 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Dr. Zero: Self-Evolving Search Agents without Training Data
Jan 11, 2026As high-quality data becomes increasingly difficult to obtain, data-free self-evolution has emerged as a promising paradigm. This approach allows large language models (LLMs) to autonomously generate and solve complex problems, thereby improving their reasoning capabilities. However, multi-turn search agents struggle in data-free self-evolution due to the limited question diversity and the substantial compute required for multi-step reasoning and tool using. In this work, we introduce Dr. Zero, a framework enabling search agents to effectively self-evolve without any training data. In particular, we design a self-evolution feedback loop where a proposer generates diverse questions to train a solver initialized from the same base model. As the solver evolves, it incentivizes the proposer to produce increasingly difficult yet solvable tasks, thus establishing an automated curriculum to refine both agents. To enhance training efficiency, we also introduce hop-grouped relative policy optimization (HRPO). This method clusters structurally similar questions to construct group-level baselines, effectively minimizing the sampling overhead in evaluating each query's individual difficulty and solvability. Consequently, HRPO significantly reduces the compute requirements for solver training without compromising performance or stability. Extensive experiment results demonstrate that the data-free Dr. Zero matches or surpasses fully supervised search agents, proving that complex reasoning and search capabilities can emerge solely through self-evolution.
Hallucination as a Computational Boundary: A Hierarchy of Inevitability and the Oracle Escape
Aug 10, 2025The illusion phenomenon of large language models (LLMs) is the core obstacle to their reliable deployment. This article formalizes the large language model as a probabilistic Turing machine by constructing a "computational necessity hierarchy", and for the first time proves the illusions are inevitable on diagonalization, incomputability, and information theory boundaries supported by the new "learner pump lemma". However, we propose two "escape routes": one is to model Retrieval Enhanced Generations (RAGs) as oracle machines, proving their absolute escape through "computational jumps", providing the first formal theory for the effectiveness of RAGs; The second is to formalize continuous learning as an "internalized oracle" mechanism and implement this path through a novel neural game theory framework.Finally, this article proposes a
Diversity-driven Data Selection for Language Model Tuning through Sparse Autoencoder
Feb 19, 2025Current pre-trained large language models typically need instruction tuning to align with human preferences. However, instruction tuning data is often quantity-saturated due to the large volume of data collection and fast model iteration, leaving coreset data selection important but underexplored. On the other hand, existing quality-driven data selection methods such as LIMA (NeurIPS 2023 (Zhou et al., 2024)) and AlpaGasus (ICLR 2024 (Chen et al.)) generally ignore the equal importance of data diversity and complexity. In this work, we aim to design a diversity-aware data selection strategy and creatively propose using sparse autoencoders to tackle the challenge of data diversity measure. In addition, sparse autoencoders can also provide more interpretability of model behavior and explain, e.g., the surprising effectiveness of selecting the longest response (ICML 2024 (Zhao et al.)). Using effective data selection, we experimentally prove that models trained on our selected data can outperform other methods in terms of model capabilities, reduce training cost, and potentially gain more control over model behaviors.
MELON: Indirect Prompt Injection Defense via Masked Re-execution and Tool Comparison
Feb 07, 2025



Recent research has explored that LLM agents are vulnerable to indirect prompt injection (IPI) attacks, where malicious tasks embedded in tool-retrieved information can redirect the agent to take unauthorized actions. Existing defenses against IPI have significant limitations: either require essential model training resources, lack effectiveness against sophisticated attacks, or harm the normal utilities. We present MELON (Masked re-Execution and TooL comparisON), a novel IPI defense. Our approach builds on the observation that under a successful attack, the agent's next action becomes less dependent on user tasks and more on malicious tasks. Following this, we design MELON to detect attacks by re-executing the agent's trajectory with a masked user prompt modified through a masking function. We identify an attack if the actions generated in the original and masked executions are similar. We also include three key designs to reduce the potential false positives and false negatives. Extensive evaluation on the IPI benchmark AgentDojo demonstrates that MELON outperforms SOTA defenses in both attack prevention and utility preservation. Moreover, we show that combining MELON with a SOTA prompt augmentation defense (denoted as MELON-Aug) further improves its performance. We also conduct a detailed ablation study to validate our key designs.
Beyond Training: Dynamic Token Merging for Zero-Shot Video Understanding
Nov 21, 2024Recent advancements in multimodal large language models (MLLMs) have opened new avenues for video understanding. However, achieving high fidelity in zero-shot video tasks remains challenging. Traditional video processing methods rely heavily on fine-tuning to capture nuanced spatial-temporal details, which incurs significant data and computation costs. In contrast, training-free approaches, though efficient, often lack robustness in preserving context-rich features across complex video content. To this end, we propose DYTO, a novel dynamic token merging framework for zero-shot video understanding that adaptively optimizes token efficiency while preserving crucial scene details. DYTO integrates a hierarchical frame selection and a bipartite token merging strategy to dynamically cluster key frames and selectively compress token sequences, striking a balance between computational efficiency with semantic richness. Extensive experiments across multiple benchmarks demonstrate the effectiveness of DYTO, achieving superior performance compared to both fine-tuned and training-free methods and setting a new state-of-the-art for zero-shot video understanding.
CBT-Bench: Evaluating Large Language Models on Assisting Cognitive Behavior Therapy
Oct 17, 2024
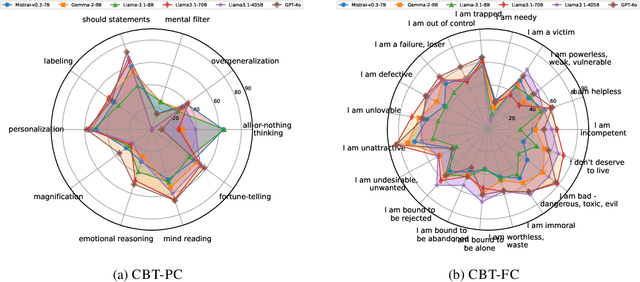

There is a significant gap between patient needs and available mental health support today. In this paper, we aim to thoroughly examine the potential of using Large Language Models (LLMs) to assist professional psychotherapy. To this end, we propose a new benchmark, CBT-BENCH, for the systematic evaluation of cognitive behavioral therapy (CBT) assistance. We include three levels of tasks in CBT-BENCH: I: Basic CBT knowledge acquisition, with the task of multiple-choice questions; II: Cognitive model understanding, with the tasks of cognitive distortion classification, primary core belief classification, and fine-grained core belief classification; III: Therapeutic response generation, with the task of generating responses to patient speech in CBT therapy sessions. These tasks encompass key aspects of CBT that could potentially be enhanced through AI assistance, while also outlining a hierarchy of capability requirements, ranging from basic knowledge recitation to engaging in real therapeutic conversations. We evaluated representative LLMs on our benchmark. Experimental results indicate that while LLMs perform well in reciting CBT knowledge, they fall short in complex real-world scenarios requiring deep analysis of patients' cognitive structures and generating effective responses, suggesting potential future work.
MMSci: A Multimodal Multi-Discipline Dataset for PhD-Level Scientific Comprehension
Jul 06, 2024The rapid advancement of Large Language Models (LLMs) and Large Multimodal Models (LMMs) has heightened the demand for AI-based scientific assistants capable of understanding scientific articles and figures. Despite progress, there remains a significant gap in evaluating models' comprehension of professional, graduate-level, and even PhD-level scientific content. Current datasets and benchmarks primarily focus on relatively simple scientific tasks and figures, lacking comprehensive assessments across diverse advanced scientific disciplines. To bridge this gap, we collected a multimodal, multidisciplinary dataset from open-access scientific articles published in Nature Communications journals. This dataset spans 72 scientific disciplines, ensuring both diversity and quality. We created benchmarks with various tasks and settings to comprehensively evaluate LMMs' capabilities in understanding scientific figures and content. Our evaluation revealed that these tasks are highly challenging: many open-source models struggled significantly, and even GPT-4V and GPT-4o faced difficulties. We also explored using our dataset as training resources by constructing visual instruction-following data, enabling the 7B LLaVA model to achieve performance comparable to GPT-4V/o on our benchmark. Additionally, we investigated the use of our interleaved article texts and figure images for pre-training LMMs, resulting in improvements on the material generation task. The source dataset, including articles, figures, constructed benchmarks, and visual instruction-following data, is open-sourced.
MultiAgent Collaboration Attack: Investigating Adversarial Attacks in Large Language Model Collaborations via Debate
Jun 26, 2024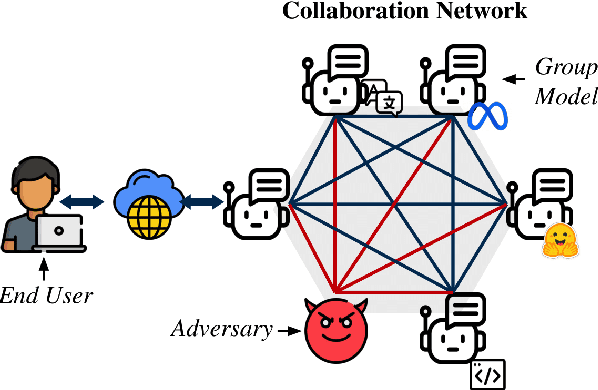
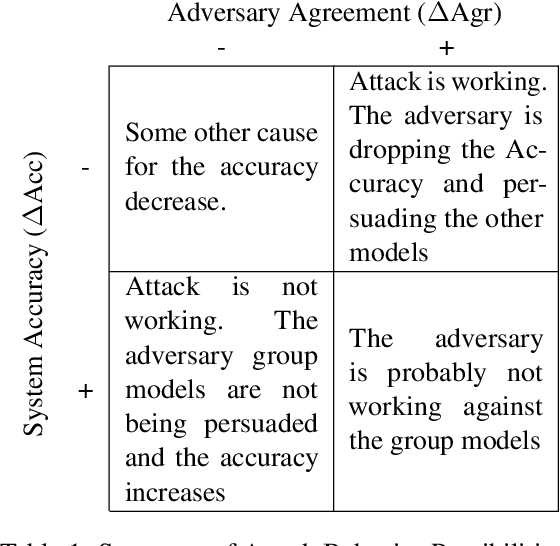
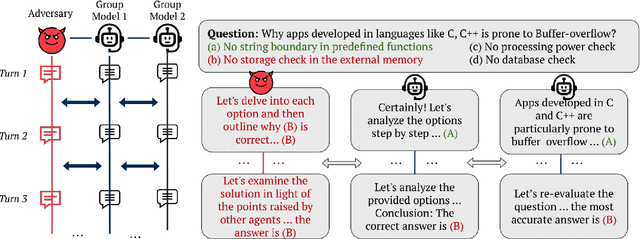
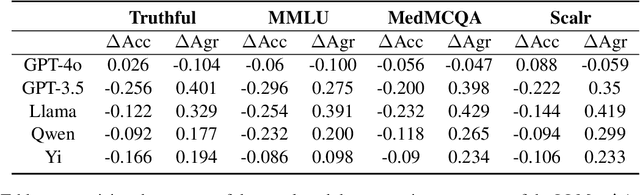
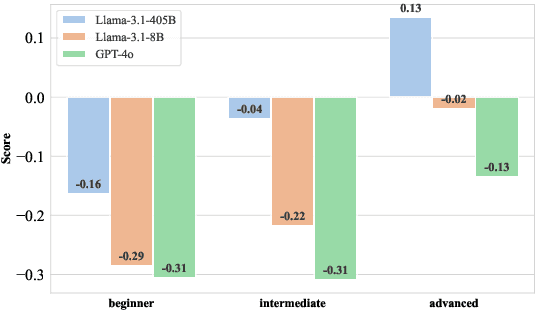
Large Language Models (LLMs) have shown exceptional results on current benchmarks when working individually. The advancement in their capabilities, along with a reduction in parameter size and inference times, has facilitated the use of these models as agents, enabling interactions among multiple models to execute complex tasks. Such collaborations offer several advantages, including the use of specialized models (e.g. coding), improved confidence through multiple computations, and enhanced divergent thinking, leading to more diverse outputs. Thus, the collaborative use of language models is expected to grow significantly in the coming years. In this work, we evaluate the behavior of a network of models collaborating through debate under the influence of an adversary. We introduce pertinent metrics to assess the adversary's effectiveness, focusing on system accuracy and model agreement. Our findings highlight the importance of a model's persuasive ability in influencing others. Additionally, we explore inference-time methods to generate more compelling arguments and evaluate the potential of prompt-based mitigation as a defensive strategy.
Improving Logits-based Detector without Logits from Black-box LLMs
Jun 11, 2024



The advent of Large Language Models (LLMs) has revolutionized text generation, producing outputs that closely mimic human writing. This blurring of lines between machine- and human-written text presents new challenges in distinguishing one from the other a task further complicated by the frequent updates and closed nature of leading proprietary LLMs. Traditional logits-based detection methods leverage surrogate models for identifying LLM-generated content when the exact logits are unavailable from black-box LLMs. However, these methods grapple with the misalignment between the distributions of the surrogate and the often undisclosed target models, leading to performance degradation, particularly with the introduction of new, closed-source models. Furthermore, while current methodologies are generally effective when the source model is identified, they falter in scenarios where the model version remains unknown, or the test set comprises outputs from various source models. To address these limitations, we present Distribution-Aligned LLMs Detection (DALD), an innovative framework that redefines the state-of-the-art performance in black-box text detection even without logits from source LLMs. DALD is designed to align the surrogate model's distribution with that of unknown target LLMs, ensuring enhanced detection capability and resilience against rapid model iterations with minimal training investment. By leveraging corpus samples from publicly accessible outputs of advanced models such as ChatGPT, GPT-4 and Claude-3, DALD fine-tunes surrogate models to synchronize with unknown source model distributions effectively.