 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
Agents of Change: Self-Evolving LLM Agents for Strategic Planning
Jun 05, 2025Recent advances in LLMs have enabled their use as autonomous agents across a range of tasks, yet they continue to struggle with formulating and adhering to coherent long-term strategies. In this paper, we investigate whether LLM agents can self-improve when placed in environments that explicitly challenge their strategic planning abilities. Using the board game Settlers of Catan, accessed through the open-source Catanatron framework, we benchmark a progression of LLM-based agents, from a simple game-playing agent to systems capable of autonomously rewriting their own prompts and their player agent's code. We introduce a multi-agent architecture in which specialized roles (Analyzer, Researcher, Coder, and Player) collaborate to iteratively analyze gameplay, research new strategies, and modify the agent's logic or prompt. By comparing manually crafted agents to those evolved entirely by LLMs, we evaluate how effectively these systems can diagnose failure and adapt over time. Our results show that self-evolving agents, particularly when powered by models like Claude 3.7 and GPT-4o, outperform static baselines by autonomously adopting their strategies, passing along sample behavior to game-playing agents, and demonstrating adaptive reasoning over multiple iterations.
HardTests: Synthesizing High-Quality Test Cases for LLM Coding
May 30, 2025Verifiers play a crucial role in large language model (LLM) reasoning, needed by post-training techniques such as reinforcement learning. However, reliable verifiers are hard to get for difficult coding problems, because a well-disguised wrong solution may only be detected by carefully human-written edge cases that are difficult to synthesize. To address this issue, we propose HARDTESTGEN, a pipeline for high-quality test synthesis using LLMs. With this pipeline, we curate a comprehensive competitive programming dataset HARDTESTS with 47k problems and synthetic high-quality tests. Compared with existing tests, HARDTESTGEN tests demonstrate precision that is 11.3 percentage points higher and recall that is 17.5 percentage points higher when evaluating LLM-generated code. For harder problems, the improvement in precision can be as large as 40 points. HARDTESTS also proves to be more effective for model training, measured by downstream code generation performance. We will open-source our dataset and synthesis pipeline at https://leililab.github.io/HardTests/.
MessIRve: A Large-Scale Spanish Information Retrieval Dataset
Sep 09, 2024
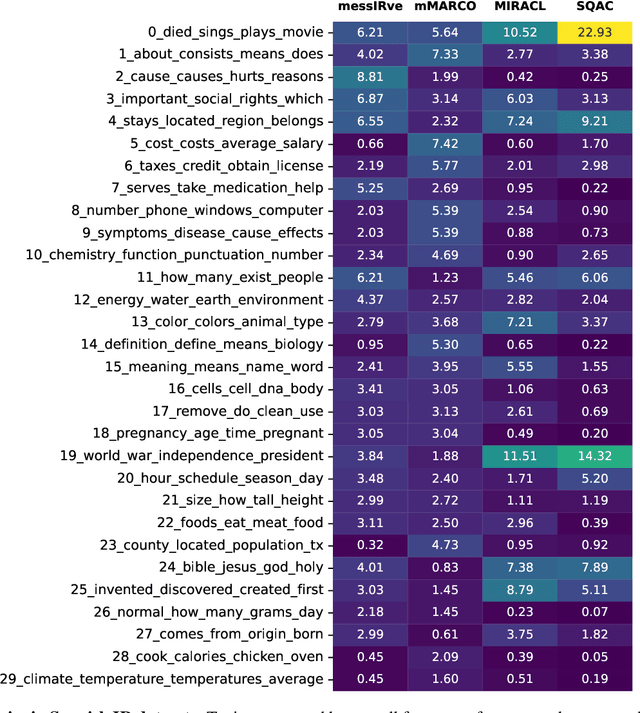

Information retrieval (IR) is the task of finding relevant documents in response to a user query. Although Spanish is the second most spoken native language, current IR benchmarks lack Spanish data, hindering the development of information access tools for Spanish speakers. We introduce MessIRve, a large-scale Spanish IR dataset with around 730 thousand queries from Google's autocomplete API and relevant documents sourced from Wikipedia. MessIRve's queries reflect diverse Spanish-speaking regions, unlike other datasets that are translated from English or do not consider dialectal variations. The large size of the dataset allows it to cover a wide variety of topics, unlike smaller datasets. We provide a comprehensive description of the dataset, comparisons with existing datasets, and baseline evaluations of prominent IR models. Our contributions aim to advance Spanish IR research and improve information access for Spanish speakers.