 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning to Explore: Curiosity-Driven Planning for LLM Test Generation
Apr 06, 2026The use of LLMs for code generation has naturally extended to code testing and evaluation. As codebases grow in size and complexity, so does the need for automated test generation. Current approaches for LLM-based test generation rely on strategies that maximize immediate coverage gain, a greedy approach that plateaus on code where reaching deep branches requires setup steps that individually yield zero new coverage. Drawing on principles of Bayesian exploration, we treat the program's branch structure as an unknown environment, and an evolving coverage map as a proxy probabilistic posterior representing what the LLM has discovered so far. Our method, CovQValue, feeds the coverage map back to the LLM, generates diverse candidate plans in parallel, and selects the most informative plan by LLM-estimated Q-values, seeking actions that balance immediate branch discovery with future reachability. Our method outperforms greedy selection on TestGenEval Lite, achieving 51-77% higher branch coverage across three popular LLMs and winning on 77-84% of targets. In addition, we build a benchmark for iterative test generation, RepoExploreBench, where they achieve 40-74%. These results show the potential of curiosity-driven planning methods for LLM-based exploration, enabling more effective discovery of program behavior through sequential interaction
SpikeATac: A Multimodal Tactile Finger with Taxelized Dynamic Sensing for Dexterous Manipulation
Oct 30, 2025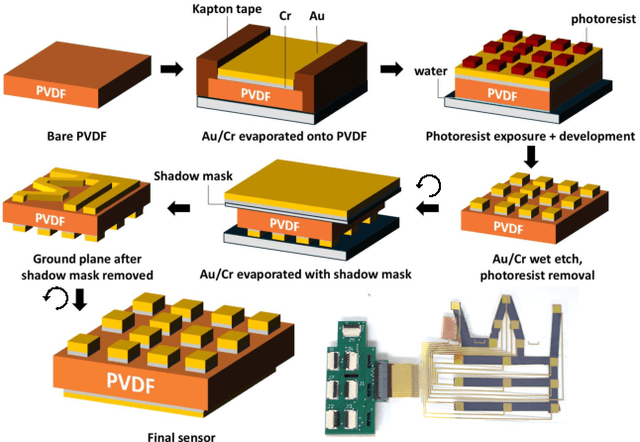
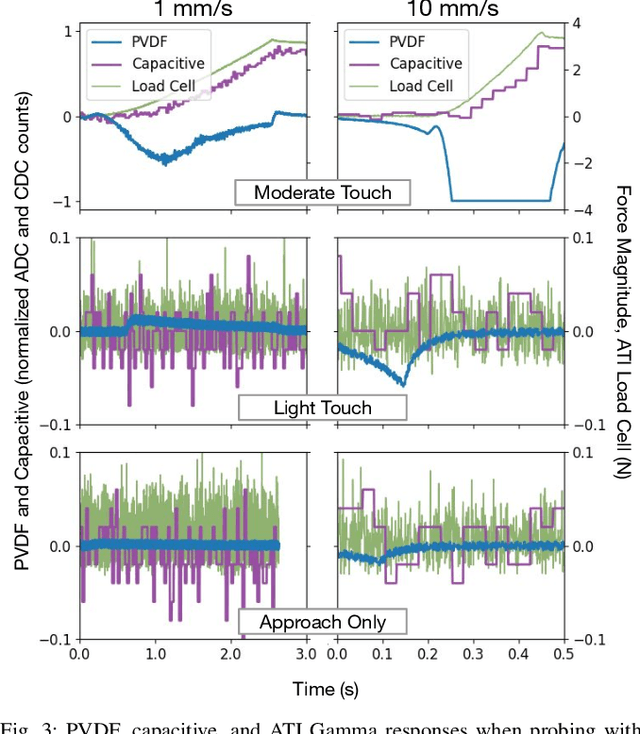
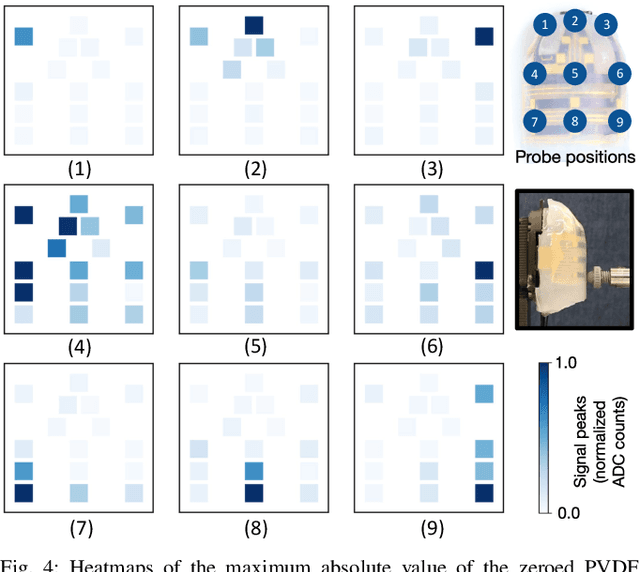
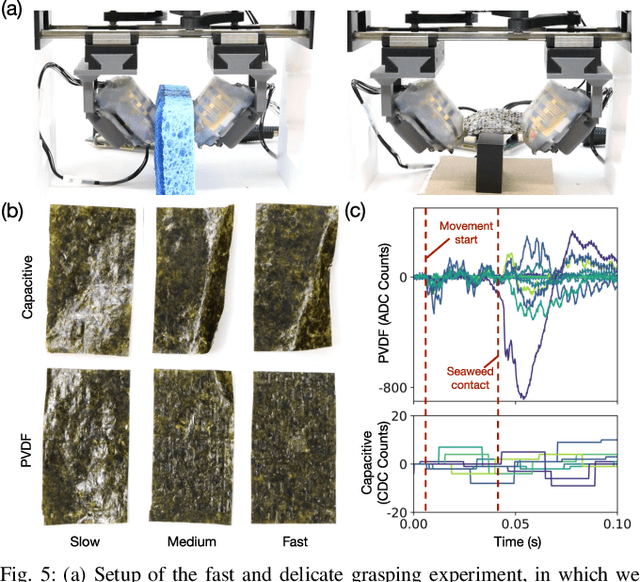
In this work, we introduce SpikeATac, a multimodal tactile finger combining a taxelized and highly sensitive dynamic response (PVDF) with a static transduction method (capacitive) for multimodal touch sensing. Named for its `spiky' response, SpikeATac's 16-taxel PVDF film sampled at 4 kHz provides fast, sensitive dynamic signals to the very onset and breaking of contact. We characterize the sensitivity of the different modalities, and show that SpikeATac provides the ability to stop quickly and delicately when grasping fragile, deformable objects. Beyond parallel grasping, we show that SpikeATac can be used in a learning-based framework to achieve new capabilities on a dexterous multifingered robot hand. We use a learning recipe that combines reinforcement learning from human feedback with tactile-based rewards to fine-tune the behavior of a policy to modulate force. Our hardware platform and learning pipeline together enable a difficult dexterous and contact-rich task that has not previously been achieved: in-hand manipulation of fragile objects. Videos are available at \href{https://roamlab.github.io/spikeatac/}{roamlab.github.io/spikeatac}.
Agents of Change: Self-Evolving LLM Agents for Strategic Planning
Jun 05, 2025Recent advances in LLMs have enabled their use as autonomous agents across a range of tasks, yet they continue to struggle with formulating and adhering to coherent long-term strategies. In this paper, we investigate whether LLM agents can self-improve when placed in environments that explicitly challenge their strategic planning abilities. Using the board game Settlers of Catan, accessed through the open-source Catanatron framework, we benchmark a progression of LLM-based agents, from a simple game-playing agent to systems capable of autonomously rewriting their own prompts and their player agent's code. We introduce a multi-agent architecture in which specialized roles (Analyzer, Researcher, Coder, and Player) collaborate to iteratively analyze gameplay, research new strategies, and modify the agent's logic or prompt. By comparing manually crafted agents to those evolved entirely by LLMs, we evaluate how effectively these systems can diagnose failure and adapt over time. Our results show that self-evolving agents, particularly when powered by models like Claude 3.7 and GPT-4o, outperform static baselines by autonomously adopting their strategies, passing along sample behavior to game-playing agents, and demonstrating adaptive reasoning over multiple iterations.
How Is LLM Reasoning Distracted by Irrelevant Context? An Analysis Using a Controlled Benchmark
May 24, 2025We introduce Grade School Math with Distracting Context (GSM-DC), a synthetic benchmark to evaluate Large Language Models' (LLMs) reasoning robustness against systematically controlled irrelevant context (IC). GSM-DC constructs symbolic reasoning graphs with precise distractor injections, enabling rigorous, reproducible evaluation. Our experiments demonstrate that LLMs are significantly sensitive to IC, affecting both reasoning path selection and arithmetic accuracy. Additionally, training models with strong distractors improves performance in both in-distribution and out-of-distribution scenarios. We further propose a stepwise tree search guided by a process reward model, which notably enhances robustness in out-of-distribution conditions.
Self-Resource Allocation in Multi-Agent LLM Systems
Apr 02, 2025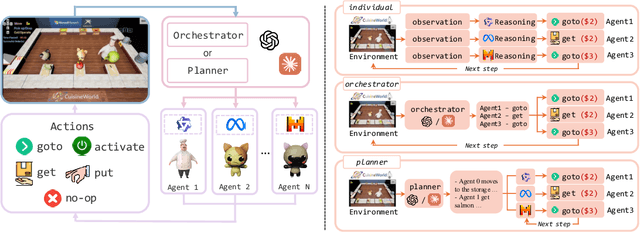
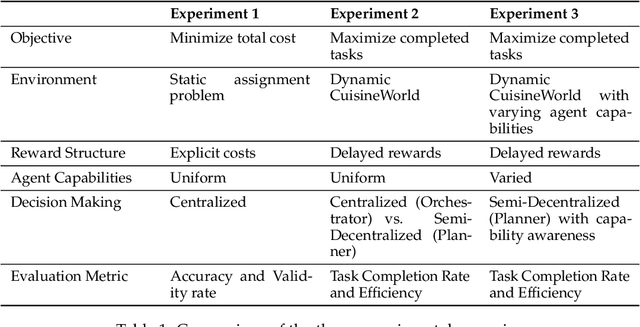
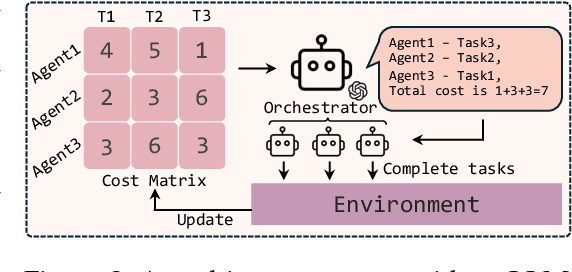
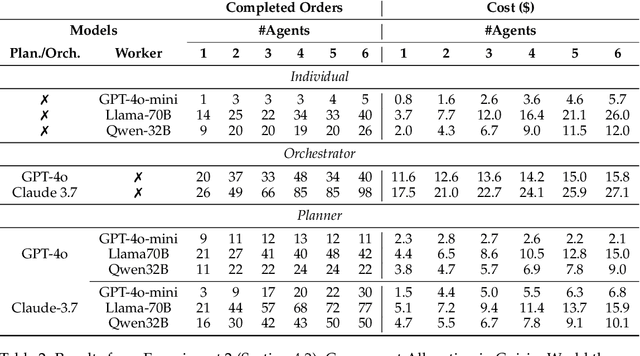
With the development of LLMs as agents, there is a growing interest in connecting multiple agents into multi-agent systems to solve tasks concurrently, focusing on their role in task assignment and coordination. This paper explores how LLMs can effectively allocate computational tasks among multiple agents, considering factors such as cost, efficiency, and performance. In this work, we address key questions, including the effectiveness of LLMs as orchestrators and planners, comparing their effectiveness in task assignment and coordination. Our experiments demonstrate that LLMs can achieve high validity and accuracy in resource allocation tasks. We find that the planner method outperforms the orchestrator method in handling concurrent actions, resulting in improved efficiency and better utilization of agents. Additionally, we show that providing explicit information about worker capabilities enhances the allocation strategies of planners, particularly when dealing with suboptimal workers.
VITED: Video Temporal Evidence Distillation
Mar 17, 2025We investigate complex video question answering via chain-of-evidence reasoning -- identifying sequences of temporal spans from multiple relevant parts of the video, together with visual evidence within them. Existing models struggle with multi-step reasoning as they uniformly sample a fixed number of frames, which can miss critical evidence distributed nonuniformly throughout the video. Moreover, they lack the ability to temporally localize such evidence in the broader context of the full video, which is required for answering complex questions. We propose a framework to enhance existing VideoQA datasets with evidence reasoning chains, automatically constructed by searching for optimal intervals of interest in the video with supporting evidence, that maximizes the likelihood of answering a given question. We train our model (VITED) to generate these evidence chains directly, enabling it to both localize evidence windows as well as perform multi-step reasoning across them in long-form video content. We show the value of our evidence-distilled models on a suite of long video QA benchmarks where we outperform state-of-the-art approaches that lack evidence reasoning capabilities.
Multimodal Chain-of-Thought Reasoning: A Comprehensive Survey
Mar 16, 2025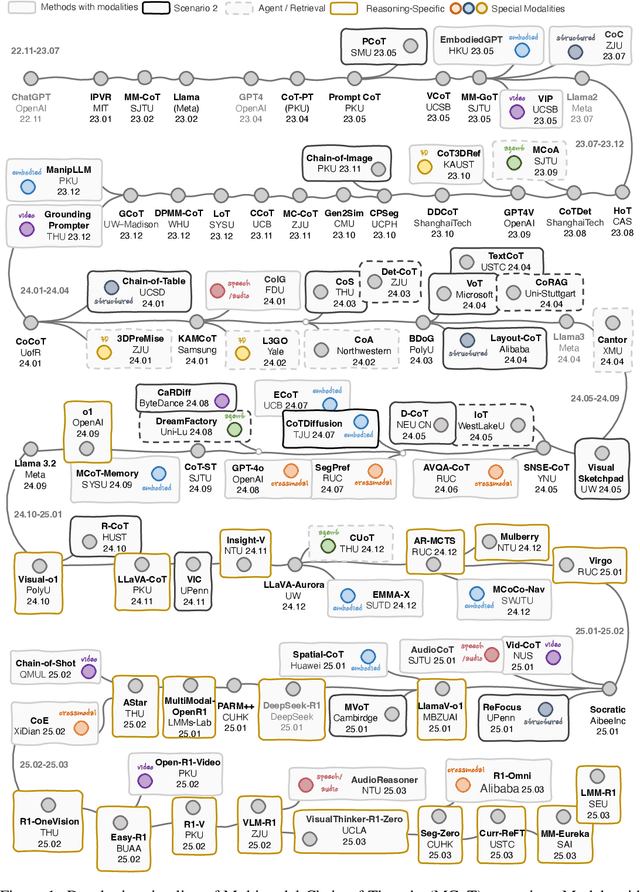

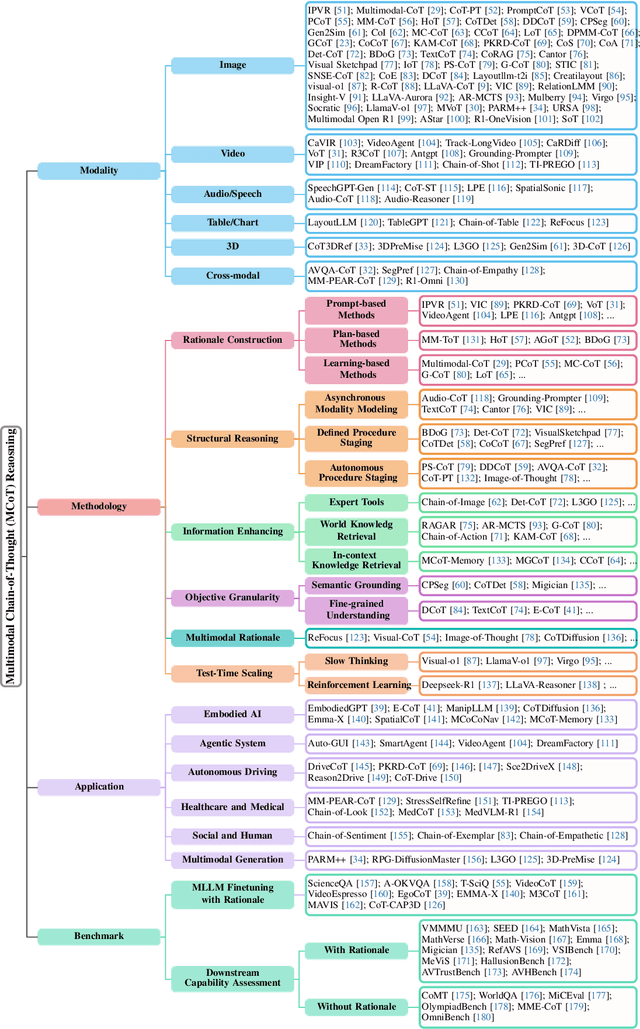
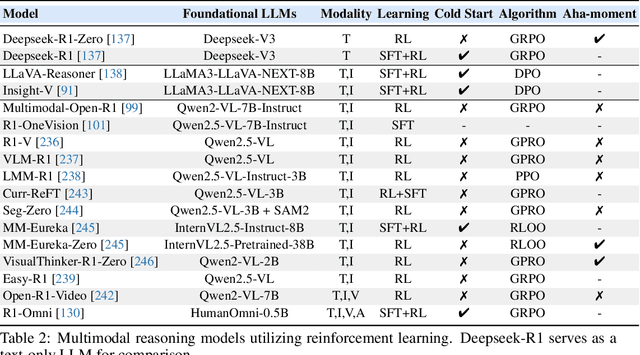
By extending the advantage of chain-of-thought (CoT) reasoning in human-like step-by-step processes to multimodal contexts, multimodal CoT (MCoT) reasoning has recently garnered significant research attention, especially in the integration with multimodal large language models (MLLMs). Existing MCoT studies design various methodologies and innovative reasoning paradigms to address the unique challenges of image, video, speech, audio, 3D, and structured data across different modalities, achieving extensive success in applications such as robotics, healthcare, autonomous driving, and multimodal generation. However, MCoT still presents distinct challenges and opportunities that require further focus to ensure consistent thriving in this field, where, unfortunately, an up-to-date review of this domain is lacking. To bridge this gap, we present the first systematic survey of MCoT reasoning, elucidating the relevant foundational concepts and definitions. We offer a comprehensive taxonomy and an in-depth analysis of current methodologies from diverse perspectives across various application scenarios. Furthermore, we provide insights into existing challenges and future research directions, aiming to foster innovation toward multimodal AGI.
Game-theoretic LLM: Agent Workflow for Negotiation Games
Nov 12, 2024



This paper investigates the rationality of large language models (LLMs) in strategic decision-making contexts, specifically within the framework of game theory. We evaluate several state-of-the-art LLMs across a spectrum of complete-information and incomplete-information games. Our findings reveal that LLMs frequently deviate from rational strategies, particularly as the complexity of the game increases with larger payoff matrices or deeper sequential trees. To address these limitations, we design multiple game-theoretic workflows that guide the reasoning and decision-making processes of LLMs. These workflows aim to enhance the models' ability to compute Nash Equilibria and make rational choices, even under conditions of uncertainty and incomplete information. Experimental results demonstrate that the adoption of these workflows significantly improves the rationality and robustness of LLMs in game-theoretic tasks. Specifically, with the workflow, LLMs exhibit marked improvements in identifying optimal strategies, achieving near-optimal allocations in negotiation scenarios, and reducing susceptibility to exploitation during negotiations. Furthermore, we explore the meta-strategic considerations of whether it is rational for agents to adopt such workflows, recognizing that the decision to use or forgo the workflow constitutes a game-theoretic issue in itself. Our research contributes to a deeper understanding of LLMs' decision-making capabilities in strategic contexts and provides insights into enhancing their rationality through structured workflows. The findings have implications for the development of more robust and strategically sound AI agents capable of navigating complex interactive environments. Code and data supporting this study are available at \url{https://github.com/Wenyueh/game_theory}.
SWE-Search: Enhancing Software Agents with Monte Carlo Tree Search and Iterative Refinement
Oct 29, 2024



Software engineers operating in complex and dynamic environments must continuously adapt to evolving requirements, learn iteratively from experience, and reconsider their approaches based on new insights. However, current large language model (LLM)-based software agents often rely on rigid processes and tend to repeat ineffective actions without the capacity to evaluate their performance or adapt their strategies over time. To address these challenges, we propose SWE-Search, a multi-agent framework that integrates Monte Carlo Tree Search (MCTS) with a self-improvement mechanism to enhance software agents' performance on repository-level software tasks. SWE-Search extends traditional MCTS by incorporating a hybrid value function that leverages LLMs for both numerical value estimation and qualitative evaluation. This enables self-feedback loops where agents iteratively refine their strategies based on both quantitative numerical evaluations and qualitative natural language assessments of pursued trajectories. The framework includes a SWE-Agent for adaptive exploration, a Value Agent for iterative feedback, and a Discriminator Agent that facilitates multi-agent debate for collaborative decision-making. Applied to the SWE-bench benchmark, our approach demonstrates a 23% relative improvement in performance across five models compared to standard open-source agents without MCTS. Our analysis reveals how performance scales with increased search depth and identifies key factors that facilitate effective self-evaluation in software agents. This work highlights the potential of self-evaluation driven search techniques to enhance agent reasoning and planning in complex, dynamic software engineering environments.
A Mathematical Framework, a Taxonomy of Modeling Paradigms, and a Suite of Learning Techniques for Neural-Symbolic Systems
Jul 12, 2024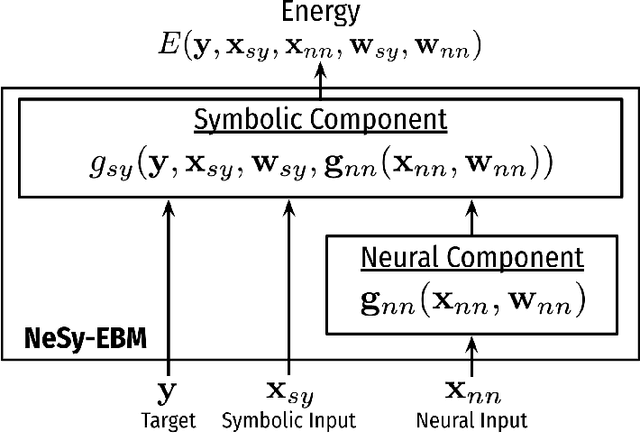

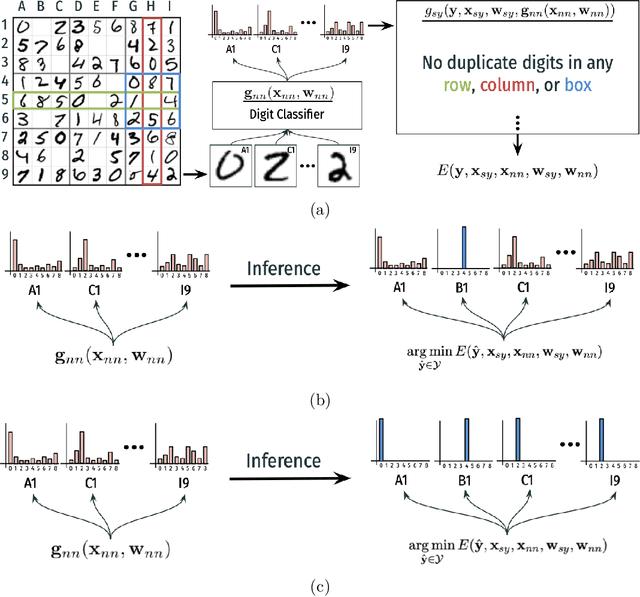
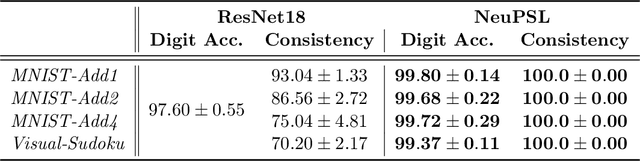
The field of Neural-Symbolic (NeSy) systems is growing rapidly. Proposed approaches show great promise in achieving symbiotic unions of neural and symbolic methods. However, each NeSy system differs in fundamental ways. There is a pressing need for a unifying theory to illuminate the commonalities and differences in approaches and enable further progress. In this paper, we introduce Neural-Symbolic Energy-Based Models (NeSy-EBMs), a unifying mathematical framework for discriminative and generative modeling with probabilistic and non-probabilistic NeSy approaches. We utilize NeSy-EBMs to develop a taxonomy of modeling paradigms focusing on a system's neural-symbolic interface and reasoning capabilities. Additionally, we introduce a suite of learning techniques for NeSy-EBMs. Importantly, NeSy-EBMs allow the derivation of general expressions for gradients of prominent learning losses, and we provide four learning approaches that leverage methods from multiple domains, including bilevel and stochastic policy optimization. Finally, we present Neural Probabilistic Soft Logic (NeuPSL), an open-source NeSy-EBM library designed for scalability and expressivity, facilitating real-world application of NeSy systems. Through extensive empirical analysis across multiple datasets, we demonstrate the practical advantages of NeSy-EBMs in various tasks, including image classification, graph node labeling, autonomous vehicle situation awareness, and question answering.