 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Align, Aligning to Learn: A Unified Approach for Self-Optimized Alignment
Aug 11, 2025



Alignment methodologies have emerged as a critical pathway for enhancing language model alignment capabilities. While SFT (supervised fine-tuning) accelerates convergence through direct token-level loss intervention, its efficacy is constrained by offline policy trajectory. In contrast, RL(reinforcement learning) facilitates exploratory policy optimization, but suffers from low sample efficiency and stringent dependency on high-quality base models. To address these dual challenges, we propose GRAO (Group Relative Alignment Optimization), a unified framework that synergizes the respective strengths of SFT and RL through three key innovations: 1) A multi-sample generation strategy enabling comparative quality assessment via reward feedback; 2) A novel Group Direct Alignment Loss formulation leveraging intra-group relative advantage weighting; 3) Reference-aware parameter updates guided by pairwise preference dynamics. Our theoretical analysis establishes GRAO's convergence guarantees and sample efficiency advantages over conventional approaches. Comprehensive evaluations across complex human alignment tasks demonstrate GRAO's superior performance, achieving 57.70\%,17.65\% 7.95\% and 5.18\% relative improvements over SFT, DPO, PPO and GRPO baselines respectively. This work provides both a theoretically grounded alignment framework and empirical evidence for efficient capability evolution in language models.
PointNCBW: Towards Dataset Ownership Verification for Point Clouds via Negative Clean-label Backdoor Watermark
Aug 10, 2024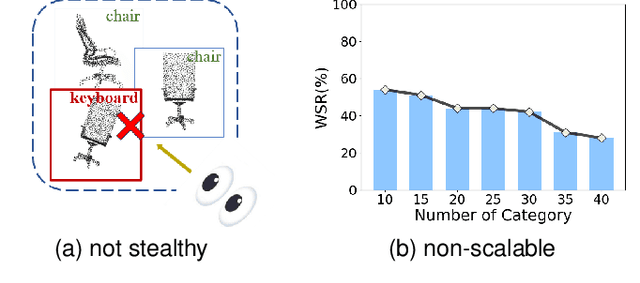
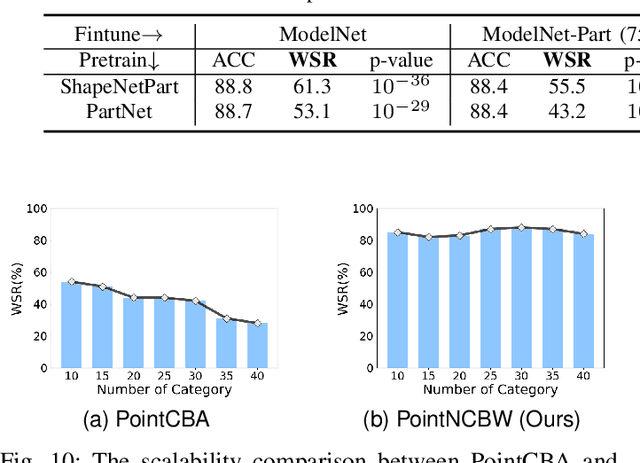


Recently, point clouds have been widely used in computer vision, whereas their collection is time-consuming and expensive. As such, point cloud datasets are the valuable intellectual property of their owners and deserve protection. To detect and prevent unauthorized use of these datasets, especially for commercial or open-sourced ones that cannot be sold again or used commercially without permission, we intend to identify whether a suspicious third-party model is trained on our protected dataset under the black-box setting. We achieve this goal by designing a scalable clean-label backdoor-based dataset watermark for point clouds that ensures both effectiveness and stealthiness. Unlike existing clean-label watermark schemes, which are susceptible to the number of categories, our method could watermark samples from all classes instead of only from the target one. Accordingly, it can still preserve high effectiveness even on large-scale datasets with many classes. Specifically, we perturb selected point clouds with non-target categories in both shape-wise and point-wise manners before inserting trigger patterns without changing their labels. The features of perturbed samples are similar to those of benign samples from the target class. As such, models trained on the watermarked dataset will have a distinctive yet stealthy backdoor behavior, i.e., misclassifying samples from the target class whenever triggers appear, since the trained DNNs will treat the inserted trigger pattern as a signal to deny predicting the target label. We also design a hypothesis-test-guided dataset ownership verification based on the proposed watermark. Extensive experiments on benchmark datasets are conducted, verifying the effectiveness of our method and its resistance to potential removal methods.
TrustAgent: Towards Safe and Trustworthy LLM-based Agents through Agent Constitution
Feb 02, 2024The emergence of LLM-based agents has garnered considerable attention, yet their trustworthiness remains an under-explored area. As agents can directly interact with the physical environment, their reliability and safety is critical. This paper presents an Agent-Constitution-based agent framework, TrustAgent, an initial investigation into improving the safety dimension of trustworthiness in LLM-based agents. This framework consists of threefold strategies: pre-planning strategy which injects safety knowledge to the model prior to plan generation, in-planning strategy which bolsters safety during plan generation, and post-planning strategy which ensures safety by post-planning inspection. Through experimental analysis, we demonstrate how these approaches can effectively elevate an LLM agent's safety by identifying and preventing potential dangers. Furthermore, we explore the intricate relationships between safety and helpfulness, and between the model's reasoning ability and its efficacy as a safe agent. This paper underscores the imperative of integrating safety awareness and trustworthiness into the design and deployment of LLM-based agents, not only to enhance their performance but also to ensure their responsible integration into human-centric environments. Data and code are available at https://github.com/agiresearch/TrustAgent.
GeoGPT: Understanding and Processing Geospatial Tasks through An Autonomous GPT
Jul 16, 2023



Decision-makers in GIS need to combine a series of spatial algorithms and operations to solve geospatial tasks. For example, in the task of facility siting, the Buffer tool is usually first used to locate areas close or away from some specific entities; then, the Intersect or Erase tool is used to select candidate areas satisfied multiple requirements. Though professionals can easily understand and solve these geospatial tasks by sequentially utilizing relevant tools, it is difficult for non-professionals to handle these problems. Recently, Generative Pre-trained Transformer (e.g., ChatGPT) presents strong performance in semantic understanding and reasoning. Especially, AutoGPT can further extend the capabilities of large language models (LLMs) by automatically reasoning and calling externally defined tools. Inspired by these studies, we attempt to lower the threshold of non-professional users to solve geospatial tasks by integrating the semantic understanding ability inherent in LLMs with mature tools within the GIS community. Specifically, we develop a new framework called GeoGPT that can conduct geospatial data collection, processing, and analysis in an autonomous manner with the instruction of only natural language. In other words, GeoGPT is used to understand the demands of non-professional users merely based on input natural language descriptions, and then think, plan, and execute defined GIS tools to output final effective results. Several cases including geospatial data crawling, spatial query, facility siting, and mapping validate the effectiveness of our framework. Though limited cases are presented in this paper, GeoGPT can be further extended to various tasks by equipping with more GIS tools, and we think the paradigm of "foundational plus professional" implied in GeoGPT provides an effective way to develop next-generation GIS in this era of large foundation models.