 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReLayout: Versatile and Structure-Preserving Design Layout Editing via Relation-Aware Design Reconstruction
Feb 01, 2026Automated redesign without manual adjustments marks a key step forward in the design workflow. In this work, we focus on a foundational redesign task termed design layout editing, which seeks to autonomously modify the geometric composition of a design based on user intents. To overcome the ambiguity of user needs expressed in natural language, we introduce four basic and important editing actions and standardize the format of editing operations. The underexplored task presents a unique challenge: satisfying specified editing operations while simultaneously preserving the layout structure of unedited elements. Besides, the scarcity of triplet (original design, editing operation, edited design) samples poses another formidable challenge. To this end, we present ReLayout, a novel framework for versatile and structure-preserving design layout editing that operates without triplet data. Specifically, ReLayout first introduces the relation graph, which contains the position and size relationships among unedited elements, as the constraint for layout structure preservation. Then, relation-aware design reconstruction (RADR) is proposed to bypass the data challenge. By learning to reconstruct a design from its elements, a relation graph, and a synthesized editing operation, RADR effectively emulates the editing process in a self-supervised manner. A multi-modal large language model serves as the backbone for RADR, unifying multiple editing actions within a single model and thus achieving versatile editing after fine-tuning. Qualitative, quantitative results and user studies show that ReLayout significantly outperforms the baseline models in terms of editing quality, accuracy, and layout structure preservation.
Multi-Agent Deep Research: Training Multi-Agent Systems with M-GRPO
Nov 18, 2025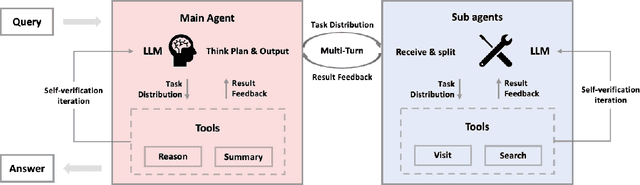
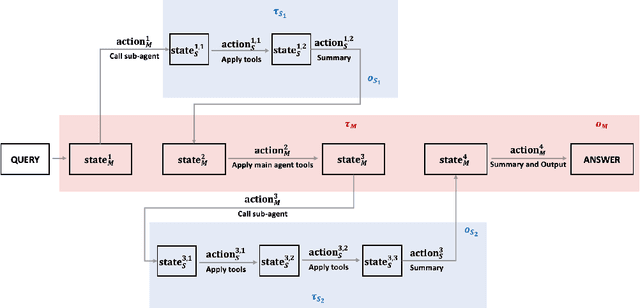
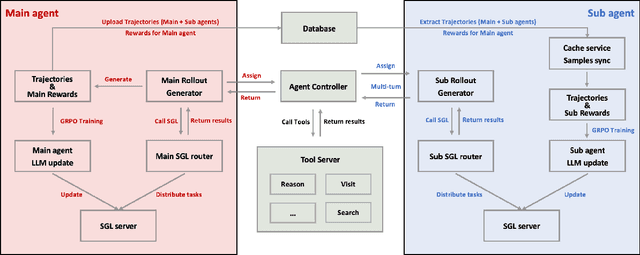
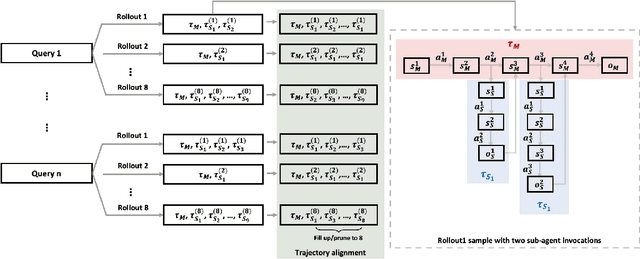
Multi-agent systems perform well on general reasoning tasks. However, the lack of training in specialized areas hinders their accuracy. Current training methods train a unified large language model (LLM) for all agents in the system. This may limit the performances due to different distributions underlying for different agents. Therefore, training multi-agent systems with distinct LLMs should be the next step to solve. However, this approach introduces optimization challenges. For example, agents operate at different frequencies, rollouts involve varying sub-agent invocations, and agents are often deployed across separate servers, disrupting end-to-end gradient flow. To address these issues, we propose M-GRPO, a hierarchical extension of Group Relative Policy Optimization designed for vertical Multi-agent systems with a main agent (planner) and multiple sub-agents (multi-turn tool executors). M-GRPO computes group-relative advantages for both main and sub-agents, maintaining hierarchical credit assignment. It also introduces a trajectory-alignment scheme that generates fixed-size batches despite variable sub-agent invocations. We deploy a decoupled training pipeline in which agents run on separate servers and exchange minimal statistics via a shared store. This enables scalable training without cross-server backpropagation. In experiments on real-world benchmarks (e.g., GAIA, XBench-DeepSearch, and WebWalkerQA), M-GRPO consistently outperforms both single-agent GRPO and multi-agent GRPO with frozen sub-agents, demonstrating improved stability and sample efficiency. These results show that aligning heterogeneous trajectories and decoupling optimization across specialized agents enhances tool-augmented reasoning tasks.
Image Restoration via Primal Dual Hybrid Gradient and Flow Generative Model
Nov 10, 2025Regularized optimization has been a classical approach to solving imaging inverse problems, where the regularization term enforces desirable properties of the unknown image. Recently, the integration of flow matching generative models into image restoration has garnered significant attention, owing to their powerful prior modeling capabilities. In this work, we incorporate such generative priors into a Plug-and-Play (PnP) framework based on proximal splitting, where the proximal operator associated with the regularizer is replaced by a time-dependent denoiser derived from the generative model. While existing PnP methods have achieved notable success in inverse problems with smooth squared $\ell_2$ data fidelity--typically associated with Gaussian noise--their applicability to more general data fidelity terms remains underexplored. To address this, we propose a general and efficient PnP algorithm inspired by the primal-dual hybrid gradient (PDHG) method. Our approach is computationally efficient, memory-friendly, and accommodates a wide range of fidelity terms. In particular, it supports both $\ell_1$ and $\ell_2$ norm-based losses, enabling robustness to non-Gaussian noise types such as Poisson and impulse noise. We validate our method on several image restoration tasks, including denoising, super-resolution, deblurring, and inpainting, and demonstrate that $\ell_1$ and $\ell_2$ fidelity terms outperform the conventional squared $\ell_2$ loss in the presence of non-Gaussian noise.
Integrating Reweighted Least Squares with Plug-and-Play Diffusion Priors for Noisy Image Restoration
Nov 10, 2025Existing plug-and-play image restoration methods typically employ off-the-shelf Gaussian denoisers as proximal operators within classical optimization frameworks based on variable splitting. Recently, denoisers induced by generative priors have been successfully integrated into regularized optimization methods for image restoration under Gaussian noise. However, their application to non-Gaussian noise--such as impulse noise--remains largely unexplored. In this paper, we propose a plug-and-play image restoration framework based on generative diffusion priors for robust removal of general noise types, including impulse noise. Within the maximum a posteriori (MAP) estimation framework, the data fidelity term is adapted to the specific noise model. Departing from the conventional least-squares loss used for Gaussian noise, we introduce a generalized Gaussian scale mixture-based loss, which approximates a wide range of noise distributions and leads to an $\ell_q$-norm ($0<q\leq2$) fidelity term. This optimization problem is addressed using an iteratively reweighted least squares (IRLS) approach, wherein the proximal step involving the generative prior is efficiently performed via a diffusion-based denoiser. Experimental results on benchmark datasets demonstrate that the proposed method effectively removes non-Gaussian impulse noise and achieves superior restoration performance.
MedReseacher-R1: Expert-Level Medical Deep Researcher via A Knowledge-Informed Trajectory Synthesis Framework
Aug 20, 2025Recent developments in Large Language Model (LLM)-based agents have shown impressive capabilities spanning multiple domains, exemplified by deep research systems that demonstrate superior performance on complex information-seeking and synthesis tasks. While general-purpose deep research agents have shown impressive capabilities, they struggle significantly with medical domain challenges, as evidenced by leading proprietary systems achieving limited accuracy on complex medical benchmarks. The key limitations are: (1) the model lacks sufficient dense medical knowledge for clinical reasoning, and (2) the framework is constrained by the absence of specialized retrieval tools tailored for medical contexts.We present a medical deep research agent that addresses these challenges through two core innovations. First, we develop a novel data synthesis framework using medical knowledge graphs, extracting the longest chains from subgraphs around rare medical entities to generate complex multi-hop question-answer pairs. Second, we integrate a custom-built private medical retrieval engine alongside general-purpose tools, enabling accurate medical information synthesis. Our approach generates 2100+ diverse trajectories across 12 medical specialties, each averaging 4.2 tool interactions.Through a two-stage training paradigm combining supervised fine-tuning and online reinforcement learning with composite rewards, our MedResearcher-R1-32B model demonstrates exceptional performance, establishing new state-of-the-art results on medical benchmarks while maintaining competitive performance on general deep research tasks. Our work demonstrates that strategic domain-specific innovations in architecture, tool design, and training data construction can enable smaller open-source models to outperform much larger proprietary systems in specialized domains.
Learning to Align, Aligning to Learn: A Unified Approach for Self-Optimized Alignment
Aug 11, 2025



Alignment methodologies have emerged as a critical pathway for enhancing language model alignment capabilities. While SFT (supervised fine-tuning) accelerates convergence through direct token-level loss intervention, its efficacy is constrained by offline policy trajectory. In contrast, RL(reinforcement learning) facilitates exploratory policy optimization, but suffers from low sample efficiency and stringent dependency on high-quality base models. To address these dual challenges, we propose GRAO (Group Relative Alignment Optimization), a unified framework that synergizes the respective strengths of SFT and RL through three key innovations: 1) A multi-sample generation strategy enabling comparative quality assessment via reward feedback; 2) A novel Group Direct Alignment Loss formulation leveraging intra-group relative advantage weighting; 3) Reference-aware parameter updates guided by pairwise preference dynamics. Our theoretical analysis establishes GRAO's convergence guarantees and sample efficiency advantages over conventional approaches. Comprehensive evaluations across complex human alignment tasks demonstrate GRAO's superior performance, achieving 57.70\%,17.65\% 7.95\% and 5.18\% relative improvements over SFT, DPO, PPO and GRPO baselines respectively. This work provides both a theoretically grounded alignment framework and empirical evidence for efficient capability evolution in language models.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
MMMG: A Massive, Multidisciplinary, Multi-Tier Generation Benchmark for Text-to-Image Reasoning
Jun 12, 2025In this paper, we introduce knowledge image generation as a new task, alongside the Massive Multi-Discipline Multi-Tier Knowledge-Image Generation Benchmark (MMMG) to probe the reasoning capability of image generation models. Knowledge images have been central to human civilization and to the mechanisms of human learning--a fact underscored by dual-coding theory and the picture-superiority effect. Generating such images is challenging, demanding multimodal reasoning that fuses world knowledge with pixel-level grounding into clear explanatory visuals. To enable comprehensive evaluation, MMMG offers 4,456 expert-validated (knowledge) image-prompt pairs spanning 10 disciplines, 6 educational levels, and diverse knowledge formats such as charts, diagrams, and mind maps. To eliminate confounding complexity during evaluation, we adopt a unified Knowledge Graph (KG) representation. Each KG explicitly delineates a target image's core entities and their dependencies. We further introduce MMMG-Score to evaluate generated knowledge images. This metric combines factual fidelity, measured by graph-edit distance between KGs, with visual clarity assessment. Comprehensive evaluations of 16 state-of-the-art text-to-image generation models expose serious reasoning deficits--low entity fidelity, weak relations, and clutter--with GPT-4o achieving an MMMG-Score of only 50.20, underscoring the benchmark's difficulty. To spur further progress, we release FLUX-Reason (MMMG-Score of 34.45), an effective and open baseline that combines a reasoning LLM with diffusion models and is trained on 16,000 curated knowledge image-prompt pairs.
PrismLayers: Open Data for High-Quality Multi-Layer Transparent Image Generative Models
May 28, 2025Generating high-quality, multi-layer transparent images from text prompts can unlock a new level of creative control, allowing users to edit each layer as effortlessly as editing text outputs from LLMs. However, the development of multi-layer generative models lags behind that of conventional text-to-image models due to the absence of a large, high-quality corpus of multi-layer transparent data. In this paper, we address this fundamental challenge by: (i) releasing the first open, ultra-high-fidelity PrismLayers (PrismLayersPro) dataset of 200K (20K) multilayer transparent images with accurate alpha mattes, (ii) introducing a trainingfree synthesis pipeline that generates such data on demand using off-the-shelf diffusion models, and (iii) delivering a strong, open-source multi-layer generation model, ART+, which matches the aesthetics of modern text-to-image generation models. The key technical contributions include: LayerFLUX, which excels at generating high-quality single transparent layers with accurate alpha mattes, and MultiLayerFLUX, which composes multiple LayerFLUX outputs into complete images, guided by human-annotated semantic layout. To ensure higher quality, we apply a rigorous filtering stage to remove artifacts and semantic mismatches, followed by human selection. Fine-tuning the state-of-the-art ART model on our synthetic PrismLayersPro yields ART+, which outperforms the original ART in 60% of head-to-head user study comparisons and even matches the visual quality of images generated by the FLUX.1-[dev] model. We anticipate that our work will establish a solid dataset foundation for the multi-layer transparent image generation task, enabling research and applications that require precise, editable, and visually compelling layered imagery.
BizGen: Advancing Article-level Visual Text Rendering for Infographics Generation
Mar 26, 2025Recently, state-of-the-art text-to-image generation models, such as Flux and Ideogram 2.0, have made significant progress in sentence-level visual text rendering. In this paper, we focus on the more challenging scenarios of article-level visual text rendering and address a novel task of generating high-quality business content, including infographics and slides, based on user provided article-level descriptive prompts and ultra-dense layouts. The fundamental challenges are twofold: significantly longer context lengths and the scarcity of high-quality business content data. In contrast to most previous works that focus on a limited number of sub-regions and sentence-level prompts, ensuring precise adherence to ultra-dense layouts with tens or even hundreds of sub-regions in business content is far more challenging. We make two key technical contributions: (i) the construction of scalable, high-quality business content dataset, i.e., Infographics-650K, equipped with ultra-dense layouts and prompts by implementing a layer-wise retrieval-augmented infographic generation scheme; and (ii) a layout-guided cross attention scheme, which injects tens of region-wise prompts into a set of cropped region latent space according to the ultra-dense layouts, and refine each sub-regions flexibly during inference using a layout conditional CFG. We demonstrate the strong results of our system compared to previous SOTA systems such as Flux and SD3 on our BizEval prompt set. Additionally, we conduct thorough ablation experiments to verify the effectiveness of each component. We hope our constructed Infographics-650K and BizEval can encourage the broader community to advance the progress of business content generation.