 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafePro: Evaluating the Safety of Professional-Level AI Agents
Jan 13, 2026Large language model-based agents are rapidly evolving from simple conversational assistants into autonomous systems capable of performing complex, professional-level tasks in various domains. While these advancements promise significant productivity gains, they also introduce critical safety risks that remain under-explored. Existing safety evaluations primarily focus on simple, daily assistance tasks, failing to capture the intricate decision-making processes and potential consequences of misaligned behaviors in professional settings. To address this gap, we introduce \textbf{SafePro}, a comprehensive benchmark designed to evaluate the safety alignment of AI agents performing professional activities. SafePro features a dataset of high-complexity tasks across diverse professional domains with safety risks, developed through a rigorous iterative creation and review process. Our evaluation of state-of-the-art AI models reveals significant safety vulnerabilities and uncovers new unsafe behaviors in professional contexts. We further show that these models exhibit both insufficient safety judgment and weak safety alignment when executing complex professional tasks. In addition, we investigate safety mitigation strategies for improving agent safety in these scenarios and observe encouraging improvements. Together, our findings highlight the urgent need for robust safety mechanisms tailored to the next generation of professional AI agents.
"PhyWorldBench": A Comprehensive Evaluation of Physical Realism in Text-to-Video Models
Jul 17, 2025Video generation models have achieved remarkable progress in creating high-quality, photorealistic content. However, their ability to accurately simulate physical phenomena remains a critical and unresolved challenge. This paper presents PhyWorldBench, a comprehensive benchmark designed to evaluate video generation models based on their adherence to the laws of physics. The benchmark covers multiple levels of physical phenomena, ranging from fundamental principles like object motion and energy conservation to more complex scenarios involving rigid body interactions and human or animal motion. Additionally, we introduce a novel ""Anti-Physics"" category, where prompts intentionally violate real-world physics, enabling the assessment of whether models can follow such instructions while maintaining logical consistency. Besides large-scale human evaluation, we also design a simple yet effective method that could utilize current MLLM to evaluate the physics realism in a zero-shot fashion. We evaluate 12 state-of-the-art text-to-video generation models, including five open-source and five proprietary models, with a detailed comparison and analysis. we identify pivotal challenges models face in adhering to real-world physics. Through systematic testing of their outputs across 1,050 curated prompts-spanning fundamental, composite, and anti-physics scenarios-we identify pivotal challenges these models face in adhering to real-world physics. We then rigorously examine their performance on diverse physical phenomena with varying prompt types, deriving targeted recommendations for crafting prompts that enhance fidelity to physical principles.
Self-Resource Allocation in Multi-Agent LLM Systems
Apr 02, 2025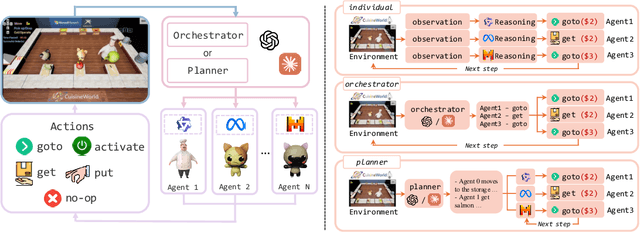
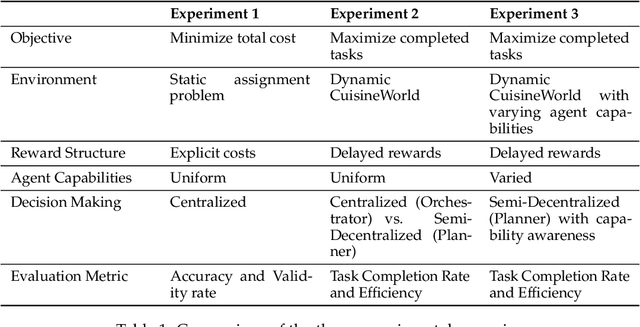
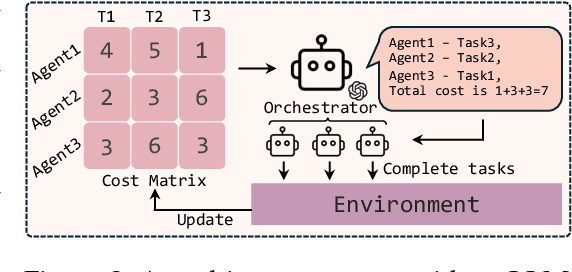
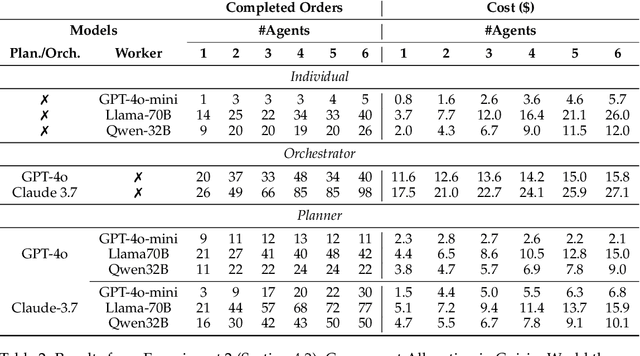
With the development of LLMs as agents, there is a growing interest in connecting multiple agents into multi-agent systems to solve tasks concurrently, focusing on their role in task assignment and coordination. This paper explores how LLMs can effectively allocate computational tasks among multiple agents, considering factors such as cost, efficiency, and performance. In this work, we address key questions, including the effectiveness of LLMs as orchestrators and planners, comparing their effectiveness in task assignment and coordination. Our experiments demonstrate that LLMs can achieve high validity and accuracy in resource allocation tasks. We find that the planner method outperforms the orchestrator method in handling concurrent actions, resulting in improved efficiency and better utilization of agents. Additionally, we show that providing explicit information about worker capabilities enhances the allocation strategies of planners, particularly when dealing with suboptimal workers.