 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBABE: Biology Arena BEnchmark
Feb 05, 2026The rapid evolution of large language models (LLMs) has expanded their capabilities from basic dialogue to advanced scientific reasoning. However, existing benchmarks in biology often fail to assess a critical skill required of researchers: the ability to integrate experimental results with contextual knowledge to derive meaningful conclusions. To address this gap, we introduce BABE(Biology Arena BEnchmark), a comprehensive benchmark designed to evaluate the experimental reasoning capabilities of biological AI systems. BABE is uniquely constructed from peer-reviewed research papers and real-world biological studies, ensuring that tasks reflect the complexity and interdisciplinary nature of actual scientific inquiry. BABE challenges models to perform causal reasoning and cross-scale inference. Our benchmark provides a robust framework for assessing how well AI systems can reason like practicing scientists, offering a more authentic measure of their potential to contribute to biological research.
SciDA: Scientific Dynamic Assessor of LLMs
Jun 15, 2025Advancement in Large Language Models (LLMs) reasoning capabilities enables them to solve scientific problems with enhanced efficacy. Thereby, a high-quality benchmark for comprehensive and appropriate assessment holds significance, while existing ones either confront the risk of data contamination or lack involved disciplines. To be specific, due to the data source overlap of LLMs training and static benchmark, the keys or number pattern of answers inadvertently memorized (i.e. data contamination), leading to systematic overestimation of their reasoning capabilities, especially numerical reasoning. We propose SciDA, a multidisciplinary benchmark that consists exclusively of over 1k Olympic-level numerical computation problems, allowing randomized numerical initializations for each inference round to avoid reliance on fixed numerical patterns. We conduct a series of experiments with both closed-source and open-source top-performing LLMs, and it is observed that the performance of LLMs drop significantly under random numerical initialization. Thus, we provide truthful and unbiased assessments of the numerical reasoning capabilities of LLMs. The data is available at https://huggingface.co/datasets/m-a-p/SciDA
HardTests: Synthesizing High-Quality Test Cases for LLM Coding
May 30, 2025Verifiers play a crucial role in large language model (LLM) reasoning, needed by post-training techniques such as reinforcement learning. However, reliable verifiers are hard to get for difficult coding problems, because a well-disguised wrong solution may only be detected by carefully human-written edge cases that are difficult to synthesize. To address this issue, we propose HARDTESTGEN, a pipeline for high-quality test synthesis using LLMs. With this pipeline, we curate a comprehensive competitive programming dataset HARDTESTS with 47k problems and synthetic high-quality tests. Compared with existing tests, HARDTESTGEN tests demonstrate precision that is 11.3 percentage points higher and recall that is 17.5 percentage points higher when evaluating LLM-generated code. For harder problems, the improvement in precision can be as large as 40 points. HARDTESTS also proves to be more effective for model training, measured by downstream code generation performance. We will open-source our dataset and synthesis pipeline at https://leililab.github.io/HardTests/.
KORGym: A Dynamic Game Platform for LLM Reasoning Evaluation
May 21, 2025
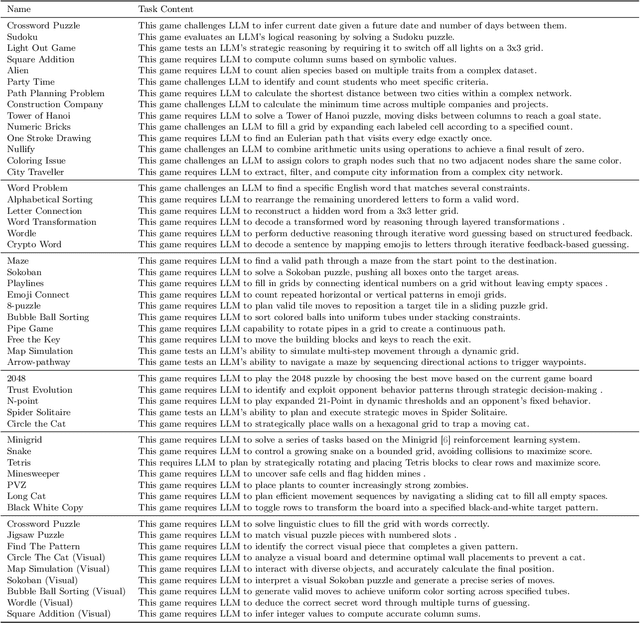
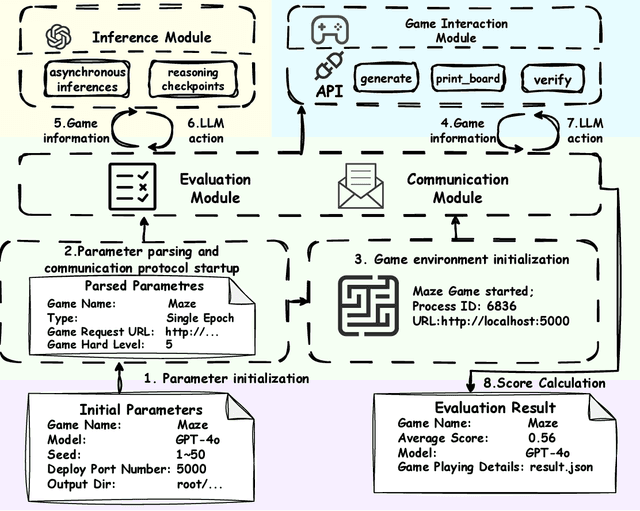

Recent advancements in large language models (LLMs) underscore the need for more comprehensive evaluation methods to accurately assess their reasoning capabilities. Existing benchmarks are often domain-specific and thus cannot fully capture an LLM's general reasoning potential. To address this limitation, we introduce the Knowledge Orthogonal Reasoning Gymnasium (KORGym), a dynamic evaluation platform inspired by KOR-Bench and Gymnasium. KORGym offers over fifty games in either textual or visual formats and supports interactive, multi-turn assessments with reinforcement learning scenarios. Using KORGym, we conduct extensive experiments on 19 LLMs and 8 VLMs, revealing consistent reasoning patterns within model families and demonstrating the superior performance of closed-source models. Further analysis examines the effects of modality, reasoning strategies, reinforcement learning techniques, and response length on model performance. We expect KORGym to become a valuable resource for advancing LLM reasoning research and developing evaluation methodologies suited to complex, interactive environments.
TinyR1-32B-Preview: Boosting Accuracy with Branch-Merge Distillation
Mar 06, 2025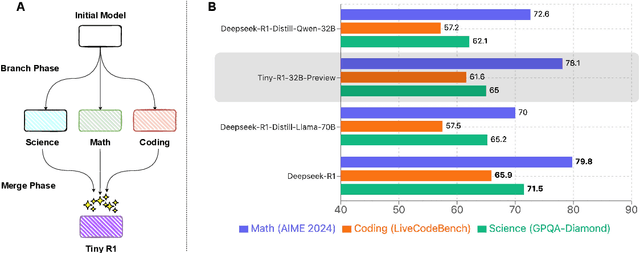
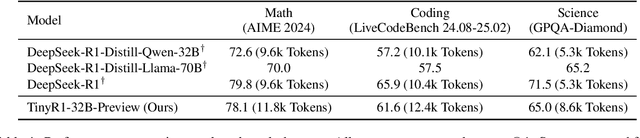
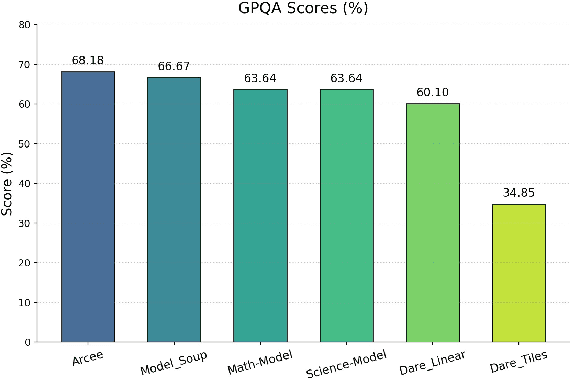
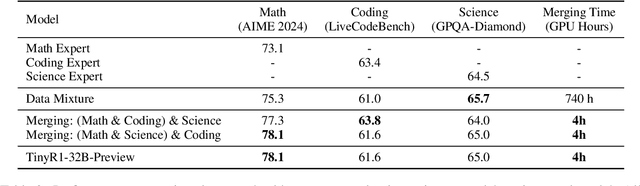
The challenge of reducing the size of Large Language Models (LLMs) while maintaining their performance has gained significant attention. However, existing methods, such as model distillation and transfer learning, often fail to achieve high accuracy. To address this limitation, we introduce the Branch-Merge distillation approach, which enhances model compression through two phases: (1) the Branch Phase, where knowledge from a large teacher model is \textit{selectively distilled} into specialized student models via domain-specific supervised fine-tuning (SFT); And (2) the Merge Phase, where these student models are merged to enable cross-domain knowledge transfer and improve generalization. We validate our distillation approach using DeepSeek-R1 as the teacher and DeepSeek-R1-Distill-Qwen-32B as the student. The resulting merged model, TinyR1-32B-Preview, outperforms its counterpart DeepSeek-R1-Distill-Qwen-32B across multiple benchmarks, including Mathematics (+5.5 points), Coding (+4.4 points) and Science (+2.9 points), while achieving near-equal performance to DeepSeek-R1 on AIME 2024. The Branch-Merge distillation approach provides a scalable solution for creating smaller, high-performing LLMs with reduced computational cost and time.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
CLoG: Benchmarking Continual Learning of Image Generation Models
Jun 07, 2024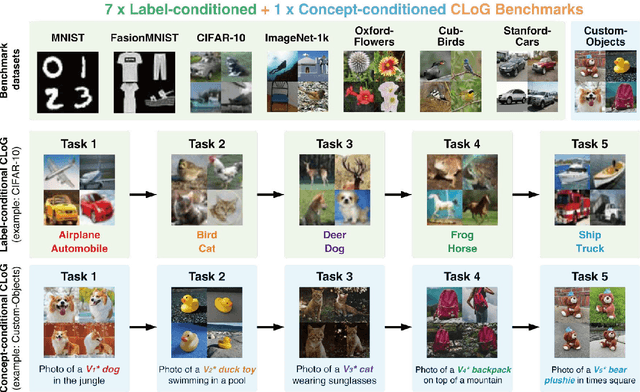
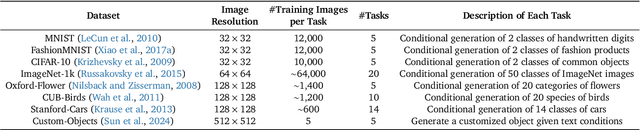
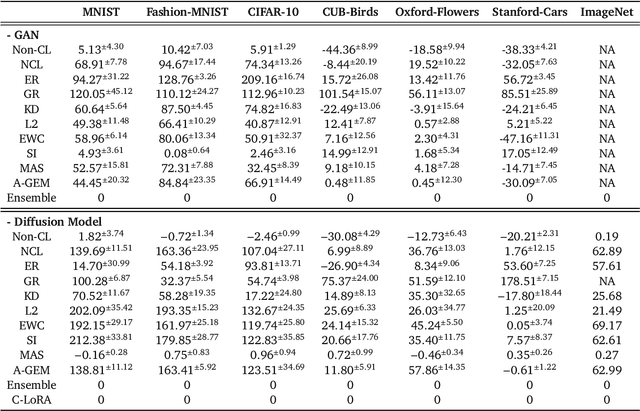

Continual Learning (CL) poses a significant challenge in Artificial Intelligence, aiming to mirror the human ability to incrementally acquire knowledge and skills. While extensive research has focused on CL within the context of classification tasks, the advent of increasingly powerful generative models necessitates the exploration of Continual Learning of Generative models (CLoG). This paper advocates for shifting the research focus from classification-based CL to CLoG. We systematically identify the unique challenges presented by CLoG compared to traditional classification-based CL. We adapt three types of existing CL methodologies, replay-based, regularization-based, and parameter-isolation-based methods to generative tasks and introduce comprehensive benchmarks for CLoG that feature great diversity and broad task coverage. Our benchmarks and results yield intriguing insights that can be valuable for developing future CLoG methods. Additionally, we will release a codebase designed to facilitate easy benchmarking and experimentation in CLoG publicly at https://github.com/linhaowei1/CLoG. We believe that shifting the research focus to CLoG will benefit the continual learning community and illuminate the path for next-generation AI-generated content (AIGC) in a lifelong learning paradigm.
MAP-Neo: Highly Capable and Transparent Bilingual Large Language Model Series
May 29, 2024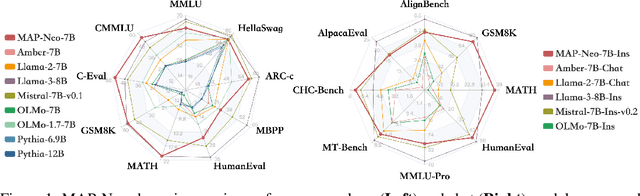

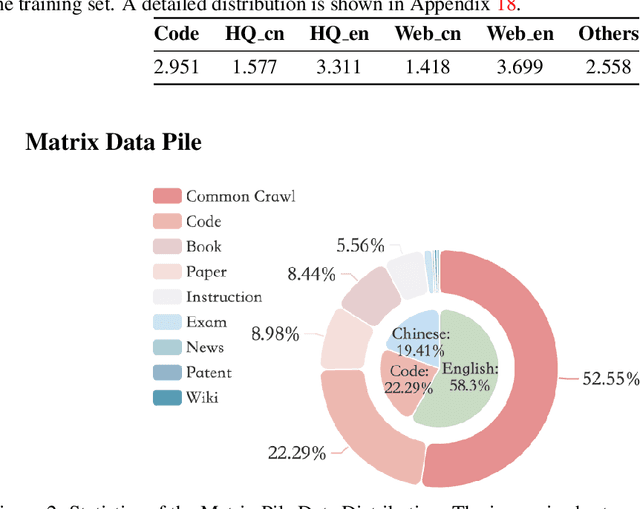
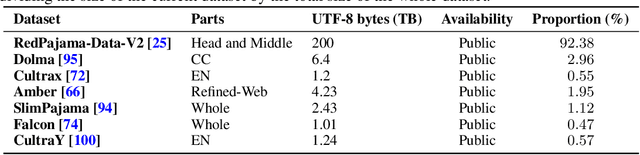
Large Language Models (LLMs) have made great strides in recent years to achieve unprecedented performance across different tasks. However, due to commercial interest, the most competitive models like GPT, Gemini, and Claude have been gated behind proprietary interfaces without disclosing the training details. Recently, many institutions have open-sourced several strong LLMs like LLaMA-3, comparable to existing closed-source LLMs. However, only the model's weights are provided with most details (e.g., intermediate checkpoints, pre-training corpus, and training code, etc.) being undisclosed. To improve the transparency of LLMs, the research community has formed to open-source truly open LLMs (e.g., Pythia, Amber, OLMo), where more details (e.g., pre-training corpus and training code) are being provided. These models have greatly advanced the scientific study of these large models including their strengths, weaknesses, biases and risks. However, we observe that the existing truly open LLMs on reasoning, knowledge, and coding tasks are still inferior to existing state-of-the-art LLMs with similar model sizes. To this end, we open-source MAP-Neo, a highly capable and transparent bilingual language model with 7B parameters trained from scratch on 4.5T high-quality tokens. Our MAP-Neo is the first fully open-sourced bilingual LLM with comparable performance compared to existing state-of-the-art LLMs. Moreover, we open-source all details to reproduce our MAP-Neo, where the cleaned pre-training corpus, data cleaning pipeline, checkpoints, and well-optimized training/evaluation framework are provided. Finally, we hope our MAP-Neo will enhance and strengthen the open research community and inspire more innovations and creativities to facilitate the further improvements of LLMs.
MuPT: A Generative Symbolic Music Pretrained Transformer
Apr 10, 2024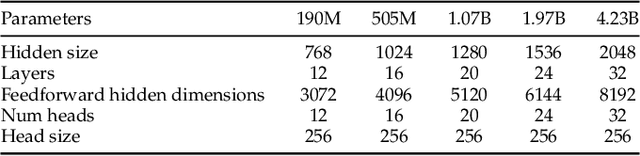

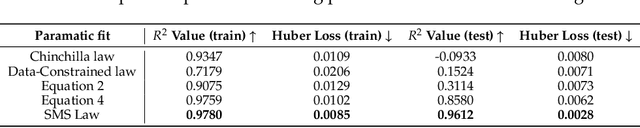
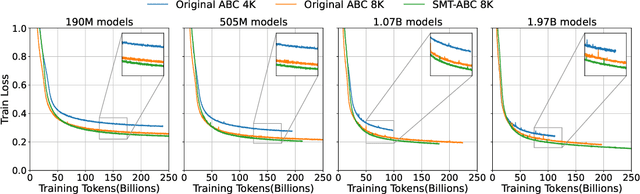
In this paper, we explore the application of Large Language Models (LLMs) to the pre-training of music. While the prevalent use of MIDI in music modeling is well-established, our findings suggest that LLMs are inherently more compatible with ABC Notation, which aligns more closely with their design and strengths, thereby enhancing the model's performance in musical composition. To address the challenges associated with misaligned measures from different tracks during generation, we propose the development of a Synchronized Multi-Track ABC Notation (SMT-ABC Notation), which aims to preserve coherence across multiple musical tracks. Our contributions include a series of models capable of handling up to 8192 tokens, covering 90% of the symbolic music data in our training set. Furthermore, we explore the implications of the Symbolic Music Scaling Law (SMS Law) on model performance. The results indicate a promising direction for future research in music generation, offering extensive resources for community-led research through our open-source contributions.
COIG-CQIA: Quality is All You Need for Chinese Instruction Fine-tuning
Mar 26, 2024
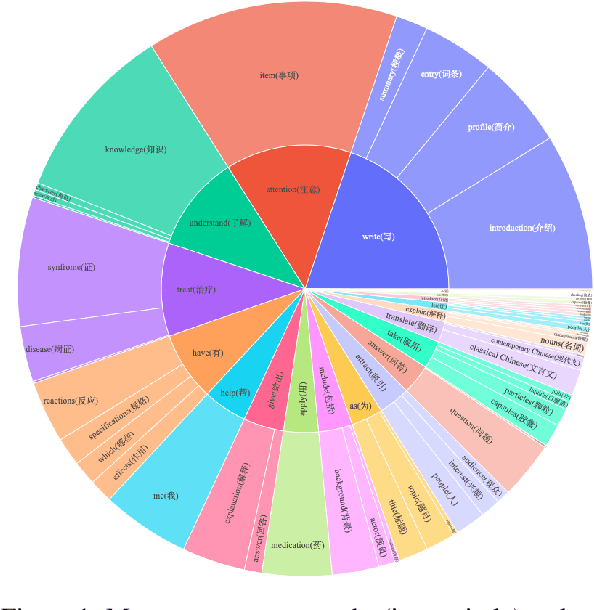
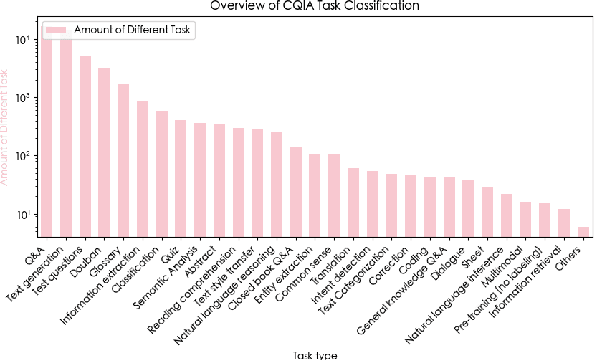

Recently, there have been significant advancements in large language models (LLMs), particularly focused on the English language. These advancements have enabled these LLMs to understand and execute complex instructions with unprecedented accuracy and fluency. However, despite these advancements, there remains a noticeable gap in the development of Chinese instruction tuning. The unique linguistic features and cultural depth of the Chinese language pose challenges for instruction tuning tasks. Existing datasets are either derived from English-centric LLMs or are ill-suited for aligning with the interaction patterns of real-world Chinese users. To bridge this gap, we introduce COIG-CQIA, a high-quality Chinese instruction tuning dataset. Our aim is to build a diverse, wide-ranging instruction-tuning dataset to better align model behavior with human interactions. To this end, we collect a high-quality human-written corpus from various sources on the Chinese Internet, including Q&A communities, Wikis, examinations, and existing NLP datasets. This corpus was rigorously filtered and carefully processed to form the COIG-CQIA dataset. Furthermore, we train models of various scales on different subsets of CQIA, following in-depth evaluation and analyses. The findings from our experiments offer valuable insights for selecting and developing Chinese instruction-tuning datasets. We also find that models trained on CQIA-Subset achieve competitive results in human assessment as well as knowledge and security benchmarks. Data are available at https://huggingface.co/datasets/m-a-p/COIG-CQIA