 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Bootstrapped Reinforcement Learning
Mar 19, 2026Reinforcement Learning from Verifiable Rewards (RLVR) suffers from exploration inefficiency, where models struggle to generate successful rollouts, resulting in minimal learning signal. This challenge is particularly severe for tasks that require the acquisition of novel reasoning patterns or domain-specific knowledge. To address this, we propose Context Bootstrapped Reinforcement Learning (CBRL), which augments RLVR training by stochastically prepending few-shot demonstrations to training prompts. The injection probability follows a curriculum that starts high to bootstrap early exploration, then anneals to zero so the model must ultimately succeed without assistance. This forces the policy to internalize reasoning patterns from the demonstrations rather than relying on them at test time. We validate CBRL across two model families and five Reasoning Gym tasks. Our results demonstrate that CBRL consistently improves success rate, provides better exploration efficiency, and is algorithm-agnostic. We further demonstrate CBRL's practical applicability on Q, a domain-specific programming language that diverges significantly from mainstream language conventions.
Self-Resource Allocation in Multi-Agent LLM Systems
Apr 02, 2025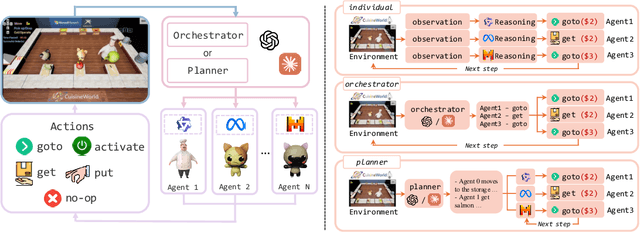
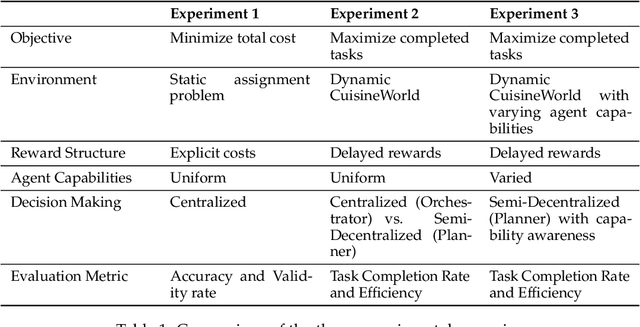
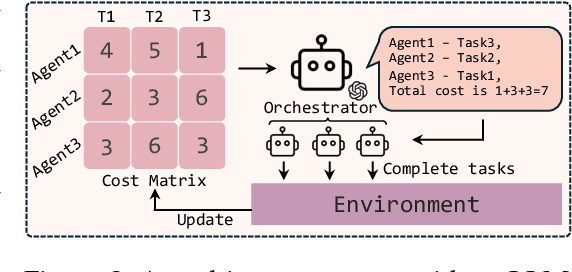
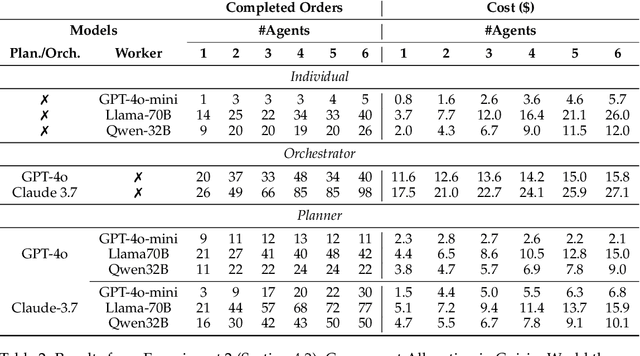
With the development of LLMs as agents, there is a growing interest in connecting multiple agents into multi-agent systems to solve tasks concurrently, focusing on their role in task assignment and coordination. This paper explores how LLMs can effectively allocate computational tasks among multiple agents, considering factors such as cost, efficiency, and performance. In this work, we address key questions, including the effectiveness of LLMs as orchestrators and planners, comparing their effectiveness in task assignment and coordination. Our experiments demonstrate that LLMs can achieve high validity and accuracy in resource allocation tasks. We find that the planner method outperforms the orchestrator method in handling concurrent actions, resulting in improved efficiency and better utilization of agents. Additionally, we show that providing explicit information about worker capabilities enhances the allocation strategies of planners, particularly when dealing with suboptimal workers.
Agent S2: A Compositional Generalist-Specialist Framework for Computer Use Agents
Apr 01, 2025



Computer use agents automate digital tasks by directly interacting with graphical user interfaces (GUIs) on computers and mobile devices, offering significant potential to enhance human productivity by completing an open-ended space of user queries. However, current agents face significant challenges: imprecise grounding of GUI elements, difficulties with long-horizon task planning, and performance bottlenecks from relying on single generalist models for diverse cognitive tasks. To this end, we introduce Agent S2, a novel compositional framework that delegates cognitive responsibilities across various generalist and specialist models. We propose a novel Mixture-of-Grounding technique to achieve precise GUI localization and introduce Proactive Hierarchical Planning, dynamically refining action plans at multiple temporal scales in response to evolving observations. Evaluations demonstrate that Agent S2 establishes new state-of-the-art (SOTA) performance on three prominent computer use benchmarks. Specifically, Agent S2 achieves 18.9% and 32.7% relative improvements over leading baseline agents such as Claude Computer Use and UI-TARS on the OSWorld 15-step and 50-step evaluation. Moreover, Agent S2 generalizes effectively to other operating systems and applications, surpassing previous best methods by 52.8% on WindowsAgentArena and by 16.52% on AndroidWorld relatively. Code available at https://github.com/simular-ai/Agent-S.
Agent S: An Open Agentic Framework that Uses Computers Like a Human
Oct 10, 2024



We present Agent S, an open agentic framework that enables autonomous interaction with computers through a Graphical User Interface (GUI), aimed at transforming human-computer interaction by automating complex, multi-step tasks. Agent S aims to address three key challenges in automating computer tasks: acquiring domain-specific knowledge, planning over long task horizons, and handling dynamic, non-uniform interfaces. To this end, Agent S introduces experience-augmented hierarchical planning, which learns from external knowledge search and internal experience retrieval at multiple levels, facilitating efficient task planning and subtask execution. In addition, it employs an Agent-Computer Interface (ACI) to better elicit the reasoning and control capabilities of GUI agents based on Multimodal Large Language Models (MLLMs). Evaluation on the OSWorld benchmark shows that Agent S outperforms the baseline by 9.37% on success rate (an 83.6% relative improvement) and achieves a new state-of-the-art. Comprehensive analysis highlights the effectiveness of individual components and provides insights for future improvements. Furthermore, Agent S demonstrates broad generalizability to different operating systems on a newly-released WindowsAgentArena benchmark. Code available at https://github.com/simular-ai/Agent-S.
Evaluating Multi-Agent Coordination Abilities in Large Language Models
Oct 05, 2023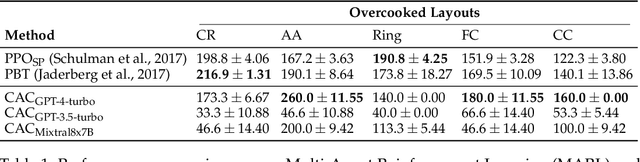
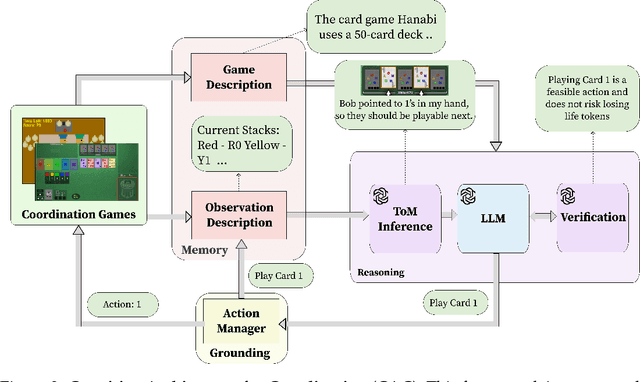

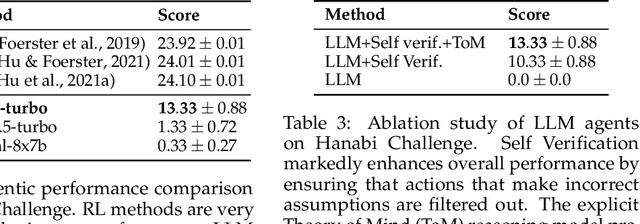
A pivotal aim in contemporary AI research is to develop agents proficient in multi-agent coordination, enabling effective collaboration with both humans and other systems. Large Language Models (LLMs), with their notable ability to understand, generate, and interpret language in a human-like manner, stand out as promising candidates for the development of such agents. In this study, we build and assess the effectiveness of agents crafted using LLMs in various coordination scenarios. We introduce the LLM-Coordination (LLM-Co) Framework, specifically designed to enable LLMs to play coordination games. With the LLM-Co framework, we conduct our evaluation with three game environments and organize the evaluation into five aspects: Theory of Mind, Situated Reasoning, Sustained Coordination, Robustness to Partners, and Explicit Assistance. First, the evaluation of the Theory of Mind and Situated Reasoning reveals the capabilities of LLM to infer the partner's intention and reason actions accordingly. Then, the evaluation around Sustained Coordination and Robustness to Partners further showcases the ability of LLMs to coordinate with an unknown partner in complex long-horizon tasks, outperforming Reinforcement Learning baselines. Lastly, to test Explicit Assistance, which refers to the ability of an agent to offer help proactively, we introduce two novel layouts into the Overcooked-AI benchmark, examining if agents can prioritize helping their partners, sacrificing time that could have been spent on their tasks. This research underscores the promising capabilities of LLMs in sophisticated coordination environments and reveals the potential of LLMs in building strong real-world agents for multi-agent coordination.
Studying writer-suggestion interaction: A qualitative study to understand writer interaction with aligned/misaligned next-phrase suggestion
Aug 01, 2022


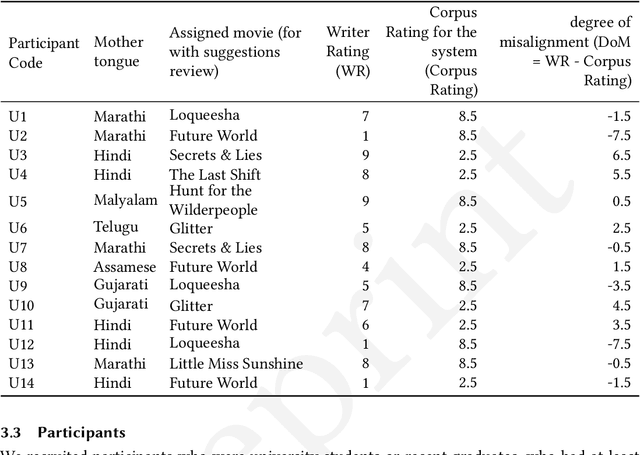
We present an exploratory qualitative study to understand how writers interact with next-phrase suggestions. While there has been some quantitative research on the effects of suggestion systems on writing, there has been little qualitative work to understand how writers interact with suggestion systems and how it affects their writing process - specifically for a non-native but English writer. We conducted a study where amateur writers were asked to write two movie reviews each, one without suggestions and one with. We found writers interact with next-phrase suggestions in various complex ways - writers are able to abstract multiple parts of the suggestions and incorporate them within their writing - even when they disagree with the suggestion as a whole. The suggestion system also had various effects on the writing processes - contributing to different aspects of the writing process in unique ways. We propose a model of writer-suggestion interaction for writing with GPT-2 for a movie review writing task, followed by ways in which the model can be used for future research, along with outlining opportunities for research and design.