 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYet Another Watermark for Large Language Models
Sep 16, 2025Existing watermarking methods for large language models (LLMs) mainly embed watermark by adjusting the token sampling prediction or post-processing, lacking intrinsic coupling with LLMs, which may significantly reduce the semantic quality of the generated marked texts. Traditional watermarking methods based on training or fine-tuning may be extendable to LLMs. However, most of them are limited to the white-box scenario, or very time-consuming due to the massive parameters of LLMs. In this paper, we present a new watermarking framework for LLMs, where the watermark is embedded into the LLM by manipulating the internal parameters of the LLM, and can be extracted from the generated text without accessing the LLM. Comparing with related methods, the proposed method entangles the watermark with the intrinsic parameters of the LLM, which better balances the robustness and imperceptibility of the watermark. Moreover, the proposed method enables us to extract the watermark under the black-box scenario, which is computationally efficient for use. Experimental results have also verified the feasibility, superiority and practicality. This work provides a new perspective different from mainstream works, which may shed light on future research.
Serialized Output Training by Learned Dominance
Jul 04, 2024Serialized Output Training (SOT) has showcased state-of-the-art performance in multi-talker speech recognition by sequentially decoding the speech of individual speakers. To address the challenging label-permutation issue, prior methods have relied on either the Permutation Invariant Training (PIT) or the time-based First-In-First-Out (FIFO) rule. This study presents a model-based serialization strategy that incorporates an auxiliary module into the Attention Encoder-Decoder architecture, autonomously identifying the crucial factors to order the output sequence of the speech components in multi-talker speech. Experiments conducted on the LibriSpeech and LibriMix databases reveal that our approach significantly outperforms the PIT and FIFO baselines in both 2-mix and 3-mix scenarios. Further analysis shows that the serialization module identifies dominant speech components in a mixture by factors including loudness and gender, and orders speech components based on the dominance score.
A Glance is Enough: Extract Target Sentence By Looking at A keyword
Oct 09, 2023This paper investigates the possibility of extracting a target sentence from multi-talker speech using only a keyword as input. For example, in social security applications, the keyword might be "help", and the goal is to identify what the person who called for help is articulating while ignoring other speakers. To address this problem, we propose using the Transformer architecture to embed both the keyword and the speech utterance and then rely on the cross-attention mechanism to select the correct content from the concatenated or overlapping speech. Experimental results on Librispeech demonstrate that our proposed method can effectively extract target sentences from very noisy and mixed speech (SNR=-3dB), achieving a phone error rate (PER) of 26\%, compared to the baseline system's PER of 96%.
Spot keywords from very noisy and mixed speech
May 28, 2023Most existing keyword spotting research focuses on conditions with slight or moderate noise. In this paper, we try to tackle a more challenging task: detecting keywords buried under strong interfering speech (10 times higher than the keyword in amplitude), and even worse, mixed with other keywords. We propose a novel Mix Training (MT) strategy that encourages the model to discover low-energy keywords from noisy and mixed speech. Experiments were conducted with a vanilla CNN and two EfficientNet (B0/B2) architectures. The results evaluated with the Google Speech Command dataset demonstrated that the proposed mix training approach is highly effective and outperforms standard data augmentation and mixup training.
Can We Trust Deep Speech Prior?
Nov 04, 2020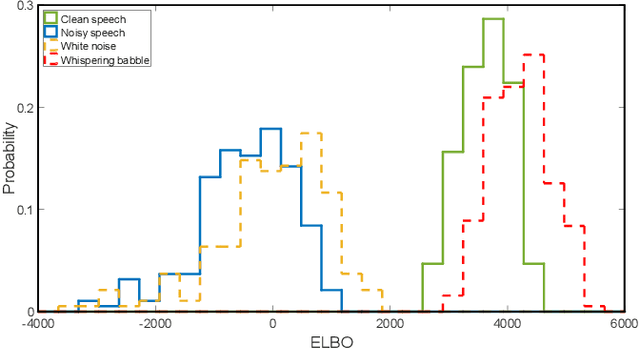
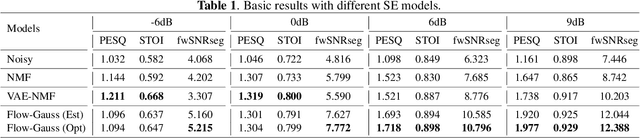
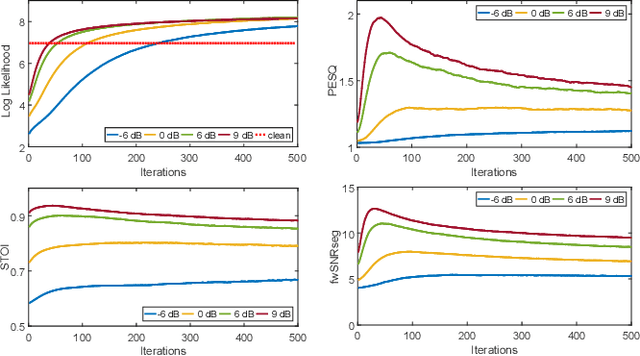
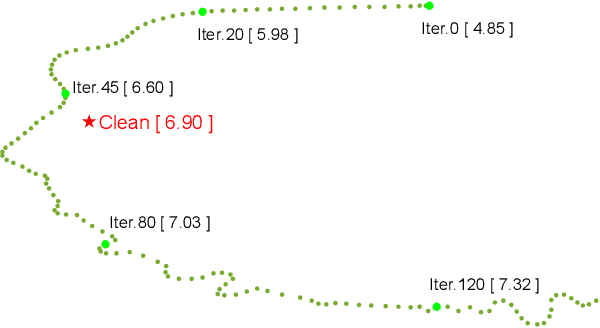
Recently, speech enhancement (SE) based on deep speech prior has attracted much attention, such as the variational auto-encoder with non-negative matrix factorization (VAE-NMF) architecture. Compared to conventional approaches that represent clean speech by shallow models such as Gaussians with a low-rank covariance, the new approach employs deep generative models to represent the clean speech, which often provides a better prior. Despite the clear advantage in theory, we argue that deep priors must be used with much caution, since the likelihood produced by a deep generative model does not always coincide with the speech quality. We designed a comprehensive study on this issue and demonstrated that based on deep speech priors, a reasonable SE performance can be achieved, but the results might be suboptimal. A careful analysis showed that this problem is deeply rooted in the disharmony between the flexibility of deep generative models and the nature of the maximum-likelihood (ML) training.
Discriminative Embedding Autoencoder with a Regressor Feedback for Zero-Shot Learning
Jul 18, 2019

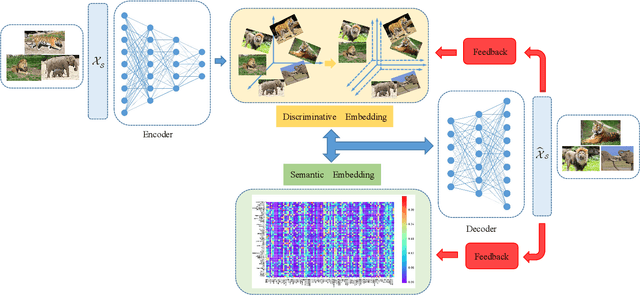
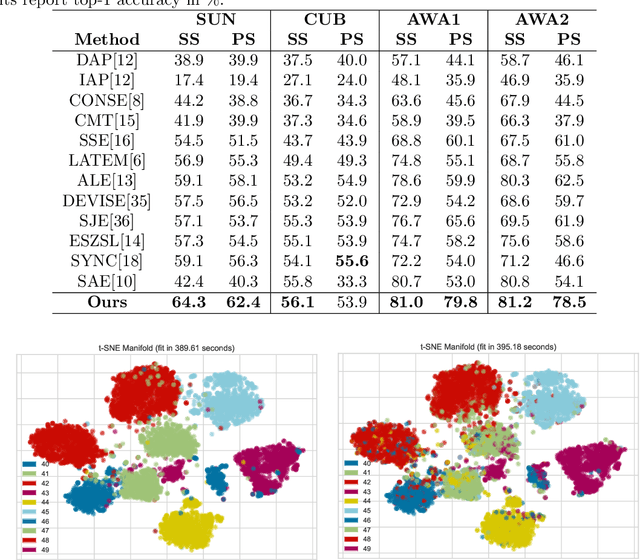
Zero-shot learning (ZSL) aims to recognize the novel object categories using the semantic representation of categories, and the key idea is to explore the knowledge of how the novel class is semantically related to the familiar classes. Some typical models are to learn the proper embedding between the image feature space and the semantic space, whilst it is important to learn discriminative features and comprise the coarse-to-fine image feature and semantic information. In this paper, we propose a discriminative embedding autoencoder with a regressor feedback model for ZSL. The encoder learns a mapping from the image feature space to the discriminative embedding space, which regulates both inter-class and intra-class distances between the learned features by a margin, making the learned features be discriminative for object recognition. The regressor feedback learns to map the reconstructed samples back to the the discriminative embedding and the semantic embedding, assisting the decoder to improve the quality of the samples and provide a generalization to the unseen classes. The proposed model is validated extensively on four benchmark datasets: SUN, CUB, AWA1, AWA2, the experiment results show that our proposed model outperforms the state-of-the-art models, and especially in the generalized zero-shot learning (GZSL), significant improvements are achieved.
Gaussian-Constrained training for speaker verification
Nov 08, 2018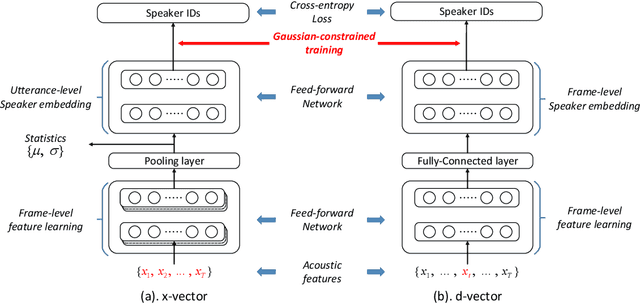
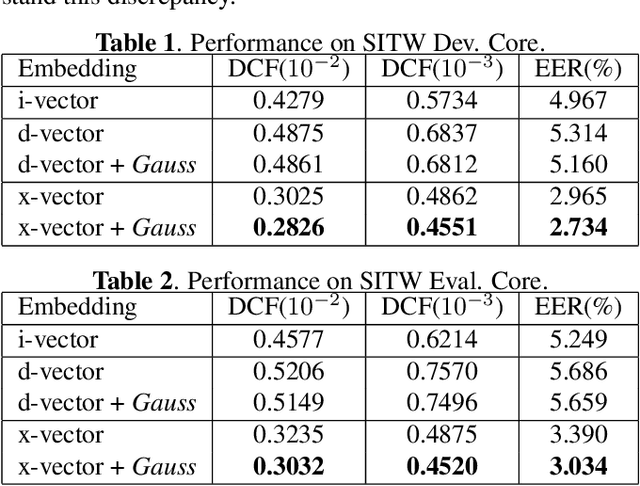
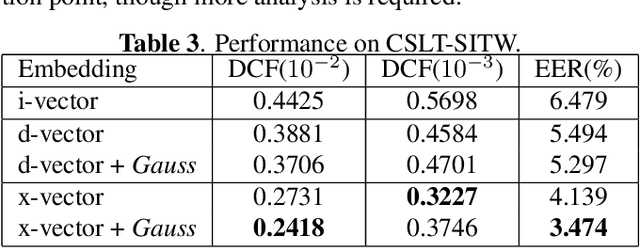
Neural models, in particular the d-vector and x-vector architectures, have produced state-of-the-art performance on many speaker verification tasks. However, two potential problems of these neural models deserve more investigation. Firstly, both models suffer from `information leak', which means that some parameters participating in model training will be discarded during inference, i.e, the layers that are used as the classifier. Secondly, both models do not regulate the distribution of the derived speaker vectors. This `unconstrained distribution' may degrade the performance of the subsequent scoring component, e.g., PLDA. This paper proposes a Gaussian-constrained training approach that (1) discards the parametric classifier, and (2) enforces the distribution of the derived speaker vectors to be Gaussian. Our experiments on the VoxCeleb and SITW databases demonstrated that this new training approach produced more representative and regular speaker embeddings, leading to consistent performance improvement.
Phonetic-attention scoring for deep speaker features in speaker verification
Nov 08, 2018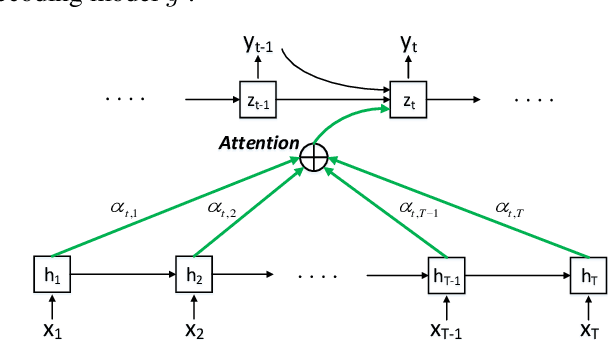

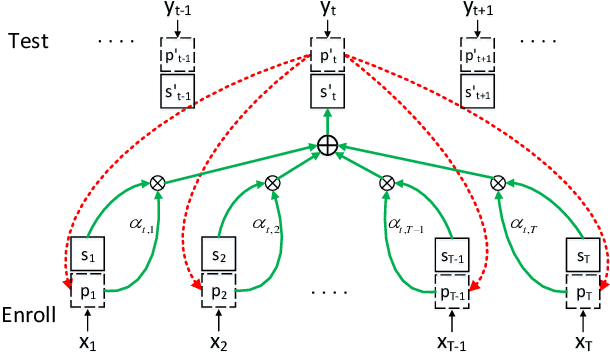

Recent studies have shown that frame-level deep speaker features can be derived from a deep neural network with the training target set to discriminate speakers by a short speech segment. By pooling the frame-level features, utterance-level representations, called d-vectors, can be derived and used in the automatic speaker verification (ASV) task. This simple average pooling, however, is inherently sensitive to the phonetic content of the utterance. An interesting idea borrowed from machine translation is the attention-based mechanism, where the contribution of an input word to the translation at a particular time is weighted by an attention score. This score reflects the relevance of the input word and the present translation. We can use the same idea to align utterances with different phonetic contents. This paper proposes a phonetic-attention scoring approach for d-vector systems. By this approach, an attention score is computed for each frame pair. This score reflects the similarity of the two frames in phonetic content, and is used to weigh the contribution of this frame pair in the utterance-based scoring. This new scoring approach emphasizes the frame pairs with similar phonetic contents, which essentially provides a soft alignment for utterances with any phonetic contents. Experimental results show that compared with the naive average pooling, this phonetic-attention scoring approach can deliver consistent performance improvement in ASV tasks of both text-dependent and text-independent.
Deep factorization for speech signal
Feb 27, 2018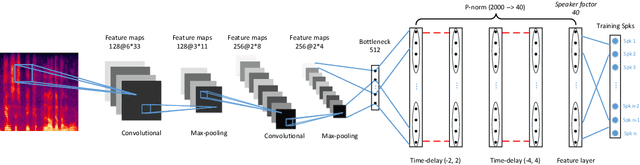
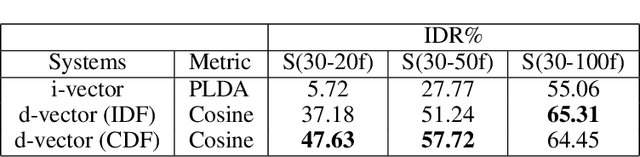
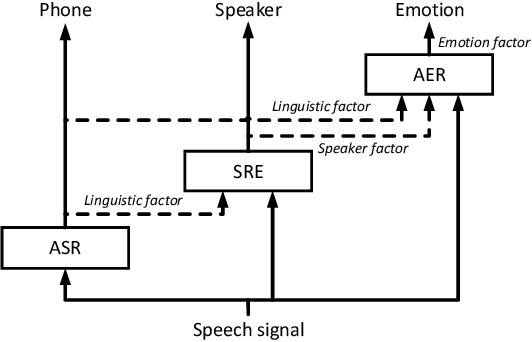
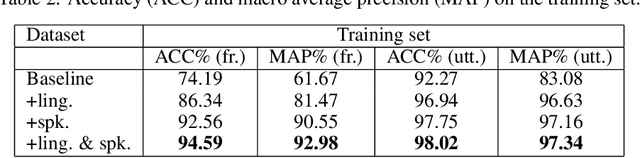
Various informative factors mixed in speech signals, leading to great difficulty when decoding any of the factors. An intuitive idea is to factorize each speech frame into individual informative factors, though it turns out to be highly difficult. Recently, we found that speaker traits, which were assumed to be long-term distributional properties, are actually short-time patterns, and can be learned by a carefully designed deep neural network (DNN). This discovery motivated a cascade deep factorization (CDF) framework that will be presented in this paper. The proposed framework infers speech factors in a sequential way, where factors previously inferred are used as conditional variables when inferring other factors. We will show that this approach can effectively factorize speech signals, and using these factors, the original speech spectrum can be recovered with a high accuracy. This factorization and reconstruction approach provides potential values for many speech processing tasks, e.g., speaker recognition and emotion recognition, as will be demonstrated in the paper.
Deep Factorization for Speech Signal
Jun 25, 2017Speech signals are complex intermingling of various informative factors, and this information blending makes decoding any of the individual factors extremely difficult. A natural idea is to factorize each speech frame into independent factors, though it turns out to be even more difficult than decoding each individual factor. A major encumbrance is that the speaker trait, a major factor in speech signals, has been suspected to be a long-term distributional pattern and so not identifiable at the frame level. In this paper, we demonstrated that the speaker factor is also a short-time spectral pattern and can be largely identified with just a few frames using a simple deep neural network (DNN). This discovery motivated a cascade deep factorization (CDF) framework that infers speech factors in a sequential way, and factors previously inferred are used as conditional variables when inferring other factors. Our experiment on an automatic emotion recognition (AER) task demonstrated that this approach can effectively factorize speech signals, and using these factors, the original speech spectrum can be recovered with high accuracy. This factorization and reconstruction approach provides a novel tool for many speech processing tasks.