 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGD: an Auto-switchable Optimizer using Stepwise Gradient Difference for Preconditioning Matrix
Paper and Code

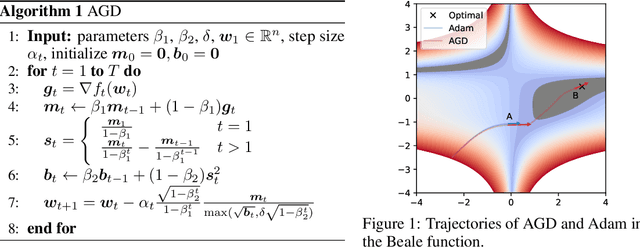
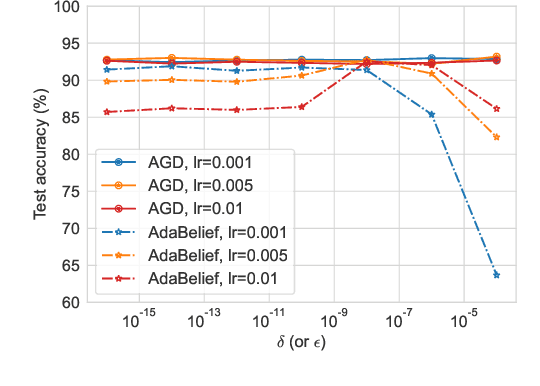
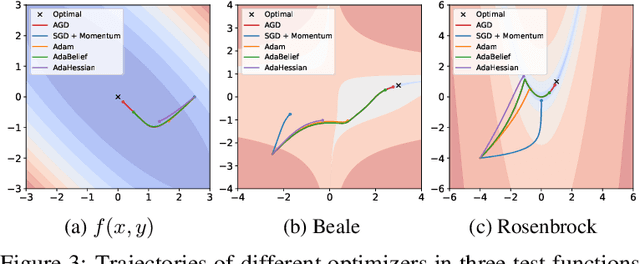
Adaptive optimizers, such as Adam, have achieved remarkable success in deep learning. A key component of these optimizers is the so-called preconditioning matrix, providing enhanced gradient information and regulating the step size of each gradient direction. In this paper, we propose a novel approach to designing the preconditioning matrix by utilizing the gradient difference between two successive steps as the diagonal elements. These diagonal elements are closely related to the Hessian and can be perceived as an approximation of the inner product between the Hessian row vectors and difference of the adjacent parameter vectors. Additionally, we introduce an auto-switching function that enables the preconditioning matrix to switch dynamically between Stochastic Gradient Descent (SGD) and the adaptive optimizer. Based on these two techniques, we develop a new optimizer named AGD that enhances the generalization performance. We evaluate AGD on public datasets of Natural Language Processing (NLP), Computer Vision (CV), and Recommendation Systems (RecSys). Our experimental results demonstrate that AGD outperforms the state-of-the-art (SOTA) optimizers, achieving highly competitive or significantly better predictive performance. Furthermore, we analyze how AGD is able to switch automatically between SGD and the adaptive optimizer and its actual effects on various scenarios. The code is available at https://github.com/intelligent-machine-learning/dlrover/tree/master/atorch/atorch/optimizers.