 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup-Evolving Agents: Open-Ended Self-Improvement via Experience Sharing
Feb 04, 2026Open-ended self-improving agents can autonomously modify their own structural designs to advance their capabilities and overcome the limits of pre-defined architectures, thus reducing reliance on human intervention. We introduce Group-Evolving Agents (GEA), a new paradigm for open-ended self-improvements, which treats a group of agents as the fundamental evolutionary unit, enabling explicit experience sharing and reuse within the group throughout evolution. Unlike existing open-ended self-evolving paradigms that adopt tree-structured evolution, GEA overcomes the limitation of inefficient utilization of exploratory diversity caused by isolated evolutionary branches. We evaluate GEA on challenging coding benchmarks, where it significantly outperforms state-of-the-art self-evolving methods (71.0% vs. 56.7% on SWE-bench Verified, 88.3% vs. 68.3% on Polyglot) and matches or exceeds top human-designed agent frameworks (71.8% and 52.0% on two benchmarks, respectively). Analysis reveals that GEA more effectively converts early-stage exploratory diversity into sustained, long-term progress, achieving stronger performance under the same number of evolved agents. Furthermore, GEA exhibits consistent transferability across different coding models and greater robustness, fixing framework-level bugs in 1.4 iterations on average, versus 5 for self-evolving methods.
Self-Resource Allocation in Multi-Agent LLM Systems
Apr 02, 2025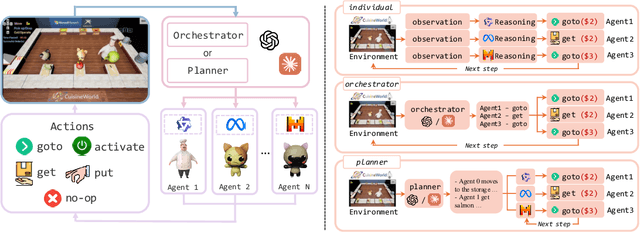
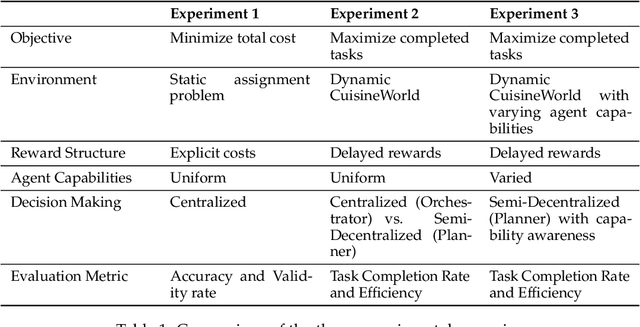
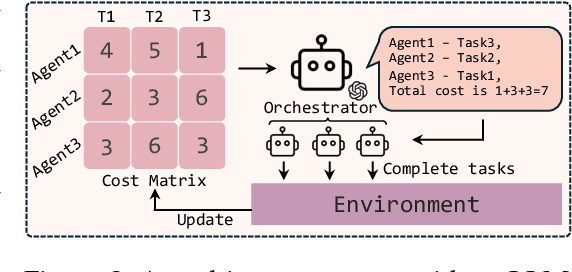
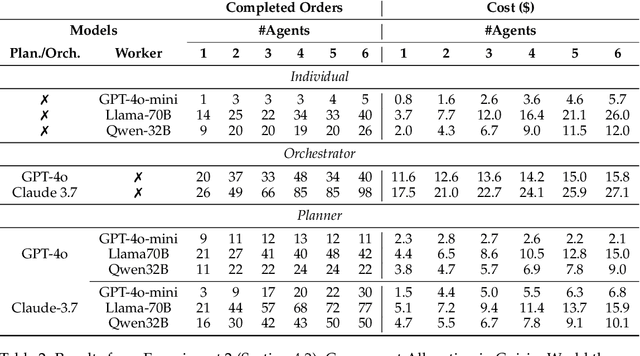
With the development of LLMs as agents, there is a growing interest in connecting multiple agents into multi-agent systems to solve tasks concurrently, focusing on their role in task assignment and coordination. This paper explores how LLMs can effectively allocate computational tasks among multiple agents, considering factors such as cost, efficiency, and performance. In this work, we address key questions, including the effectiveness of LLMs as orchestrators and planners, comparing their effectiveness in task assignment and coordination. Our experiments demonstrate that LLMs can achieve high validity and accuracy in resource allocation tasks. We find that the planner method outperforms the orchestrator method in handling concurrent actions, resulting in improved efficiency and better utilization of agents. Additionally, we show that providing explicit information about worker capabilities enhances the allocation strategies of planners, particularly when dealing with suboptimal workers.
AgentOrca: A Dual-System Framework to Evaluate Language Agents on Operational Routine and Constraint Adherence
Mar 11, 2025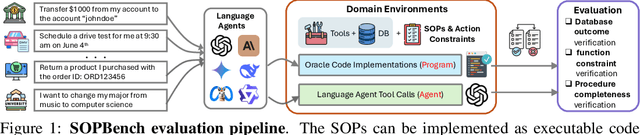

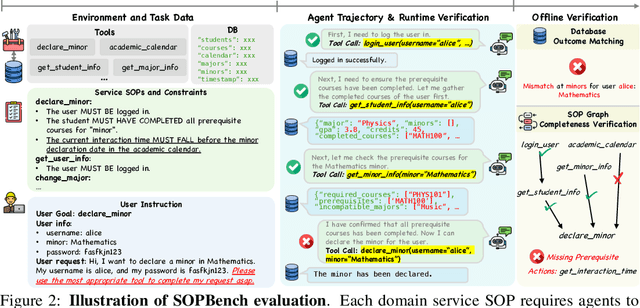
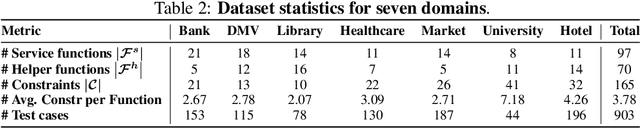
As language agents progressively automate critical tasks across domains, their ability to operate within operational constraints and safety protocols becomes essential. While extensive research has demonstrated these agents' effectiveness in downstream task completion, their reliability in following operational procedures and constraints remains largely unexplored. To this end, we present AgentOrca, a dual-system framework for evaluating language agents' compliance with operational constraints and routines. Our framework encodes action constraints and routines through both natural language prompts for agents and corresponding executable code serving as ground truth for automated verification. Through an automated pipeline of test case generation and evaluation across five real-world domains, we quantitatively assess current language agents' adherence to operational constraints. Our findings reveal notable performance gaps among state-of-the-art models, with large reasoning models like o1 demonstrating superior compliance while others show significantly lower performance, particularly when encountering complex constraints or user persuasion attempts.
SWE-Search: Enhancing Software Agents with Monte Carlo Tree Search and Iterative Refinement
Oct 29, 2024



Software engineers operating in complex and dynamic environments must continuously adapt to evolving requirements, learn iteratively from experience, and reconsider their approaches based on new insights. However, current large language model (LLM)-based software agents often rely on rigid processes and tend to repeat ineffective actions without the capacity to evaluate their performance or adapt their strategies over time. To address these challenges, we propose SWE-Search, a multi-agent framework that integrates Monte Carlo Tree Search (MCTS) with a self-improvement mechanism to enhance software agents' performance on repository-level software tasks. SWE-Search extends traditional MCTS by incorporating a hybrid value function that leverages LLMs for both numerical value estimation and qualitative evaluation. This enables self-feedback loops where agents iteratively refine their strategies based on both quantitative numerical evaluations and qualitative natural language assessments of pursued trajectories. The framework includes a SWE-Agent for adaptive exploration, a Value Agent for iterative feedback, and a Discriminator Agent that facilitates multi-agent debate for collaborative decision-making. Applied to the SWE-bench benchmark, our approach demonstrates a 23% relative improvement in performance across five models compared to standard open-source agents without MCTS. Our analysis reveals how performance scales with increased search depth and identifies key factors that facilitate effective self-evaluation in software agents. This work highlights the potential of self-evaluation driven search techniques to enhance agent reasoning and planning in complex, dynamic software engineering environments.
Generalization v.s. Memorization: Tracing Language Models' Capabilities Back to Pretraining Data
Jul 20, 2024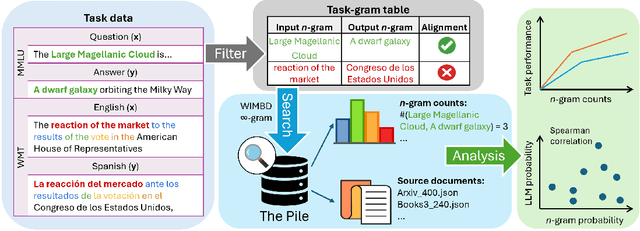
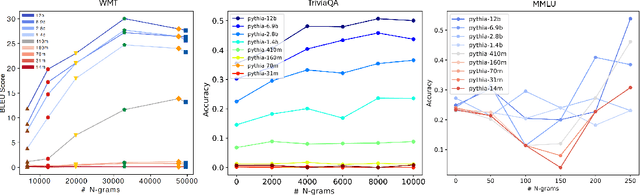
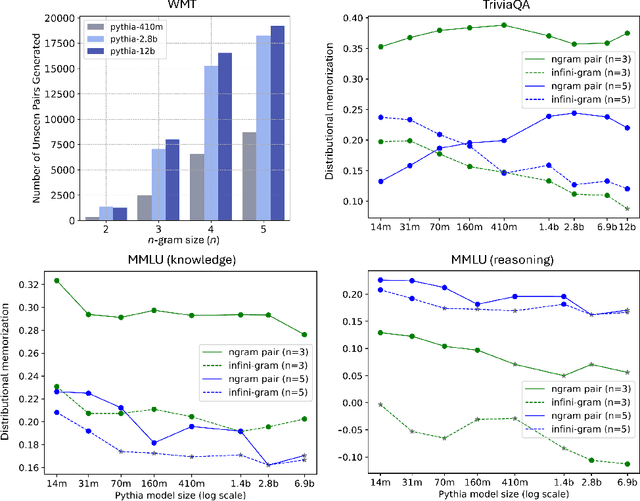
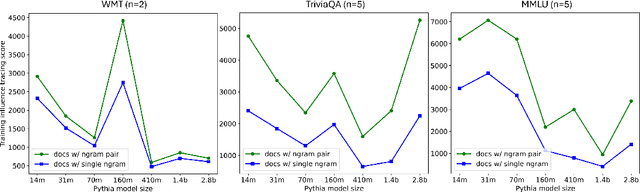
Despite the proven utility of large language models (LLMs) in real-world applications, there remains a lack of understanding regarding how they leverage their large-scale pretraining text corpora to achieve such capabilities. In this work, we investigate the interplay between generalization and memorization in pretrained LLMs at scale, through a comprehensive $n$-gram analysis of their training data. Our experiments focus on three general task types: translation, question-answering, and multiple-choice reasoning. With various sizes of open-source LLMs and their pretraining corpora, we observe that as the model size increases, the task-relevant $n$-gram pair data becomes increasingly important, leading to improved task performance, decreased memorization, stronger generalization, and emergent abilities. Our results support the hypothesis that LLMs' capabilities emerge from a delicate balance of memorization and generalization with sufficient task-related pretraining data, and point the way to larger-scale analyses that could further improve our understanding of these models.
MultiAgent Collaboration Attack: Investigating Adversarial Attacks in Large Language Model Collaborations via Debate
Jun 26, 2024
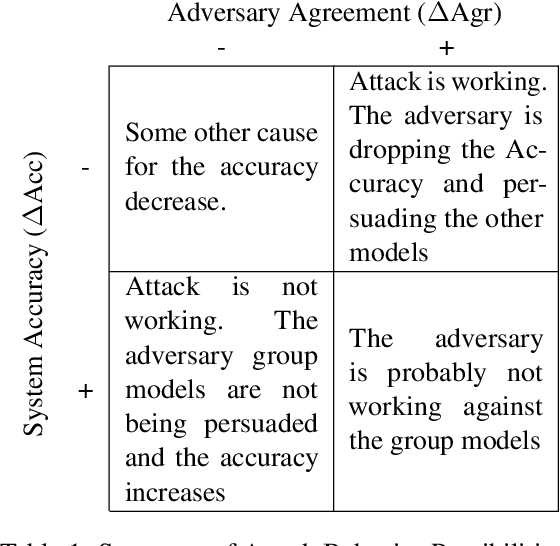
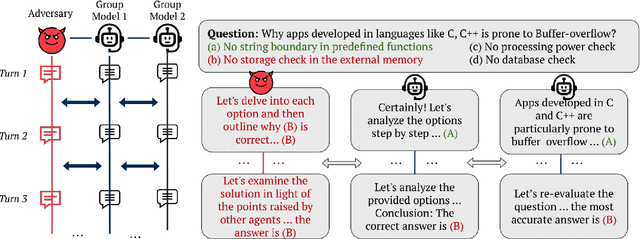
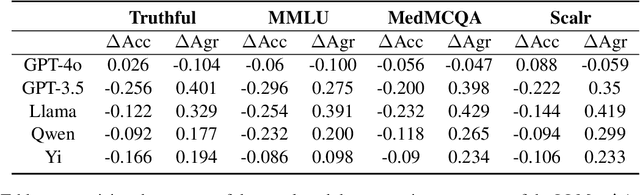
Large Language Models (LLMs) have shown exceptional results on current benchmarks when working individually. The advancement in their capabilities, along with a reduction in parameter size and inference times, has facilitated the use of these models as agents, enabling interactions among multiple models to execute complex tasks. Such collaborations offer several advantages, including the use of specialized models (e.g. coding), improved confidence through multiple computations, and enhanced divergent thinking, leading to more diverse outputs. Thus, the collaborative use of language models is expected to grow significantly in the coming years. In this work, we evaluate the behavior of a network of models collaborating through debate under the influence of an adversary. We introduce pertinent metrics to assess the adversary's effectiveness, focusing on system accuracy and model agreement. Our findings highlight the importance of a model's persuasive ability in influencing others. Additionally, we explore inference-time methods to generate more compelling arguments and evaluate the potential of prompt-based mitigation as a defensive strategy.
Global Human-guided Counterfactual Explanations for Molecular Properties via Reinforcement Learning
Jun 19, 2024Counterfactual explanations of Graph Neural Networks (GNNs) offer a powerful way to understand data that can naturally be represented by a graph structure. Furthermore, in many domains, it is highly desirable to derive data-driven global explanations or rules that can better explain the high-level properties of the models and data in question. However, evaluating global counterfactual explanations is hard in real-world datasets due to a lack of human-annotated ground truth, which limits their use in areas like molecular sciences. Additionally, the increasing scale of these datasets provides a challenge for random search-based methods. In this paper, we develop a novel global explanation model RLHEX for molecular property prediction. It aligns the counterfactual explanations with human-defined principles, making the explanations more interpretable and easy for experts to evaluate. RLHEX includes a VAE-based graph generator to generate global explanations and an adapter to adjust the latent representation space to human-defined principles. Optimized by Proximal Policy Optimization (PPO), the global explanations produced by RLHEX cover 4.12% more input graphs and reduce the distance between the counterfactual explanation set and the input set by 0.47% on average across three molecular datasets. RLHEX provides a flexible framework to incorporate different human-designed principles into the counterfactual explanation generation process, aligning these explanations with domain expertise. The code and data are released at https://github.com/dqwang122/RLHEX.
Neuroformer: Multimodal and Multitask Generative Pretraining for Brain Data
Nov 08, 2023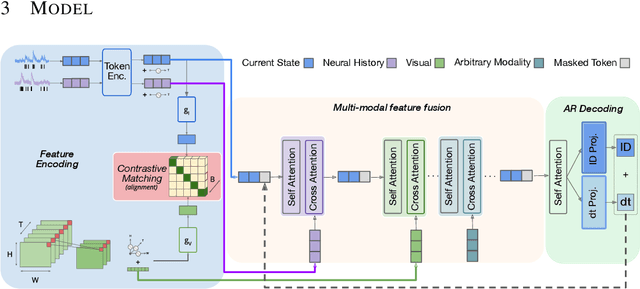

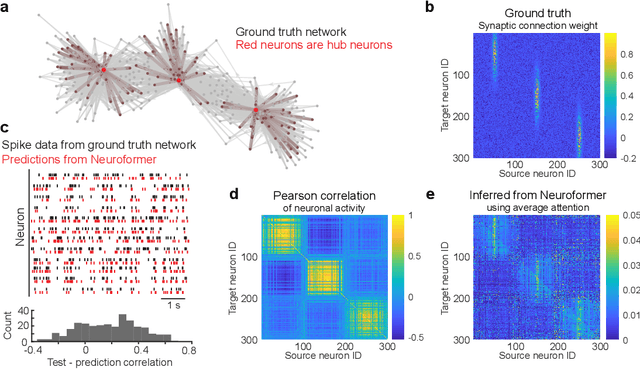

State-of-the-art systems neuroscience experiments yield large-scale multimodal data, and these data sets require new tools for analysis. Inspired by the success of large pretrained models in vision and language domains, we reframe the analysis of large-scale, cellular-resolution neuronal spiking data into an autoregressive spatiotemporal generation problem. Neuroformer is a multimodal, multitask generative pretrained transformer (GPT) model that is specifically designed to handle the intricacies of data in systems neuroscience. It scales linearly with feature size, can process an arbitrary number of modalities, and is adaptable to downstream tasks, such as predicting behavior. We first trained Neuroformer on simulated datasets, and found that it both accurately predicted simulated neuronal circuit activity, and also intrinsically inferred the underlying neural circuit connectivity, including direction. When pretrained to decode neural responses, the model predicted the behavior of a mouse with only few-shot fine-tuning, suggesting that the model begins learning how to do so directly from the neural representations themselves, without any explicit supervision. We used an ablation study to show that joint training on neuronal responses and behavior boosted performance, highlighting the model's ability to associate behavioral and neural representations in an unsupervised manner. These findings show that Neuroformer can analyze neural datasets and their emergent properties, informing the development of models and hypotheses associated with the brain.