 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSerialized Output Training by Learned Dominance
Jul 04, 2024Serialized Output Training (SOT) has showcased state-of-the-art performance in multi-talker speech recognition by sequentially decoding the speech of individual speakers. To address the challenging label-permutation issue, prior methods have relied on either the Permutation Invariant Training (PIT) or the time-based First-In-First-Out (FIFO) rule. This study presents a model-based serialization strategy that incorporates an auxiliary module into the Attention Encoder-Decoder architecture, autonomously identifying the crucial factors to order the output sequence of the speech components in multi-talker speech. Experiments conducted on the LibriSpeech and LibriMix databases reveal that our approach significantly outperforms the PIT and FIFO baselines in both 2-mix and 3-mix scenarios. Further analysis shows that the serialization module identifies dominant speech components in a mixture by factors including loudness and gender, and orders speech components based on the dominance score.
Contrastive Loss Based Frame-wise Feature disentanglement for Polyphonic Sound Event Detection
Jan 11, 2024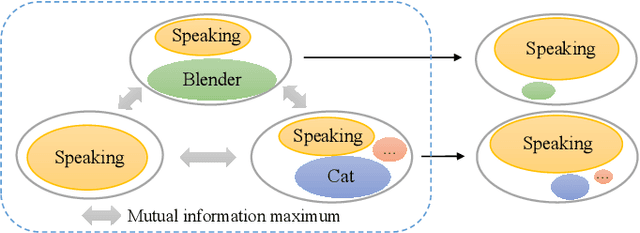
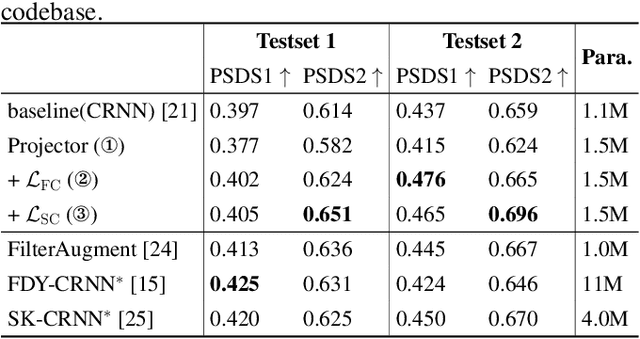
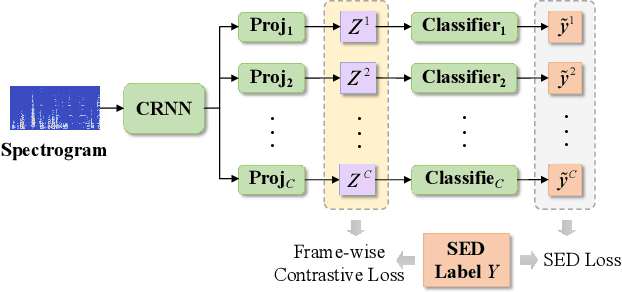
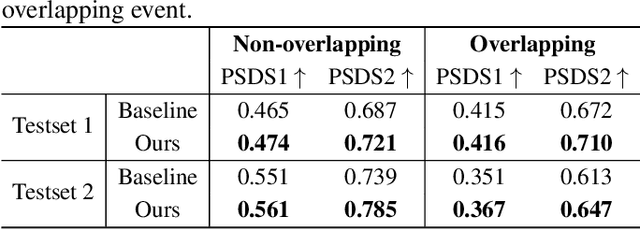
Overlapping sound events are ubiquitous in real-world environments, but existing end-to-end sound event detection (SED) methods still struggle to detect them effectively. A critical reason is that these methods represent overlapping events using shared and entangled frame-wise features, which degrades the feature discrimination. To solve the problem, we propose a disentangled feature learning framework to learn a category-specific representation. Specifically, we employ different projectors to learn the frame-wise features for each category. To ensure that these feature does not contain information of other categories, we maximize the common information between frame-wise features within the same category and propose a frame-wise contrastive loss. In addition, considering that the labeled data used by the proposed method is limited, we propose a semi-supervised frame-wise contrastive loss that can leverage large amounts of unlabeled data to achieve feature disentanglement. The experimental results demonstrate the effectiveness of our method.
A Glance is Enough: Extract Target Sentence By Looking at A keyword
Oct 09, 2023This paper investigates the possibility of extracting a target sentence from multi-talker speech using only a keyword as input. For example, in social security applications, the keyword might be "help", and the goal is to identify what the person who called for help is articulating while ignoring other speakers. To address this problem, we propose using the Transformer architecture to embed both the keyword and the speech utterance and then rely on the cross-attention mechanism to select the correct content from the concatenated or overlapping speech. Experimental results on Librispeech demonstrate that our proposed method can effectively extract target sentences from very noisy and mixed speech (SNR=-3dB), achieving a phone error rate (PER) of 26\%, compared to the baseline system's PER of 96%.
Spot keywords from very noisy and mixed speech
May 28, 2023Most existing keyword spotting research focuses on conditions with slight or moderate noise. In this paper, we try to tackle a more challenging task: detecting keywords buried under strong interfering speech (10 times higher than the keyword in amplitude), and even worse, mixed with other keywords. We propose a novel Mix Training (MT) strategy that encourages the model to discover low-energy keywords from noisy and mixed speech. Experiments were conducted with a vanilla CNN and two EfficientNet (B0/B2) architectures. The results evaluated with the Google Speech Command dataset demonstrated that the proposed mix training approach is highly effective and outperforms standard data augmentation and mixup training.
Time-weighted Frequency Domain Audio Representation with GMM Estimator for Anomalous Sound Detection
May 05, 2023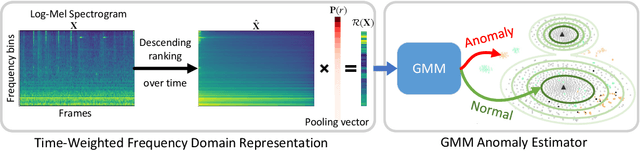
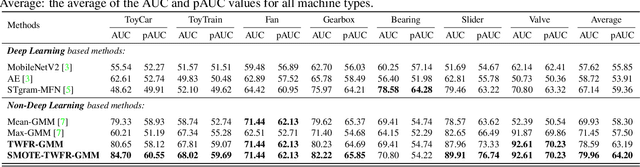
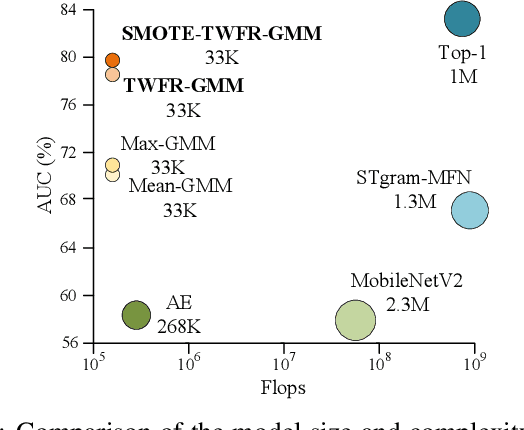
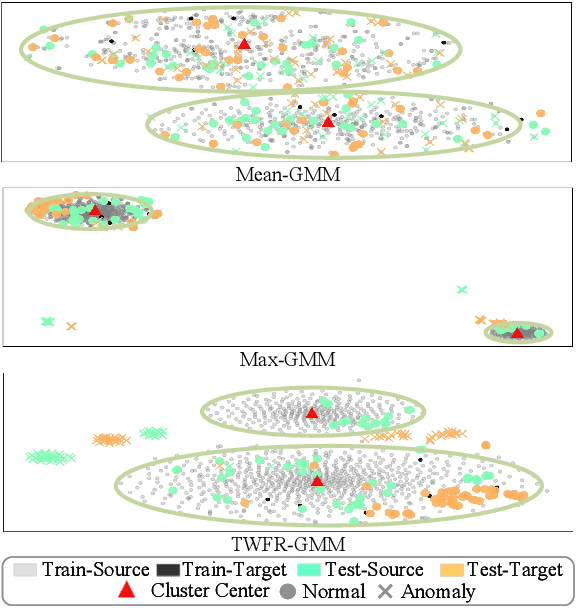
Although deep learning is the mainstream method in unsupervised anomalous sound detection, Gaussian Mixture Model (GMM) with statistical audio frequency representation as input can achieve comparable results with much lower model complexity and fewer parameters. Existing statistical frequency representations, e.g, the log-Mel spectrogram's average or maximum over time, do not always work well for different machines. This paper presents Time-Weighted Frequency Domain Representation (TWFR) with the GMM method (TWFR-GMM) for anomalous sound detection. The TWFR is a generalized statistical frequency domain representation that can adapt to different machine types, using the global weighted ranking pooling over time-domain. This allows GMM estimator to recognize anomalies, even under domain-shift conditions, as visualized with a Mahalanobis distance-based metric. Experiments on DCASE 2022 Challenge Task2 dataset show that our method has better detection performance than recent deep learning methods. TWFR-GMM is the core of our submission that achieved the 3rd place in DCASE 2022 Challenge Task2.
Using Auxiliary Tasks In Multimodal Fusion Of Wav2vec 2.0 And BERT For Multimodal Emotion Recognition
Feb 27, 2023The lack of data and the difficulty of multimodal fusion have always been challenges for multimodal emotion recognition (MER). In this paper, we propose to use pretrained models as upstream network, wav2vec 2.0 for audio modality and BERT for text modality, and finetune them in downstream task of MER to cope with the lack of data. For the difficulty of multimodal fusion, we use a K-layer multi-head attention mechanism as a downstream fusion module. Starting from the MER task itself, we design two auxiliary tasks to alleviate the insufficient fusion between modalities and guide the network to capture and align emotion-related features. Compared to the previous state-of-the-art models, we achieve a better performance by 78.42% Weighted Accuracy (WA) and 79.71% Unweighted Accuracy (UA) on the IEMOCAP dataset.
Contrastive Regularization for Multimodal Emotion Recognition Using Audio and Text
Nov 20, 2022Speech emotion recognition is a challenge and an important step towards more natural human-computer interaction (HCI). The popular approach is multimodal emotion recognition based on model-level fusion, which means that the multimodal signals can be encoded to acquire embeddings, and then the embeddings are concatenated together for the final classification. However, due to the influence of noise or other factors, each modality does not always tend to the same emotional category, which affects the generalization of a model. In this paper, we propose a novel regularization method via contrastive learning for multimodal emotion recognition using audio and text. By introducing a discriminator to distinguish the difference between the same and different emotional pairs, we explicitly restrict the latent code of each modality to contain the same emotional information, so as to reduce the noise interference and get more discriminative representation. Experiments are performed on the standard IEMOCAP dataset for 4-class emotion recognition. The results show a significant improvement of 1.44\% and 1.53\% in terms of weighted accuracy (WA) and unweighted accuracy (UA) compared to the baseline system.
Exploring Transformer's potential on automatic piano transcription
Apr 08, 2022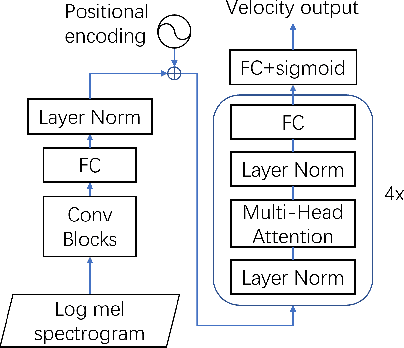

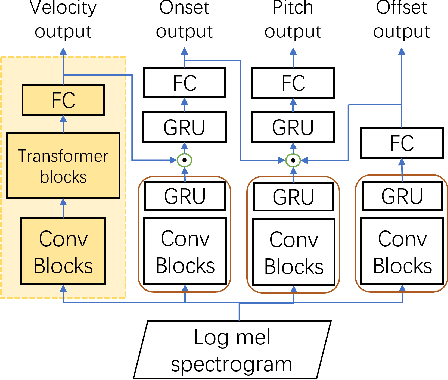
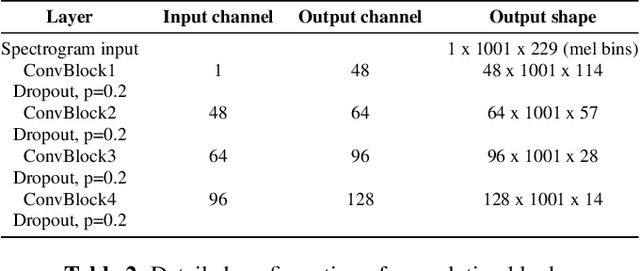
Most recent research about automatic music transcription (AMT) uses convolutional neural networks and recurrent neural networks to model the mapping from music signals to symbolic notation. Based on a high-resolution piano transcription system, we explore the possibility of incorporating another powerful sequence transformation tool -- the Transformer -- to deal with the AMT problem. We argue that the properties of the Transformer make it more suitable for certain AMT subtasks. We confirm the Transformer's superiority on the velocity detection task by experiments on the MAESTRO dataset and a cross-dataset evaluation on the MAPS dataset. We observe a performance improvement on both frame-level and note-level metrics after introducing the Transformer network.
Can We Trust Deep Speech Prior?
Nov 04, 2020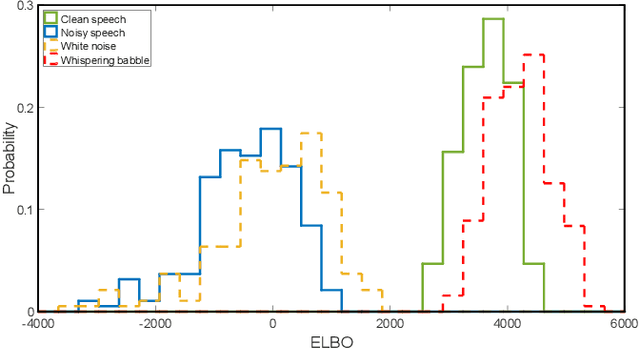
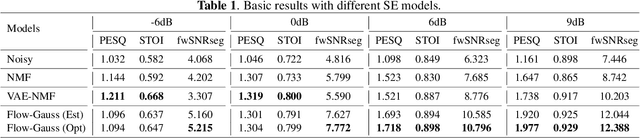
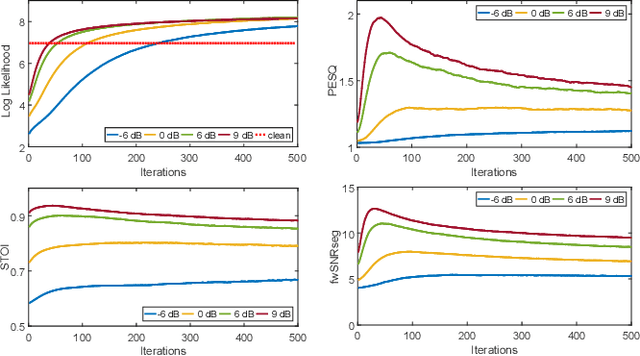
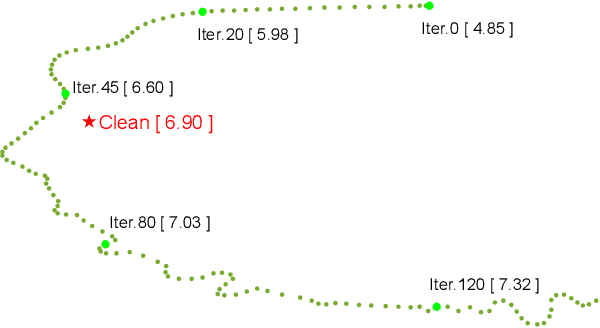
Recently, speech enhancement (SE) based on deep speech prior has attracted much attention, such as the variational auto-encoder with non-negative matrix factorization (VAE-NMF) architecture. Compared to conventional approaches that represent clean speech by shallow models such as Gaussians with a low-rank covariance, the new approach employs deep generative models to represent the clean speech, which often provides a better prior. Despite the clear advantage in theory, we argue that deep priors must be used with much caution, since the likelihood produced by a deep generative model does not always coincide with the speech quality. We designed a comprehensive study on this issue and demonstrated that based on deep speech priors, a reasonable SE performance can be achieved, but the results might be suboptimal. A careful analysis showed that this problem is deeply rooted in the disharmony between the flexibility of deep generative models and the nature of the maximum-likelihood (ML) training.
Acoustic Scene Classification by Implicitly Identifying Distinct Sound Events
Apr 27, 2019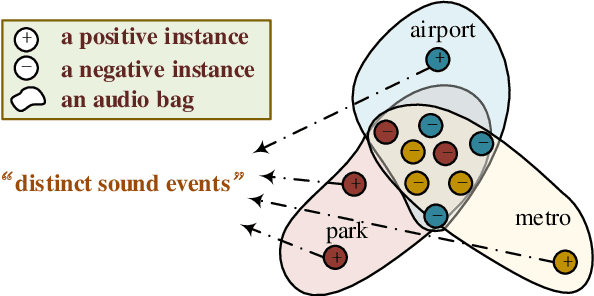

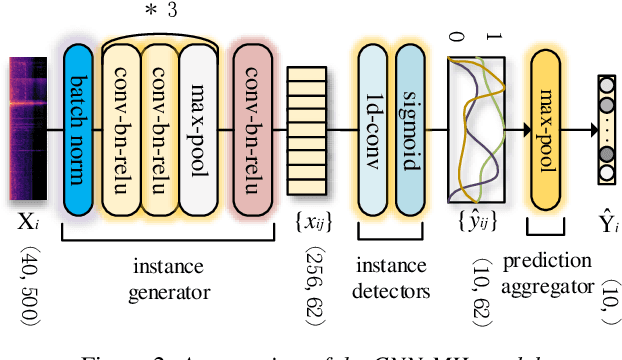
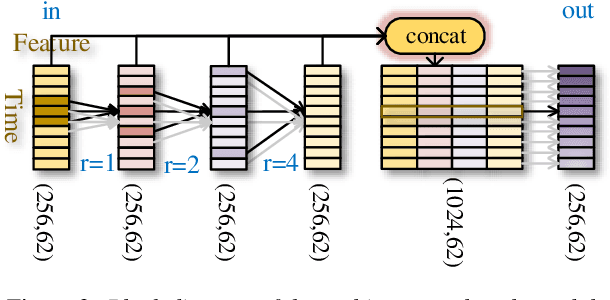
In this paper, we propose a new strategy for acoustic scene classification (ASC) , namely recognizing acoustic scenes through identifying distinct sound events. This differs from existing strategies, which focus on characterizing global acoustical distributions of audio or the temporal evolution of short-term audio features, without analysis down to the level of sound events. To identify distinct sound events for each scene, we formulate ASC in a multi-instance learning (MIL) framework, where each audio recording is mapped into a bag-of-instances representation. Here, instances can be seen as high-level representations for sound events inside a scene. We also propose a MIL neural networks model, which implicitly identifies distinct instances (i.e., sound events). Furthermore, we propose two specially designed modules that model the multi-temporal scale and multi-modal natures of the sound events respectively. The experiments were conducted on the official development set of the DCASE2018 Task1 Subtask B, and our best-performing model improves over the official baseline by 9.4% (68.3% vs 58.9%) in terms of classification accuracy. This study indicates that recognizing acoustic scenes by identifying distinct sound events is effective and paves the way for future studies that combine this strategy with previous ones.