 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic Scene Classification by Implicitly Identifying Distinct Sound Events
Apr 27, 2019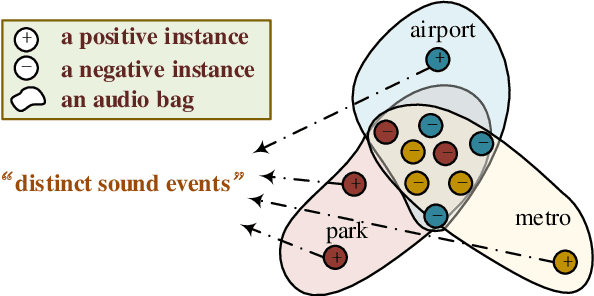

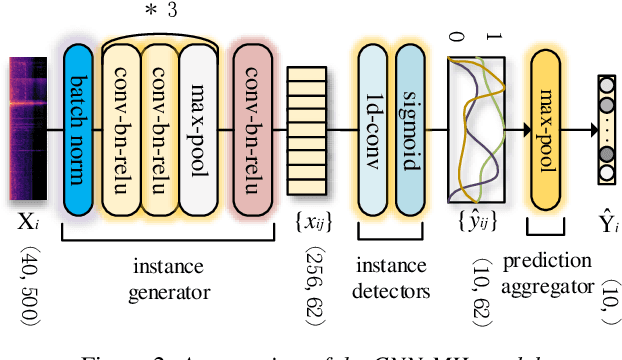
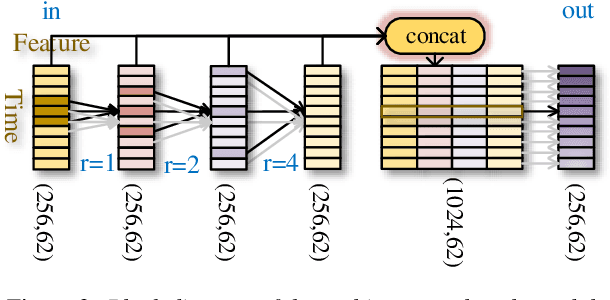
In this paper, we propose a new strategy for acoustic scene classification (ASC) , namely recognizing acoustic scenes through identifying distinct sound events. This differs from existing strategies, which focus on characterizing global acoustical distributions of audio or the temporal evolution of short-term audio features, without analysis down to the level of sound events. To identify distinct sound events for each scene, we formulate ASC in a multi-instance learning (MIL) framework, where each audio recording is mapped into a bag-of-instances representation. Here, instances can be seen as high-level representations for sound events inside a scene. We also propose a MIL neural networks model, which implicitly identifies distinct instances (i.e., sound events). Furthermore, we propose two specially designed modules that model the multi-temporal scale and multi-modal natures of the sound events respectively. The experiments were conducted on the official development set of the DCASE2018 Task1 Subtask B, and our best-performing model improves over the official baseline by 9.4% (68.3% vs 58.9%) in terms of classification accuracy. This study indicates that recognizing acoustic scenes by identifying distinct sound events is effective and paves the way for future studies that combine this strategy with previous ones.
Guarantees of Augmented Trace Norm Models in Tensor Recovery
Jul 23, 2012
This paper studies the recovery guarantees of the models of minimizing $\|\mathcal{X}\|_*+\frac{1}{2\alpha}\|\mathcal{X}\|_F^2$ where $\mathcal{X}$ is a tensor and $\|\mathcal{X}\|_*$ and $\|\mathcal{X}\|_F$ are the trace and Frobenius norm of respectively. We show that they can efficiently recover low-rank tensors. In particular, they enjoy exact guarantees similar to those known for minimizing $\|\mathcal{X}\|_*$ under the conditions on the sensing operator such as its null-space property, restricted isometry property, or spherical section property. To recover a low-rank tensor $\mathcal{X}^0$, minimizing $\|\mathcal{X}\|_*+\frac{1}{2\alpha}\|\mathcal{X}\|_F^2$ returns the same solution as minimizing $\|\mathcal{X}\|_*$ almost whenever $\alpha\geq10\mathop {\max}\limits_{i}\|X^0_{(i)}\|_2$.
Online Learning for Classification of Low-rank Representation Features and Its Applications in Audio Segment Classification
Dec 19, 2011


In this paper, a novel framework based on trace norm minimization for audio segment is proposed. In this framework, both the feature extraction and classification are obtained by solving corresponding convex optimization problem with trace norm regularization. For feature extraction, robust principle component analysis (robust PCA) via minimization a combination of the nuclear norm and the $\ell_1$-norm is used to extract low-rank features which are robust to white noise and gross corruption for audio segments. These low-rank features are fed to a linear classifier where the weight and bias are learned by solving similar trace norm constrained problems. For this classifier, most methods find the weight and bias in batch-mode learning, which makes them inefficient for large-scale problems. In this paper, we propose an online framework using accelerated proximal gradient method. This framework has a main advantage in memory cost. In addition, as a result of the regularization formulation of matrix classification, the Lipschitz constant was given explicitly, and hence the step size estimation of general proximal gradient method was omitted in our approach. Experiments on real data sets for laugh/non-laugh and applause/non-applause classification indicate that this novel framework is effective and noise robust.