 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Align, Aligning to Learn: A Unified Approach for Self-Optimized Alignment
Aug 11, 2025



Alignment methodologies have emerged as a critical pathway for enhancing language model alignment capabilities. While SFT (supervised fine-tuning) accelerates convergence through direct token-level loss intervention, its efficacy is constrained by offline policy trajectory. In contrast, RL(reinforcement learning) facilitates exploratory policy optimization, but suffers from low sample efficiency and stringent dependency on high-quality base models. To address these dual challenges, we propose GRAO (Group Relative Alignment Optimization), a unified framework that synergizes the respective strengths of SFT and RL through three key innovations: 1) A multi-sample generation strategy enabling comparative quality assessment via reward feedback; 2) A novel Group Direct Alignment Loss formulation leveraging intra-group relative advantage weighting; 3) Reference-aware parameter updates guided by pairwise preference dynamics. Our theoretical analysis establishes GRAO's convergence guarantees and sample efficiency advantages over conventional approaches. Comprehensive evaluations across complex human alignment tasks demonstrate GRAO's superior performance, achieving 57.70\%,17.65\% 7.95\% and 5.18\% relative improvements over SFT, DPO, PPO and GRPO baselines respectively. This work provides both a theoretically grounded alignment framework and empirical evidence for efficient capability evolution in language models.
EDiT: A Local-SGD-Based Efficient Distributed Training Method for Large Language Models
Dec 10, 2024



Distributed training methods are crucial for large language models (LLMs). However, existing distributed training methods often suffer from communication bottlenecks, stragglers, and limited elasticity. Local SGD methods have been proposed to address these issues, but their effectiveness remains limited to small-scale training due to additional memory overhead and lack of concerns on efficiency and stability. To tackle these issues, we propose EDiT, an innovative Efficient Distributed Training method that combines a tailored Local SGD approach with model sharding techniques to enhance large-scale training efficiency. EDiT performs layer-wise parameter synchronization during forward pass, reducing communication and memory overhead and enabling the overlap of computation and communication. Besides, EDiT employs a pseudo gradient penalty strategy to suppress loss spikes, which ensures training stability and improve performance. Additionally, we introduce A-EDiT, a fully asynchronous variant of EDiT that accommodates heterogeneous clusters. Building on EDiT/A-EDiT, we conduct a series of experiments to validate large-scale asynchronous training for LLMs, accompanied by comprehensive analyses. Experimental results demonstrate the superior performance of EDiT/A-EDiT, establishing them as robust solutions for distributed LLM training in diverse computational ecosystems.
AGD: an Auto-switchable Optimizer using Stepwise Gradient Difference for Preconditioning Matrix
Dec 04, 2023
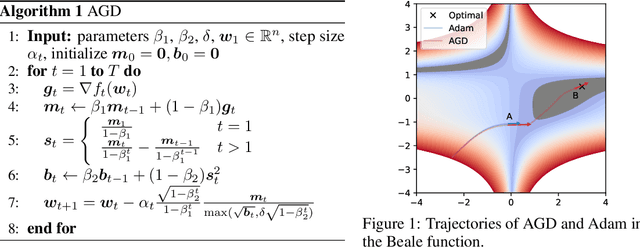
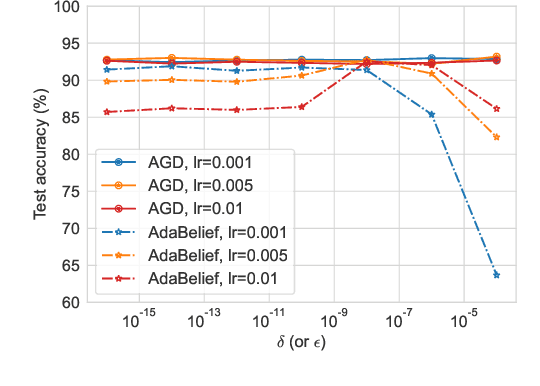
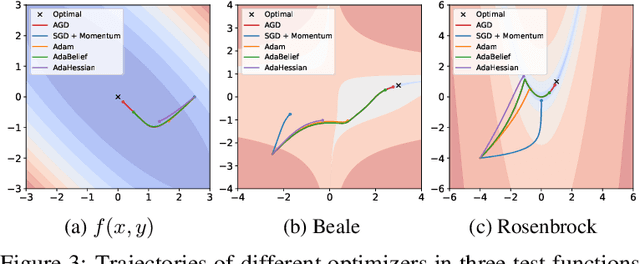
Adaptive optimizers, such as Adam, have achieved remarkable success in deep learning. A key component of these optimizers is the so-called preconditioning matrix, providing enhanced gradient information and regulating the step size of each gradient direction. In this paper, we propose a novel approach to designing the preconditioning matrix by utilizing the gradient difference between two successive steps as the diagonal elements. These diagonal elements are closely related to the Hessian and can be perceived as an approximation of the inner product between the Hessian row vectors and difference of the adjacent parameter vectors. Additionally, we introduce an auto-switching function that enables the preconditioning matrix to switch dynamically between Stochastic Gradient Descent (SGD) and the adaptive optimizer. Based on these two techniques, we develop a new optimizer named AGD that enhances the generalization performance. We evaluate AGD on public datasets of Natural Language Processing (NLP), Computer Vision (CV), and Recommendation Systems (RecSys). Our experimental results demonstrate that AGD outperforms the state-of-the-art (SOTA) optimizers, achieving highly competitive or significantly better predictive performance. Furthermore, we analyze how AGD is able to switch automatically between SGD and the adaptive optimizer and its actual effects on various scenarios. The code is available at https://github.com/intelligent-machine-learning/dlrover/tree/master/atorch/atorch/optimizers.
Sharpness-Aware Minimization Revisited: Weighted Sharpness as a Regularization Term
May 25, 2023



Deep Neural Networks (DNNs) generalization is known to be closely related to the flatness of minima, leading to the development of Sharpness-Aware Minimization (SAM) for seeking flatter minima and better generalization. In this paper, we revisit the loss of SAM and propose a more general method, called WSAM, by incorporating sharpness as a regularization term. We prove its generalization bound through the combination of PAC and Bayes-PAC techniques, and evaluate its performance on various public datasets. The results demonstrate that WSAM achieves improved generalization, or is at least highly competitive, compared to the vanilla optimizer, SAM and its variants. The code is available at https://github.com/intelligent-machine-learning/dlrover/tree/master/atorch/atorch/optimizers.