing a new paradigm for annotation-free, real-time reliable ultrasound quality control. Our code is available at https://github.com/zhcz328/STRIQ.
Analyzing and Improving Fast Sampling of Text-to-Image Diffusion Models
Feb 28, 2026Text-to-image diffusion models have achieved unprecedented success but still struggle to produce high-quality results under limited sampling budgets. Existing training-free sampling acceleration methods are typically developed independently, leaving the overall performance and compatibility among these methods unexplored. In this paper, we bridge this gap by systematically elucidating the design space, and our comprehensive experiments identify the sampling time schedule as the most pivotal factor. Inspired by the geometric properties of diffusion models revealed through the Frenet-Serret formulas, we propose constant total rotation schedule (TORS), a scheduling strategy that ensures uniform geometric variation along the sampling trajectory. TORS outperforms previous training-free acceleration methods and produces high-quality images with 10 sampling steps on Flux.1-Dev and Stable Diffusion 3.5. Extensive experiments underscore the adaptability of our method to unseen models, hyperparameters, and downstream applications.
Geometric Regularity in Deterministic Sampling of Diffusion-based Generative Models
Jun 11, 2025Diffusion-based generative models employ stochastic differential equations (SDEs) and their equivalent probability flow ordinary differential equations (ODEs) to establish a smooth transformation between complex high-dimensional data distributions and tractable prior distributions. In this paper, we reveal a striking geometric regularity in the deterministic sampling dynamics: each simulated sampling trajectory lies within an extremely low-dimensional subspace, and all trajectories exhibit an almost identical ''boomerang'' shape, regardless of the model architecture, applied conditions, or generated content. We characterize several intriguing properties of these trajectories, particularly under closed-form solutions based on kernel-estimated data modeling. We also demonstrate a practical application of the discovered trajectory regularity by proposing a dynamic programming-based scheme to better align the sampling time schedule with the underlying trajectory structure. This simple strategy requires minimal modification to existing ODE-based numerical solvers, incurs negligible computational overhead, and achieves superior image generation performance, especially in regions with only $5 \sim 10$ function evaluations.
An Investigation on Speaker Augmentation for End-to-End Speaker Extraction
May 27, 2025Target confusion, defined as occasional switching to non-target speakers, poses a key challenge for end-to-end speaker extraction (E2E-SE) systems. We argue that this problem is largely caused by the lack of generalizability and discrimination of the speaker embeddings, and introduce a simple yet effective speaker augmentation strategy to tackle the problem. Specifically, we propose a time-domain resampling and rescaling pipeline that alters speaker traits while preserving other speech properties. This generates a variety of pseudo-speakers to help establish a generalizable speaker embedding space, while the speaker-trait-specific augmentation creates hard samples that force the model to focus on genuine speaker characteristics. Experiments on WSJ0-2Mix and LibriMix show that our method mitigates the target confusion and improves extraction performance. Moreover, it can be combined with metric learning, another effective approach to address target confusion, leading to further gains.
DICE: Distilling Classifier-Free Guidance into Text Embeddings
Feb 06, 2025



Text-to-image diffusion models are capable of generating high-quality images, but these images often fail to align closely with the given text prompts. Classifier-free guidance (CFG) is a popular and effective technique for improving text-image alignment in the generative process. However, using CFG introduces significant computational overhead and deviates from the established theoretical foundations of diffusion models. In this paper, we present DIstilling CFG by enhancing text Embeddings (DICE), a novel approach that removes the reliance on CFG in the generative process while maintaining the benefits it provides. DICE distills a CFG-based text-to-image diffusion model into a CFG-free version by refining text embeddings to replicate CFG-based directions. In this way, we avoid the computational and theoretical drawbacks of CFG, enabling high-quality, well-aligned image generation at a fast sampling speed. Extensive experiments on multiple Stable Diffusion v1.5 variants, SDXL and PixArt-$\alpha$ demonstrate the effectiveness of our method. Furthermore, DICE supports negative prompts for image editing to improve image quality further. Code will be available soon.
Improving the Reliability of Cable Broadband Networks via Proactive Network Maintenance
Dec 12, 2024Cable broadband networks are one of the few "last-mile" broadband technologies widely available in the U.S. Unfortunately, they have poor reliability after decades of deployment. The cable industry proposed a framework called Proactive Network Maintenance (PNM) to diagnose the cable networks. However, there is little public knowledge or systematic study on how to use these data to detect and localize cable network problems. Existing tools in the public domain have prohibitive high false-positive rates. In this paper, we propose CableMon, the first public-domain system that applies machine learning techniques to PNM data to improve the reliability of cable broadband networks. CableMon tackles two key challenges faced by cable ISPs: accurately detecting failures, and distinguishing whether a failure occurs within a network or at a subscriber's premise. CableMon uses statistical models to generate features from time series data and uses customer trouble tickets as hints to infer abnormal/failure thresholds for these generated features. Further, CableMon employs an unsupervised learning model to group cable devices sharing similar anomalous patterns and effectively identify impairments that occur inside a cable network and impairments occur at a subscriber's premise, as these two different faults require different types of technical personnel to repair them. We use eight months of PNM data and customer trouble tickets from an ISP and experimental deployment to evaluate CableMon's performance. Our evaluation results show that CableMon can effectively detect and distinguish failures from PNM data and outperforms existing public-domain tools.
TelApart: Differentiating Network Faults from Customer-Premise Faults in Cable Broadband Networks
Dec 12, 2024Two types of radio frequency (RF) impairments frequently occur in a cable broadband network: impairments that occur inside a cable network and impairments occur at the edge of the broadband network, i.e., in a subscriber's premise. Differentiating these two types of faults is important, as different faults require different types of technical personnel to repair them. Presently, the cable industry lacks publicly available tools to automatically diagnose the type of fault. In this work, we present TelApart, a fault diagnosis system for cable broadband networks. TelApart uses telemetry data collected by the Proactive Network Maintenance (PNM) infrastructure in cable networks to effectively differentiate the type of fault. Integral to TelApart's design is an unsupervised machine learning model that groups cable devices sharing similar anomalous patterns together. We use metrics derived from an ISP's customer trouble tickets to programmatically tune the model's hyper-parameters so that an ISP can deploy TelApart in various conditions without hand-tuning its hyper-parameters. We also address the data challenge that the telemetry data collected by the PNM system contain numerous missing, duplicated, and unaligned data points. Using real-world data contributed by a cable ISP, we show that TelApart can effectively identify different types of faults.
Towards More Accurate Fake Detection on Images Generated from Advanced Generative and Neural Rendering Models
Nov 13, 2024

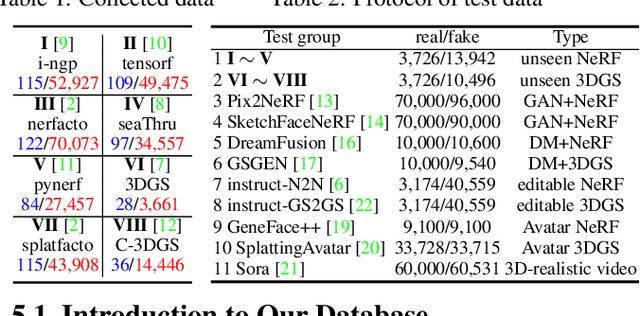

The remarkable progress in neural-network-driven visual data generation, especially with neural rendering techniques like Neural Radiance Fields and 3D Gaussian splatting, offers a powerful alternative to GANs and diffusion models. These methods can produce high-fidelity images and lifelike avatars, highlighting the need for robust detection methods. In response, an unsupervised training technique is proposed that enables the model to extract comprehensive features from the Fourier spectrum magnitude, thereby overcoming the challenges of reconstructing the spectrum due to its centrosymmetric properties. By leveraging the spectral domain and dynamically combining it with spatial domain information, we create a robust multimodal detector that demonstrates superior generalization capabilities in identifying challenging synthetic images generated by the latest image synthesis techniques. To address the absence of a 3D neural rendering-based fake image database, we develop a comprehensive database that includes images generated by diverse neural rendering techniques, providing a robust foundation for evaluating and advancing detection methods.
Neural Scoring, Not Embedding: A Novel Framework for Robust Speaker Verification
Oct 21, 2024


Current mainstream speaker verification systems are predominantly based on the concept of ``speaker embedding", which transforms variable-length speech signals into fixed-length speaker vectors, followed by verification based on cosine similarity between the embeddings of the enrollment and test utterances. However, this approach suffers from considerable performance degradation in the presence of severe noise and interference speakers. This paper introduces Neural Scoring, a novel framework that re-treats speaker verification as a scoring task using a Transformer-based architecture. The proposed method first extracts an embedding from the enrollment speech and frame-level features from the test speech. A Transformer network then generates a decision score that quantifies the likelihood of the enrolled speaker being present in the test speech. We evaluated Neural Scoring on the VoxCeleb dataset across five test scenarios, comparing it with the state-of-the-art embedding-based approach. While Neural Scoring achieves comparable performance to the state-of-the-art under the benchmark (clean) test condition, it demonstrates a remarkable advantage in the four complex scenarios, achieving an overall 64.53% reduction in equal error rate (EER) compared to the baseline.
Simple and Fast Distillation of Diffusion Models
Sep 29, 2024



Diffusion-based generative models have demonstrated their powerful performance across various tasks, but this comes at a cost of the slow sampling speed. To achieve both efficient and high-quality synthesis, various distillation-based accelerated sampling methods have been developed recently. However, they generally require time-consuming fine tuning with elaborate designs to achieve satisfactory performance in a specific number of function evaluation (NFE), making them difficult to employ in practice. To address this issue, we propose Simple and Fast Distillation (SFD) of diffusion models, which simplifies the paradigm used in existing methods and largely shortens their fine-tuning time up to 1000$\times$. We begin with a vanilla distillation-based sampling method and boost its performance to state of the art by identifying and addressing several small yet vital factors affecting the synthesis efficiency and quality. Our method can also achieve sampling with variable NFEs using a single distilled model. Extensive experiments demonstrate that SFD strikes a good balance between the sample quality and fine-tuning costs in few-step image generation task. For example, SFD achieves 4.53 FID (NFE=2) on CIFAR-10 with only 0.64 hours of fine-tuning on a single NVIDIA A100 GPU. Our code is available at https://github.com/zju-pi/diff-sampler.