 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation on Speaker Augmentation for End-to-End Speaker Extraction
May 27, 2025Target confusion, defined as occasional switching to non-target speakers, poses a key challenge for end-to-end speaker extraction (E2E-SE) systems. We argue that this problem is largely caused by the lack of generalizability and discrimination of the speaker embeddings, and introduce a simple yet effective speaker augmentation strategy to tackle the problem. Specifically, we propose a time-domain resampling and rescaling pipeline that alters speaker traits while preserving other speech properties. This generates a variety of pseudo-speakers to help establish a generalizable speaker embedding space, while the speaker-trait-specific augmentation creates hard samples that force the model to focus on genuine speaker characteristics. Experiments on WSJ0-2Mix and LibriMix show that our method mitigates the target confusion and improves extraction performance. Moreover, it can be combined with metric learning, another effective approach to address target confusion, leading to further gains.
Neural Scoring, Not Embedding: A Novel Framework for Robust Speaker Verification
Oct 21, 2024


Current mainstream speaker verification systems are predominantly based on the concept of ``speaker embedding", which transforms variable-length speech signals into fixed-length speaker vectors, followed by verification based on cosine similarity between the embeddings of the enrollment and test utterances. However, this approach suffers from considerable performance degradation in the presence of severe noise and interference speakers. This paper introduces Neural Scoring, a novel framework that re-treats speaker verification as a scoring task using a Transformer-based architecture. The proposed method first extracts an embedding from the enrollment speech and frame-level features from the test speech. A Transformer network then generates a decision score that quantifies the likelihood of the enrolled speaker being present in the test speech. We evaluated Neural Scoring on the VoxCeleb dataset across five test scenarios, comparing it with the state-of-the-art embedding-based approach. While Neural Scoring achieves comparable performance to the state-of-the-art under the benchmark (clean) test condition, it demonstrates a remarkable advantage in the four complex scenarios, achieving an overall 64.53% reduction in equal error rate (EER) compared to the baseline.
AlignVSR: Audio-Visual Cross-Modal Alignment for Visual Speech Recognition
Oct 21, 2024



Visual Speech Recognition (VSR) aims to recognize corresponding text by analyzing visual information from lip movements. Due to the high variability and weak information of lip movements, VSR tasks require effectively utilizing any information from any source and at any level. In this paper, we propose a VSR method based on audio-visual cross-modal alignment, named AlignVSR. The method leverages the audio modality as an auxiliary information source and utilizes the global and local correspondence between the audio and visual modalities to improve visual-to-text inference. Specifically, the method first captures global alignment between video and audio through a cross-modal attention mechanism from video frames to a bank of audio units. Then, based on the temporal correspondence between audio and video, a frame-level local alignment loss is introduced to refine the global alignment, improving the utility of the audio information. Experimental results on the LRS2 and CNVSRC.Single datasets consistently show that AlignVSR outperforms several mainstream VSR methods, demonstrating its superior and robust performance.
Quantitative Analysis of Audio-Visual Tasks: An Information-Theoretic Perspective
Sep 29, 2024



In the field of spoken language processing, audio-visual speech processing is receiving increasing research attention. Key components of this research include tasks such as lip reading, audio-visual speech recognition, and visual-to-speech synthesis. Although significant success has been achieved, theoretical analysis is still insufficient for audio-visual tasks. This paper presents a quantitative analysis based on information theory, focusing on information intersection between different modalities. Our results show that this analysis is valuable for understanding the difficulties of audio-visual processing tasks as well as the benefits that could be obtained by modality integration.
Serialized Output Training by Learned Dominance
Jul 04, 2024Serialized Output Training (SOT) has showcased state-of-the-art performance in multi-talker speech recognition by sequentially decoding the speech of individual speakers. To address the challenging label-permutation issue, prior methods have relied on either the Permutation Invariant Training (PIT) or the time-based First-In-First-Out (FIFO) rule. This study presents a model-based serialization strategy that incorporates an auxiliary module into the Attention Encoder-Decoder architecture, autonomously identifying the crucial factors to order the output sequence of the speech components in multi-talker speech. Experiments conducted on the LibriSpeech and LibriMix databases reveal that our approach significantly outperforms the PIT and FIFO baselines in both 2-mix and 3-mix scenarios. Further analysis shows that the serialization module identifies dominant speech components in a mixture by factors including loudness and gender, and orders speech components based on the dominance score.
CNVSRC 2023: The First Chinese Continuous Visual Speech Recognition Challenge
Jun 14, 2024



The first Chinese Continuous Visual Speech Recognition Challenge aimed to probe the performance of Large Vocabulary Continuous Visual Speech Recognition (LVC-VSR) on two tasks: (1) Single-speaker VSR for a particular speaker and (2) Multi-speaker VSR for a set of registered speakers. The challenge yielded highly successful results, with the best submission significantly outperforming the baseline, particularly in the single-speaker task. This paper comprehensively reviews the challenge, encompassing the data profile, task specifications, and baseline system construction. It also summarises the representative techniques employed by the submitted systems, highlighting the most effective approaches. Additional information and resources about this challenge can be accessed through the official website at http://cnceleb.org/competition.
SE/BN Adapter: Parametric Efficient Domain Adaptation for Speaker Recognition
Jun 12, 2024
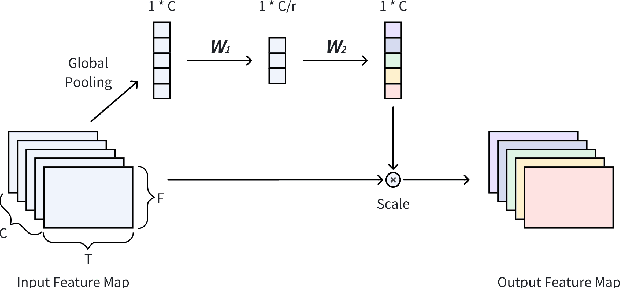

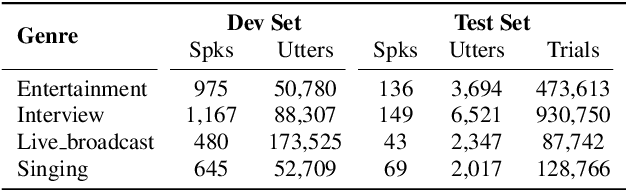
Deploying a well-optimized pre-trained speaker recognition model in a new domain often leads to a significant decline in performance. While fine-tuning is a commonly employed solution, it demands ample adaptation data and suffers from parameter inefficiency, rendering it impractical for real-world applications with limited data available for model adaptation. Drawing inspiration from the success of adapters in self-supervised pre-trained models, this paper introduces a SE/BN adapter to address this challenge. By freezing the core speaker encoder and adjusting the feature maps' weights and activation distributions, we introduce a novel adapter utilizing trainable squeeze-and-excitation (SE) blocks and batch normalization (BN) layers, termed SE/BN adapter. Our experiments, conducted using VoxCeleb for pre-training and 4 genres from CN-Celeb for adaptation, demonstrate that the SE/BN adapter offers significant performance improvement over the baseline and competes with the vanilla fine-tuning approach by tuning just 1% of the parameters.
Zero-Shot Fake Video Detection by Audio-Visual Consistency
Jun 12, 2024



Recent studies have advocated the detection of fake videos as a one-class detection task, predicated on the hypothesis that the consistency between audio and visual modalities of genuine data is more significant than that of fake data. This methodology, which solely relies on genuine audio-visual data while negating the need for forged counterparts, is thus delineated as a `zero-shot' detection paradigm. This paper introduces a novel zero-shot detection approach anchored in content consistency across audio and video. By employing pre-trained ASR and VSR models, we recognize the audio and video content sequences, respectively. Then, the edit distance between the two sequences is computed to assess whether the claimed video is genuine. Experimental results indicate that, compared to two mainstream approaches based on semantic consistency and temporal consistency, our approach achieves superior generalizability across various deepfake techniques and demonstrates strong robustness against audio-visual perturbations. Finally, state-of-the-art performance gains can be achieved by simply integrating the decision scores of these three systems.
A Comprehensive Investigation on Speaker Augmentation for Speaker Recognition
Jun 11, 2024



Data augmentation (DA) has played a pivotal role in the success of deep speaker recognition. Current DA techniques primarily focus on speaker-preserving augmentation, which does not change the speaker trait of the speech and does not create new speakers. Recent research has shed light on the potential of speaker augmentation, which generates new speakers to enrich the training dataset. In this study, we delve into two speaker augmentation approaches: speed perturbation (SP) and vocal tract length perturbation (VTLP). Despite the empirical utilization of both methods, a comprehensive investigation into their efficacy is lacking. Our study, conducted using two public datasets, VoxCeleb and CN-Celeb, revealed that both SP and VTLP are proficient at generating new speakers, leading to significant performance improvements in speaker recognition. Furthermore, they exhibit distinct properties in sensitivity to perturbation factors and data complexity, hinting at the potential benefits of their fusion. Our research underscores the substantial potential of speaker augmentation, highlighting the importance of in-depth exploration and analysis.
Adversarial Data Augmentation for Robust Speaker Verification
Feb 05, 2024


Data augmentation (DA) has gained widespread popularity in deep speaker models due to its ease of implementation and significant effectiveness. It enriches training data by simulating real-life acoustic variations, enabling deep neural networks to learn speaker-related representations while disregarding irrelevant acoustic variations, thereby improving robustness and generalization. However, a potential issue with the vanilla DA is augmentation residual, i.e., unwanted distortion caused by different types of augmentation. To address this problem, this paper proposes a novel approach called adversarial data augmentation (A-DA) which combines DA with adversarial learning. Specifically, it involves an additional augmentation classifier to categorize various augmentation types used in data augmentation. This adversarial learning empowers the network to generate speaker embeddings that can deceive the augmentation classifier, making the learned speaker embeddings more robust in the face of augmentation variations. Experiments conducted on VoxCeleb and CN-Celeb datasets demonstrate that our proposed A-DA outperforms standard DA in both augmentation matched and mismatched test conditions, showcasing its superior robustness and generalization against acoustic variations.