 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuPT: A Generative Symbolic Music Pretrained Transformer
Apr 10, 2024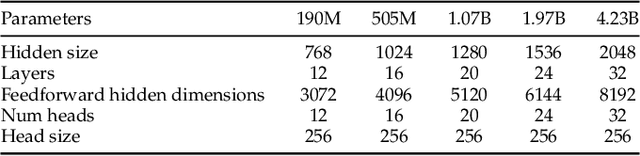

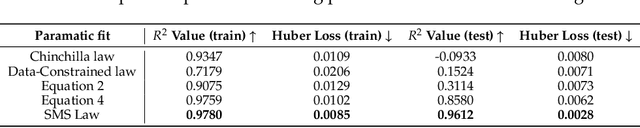
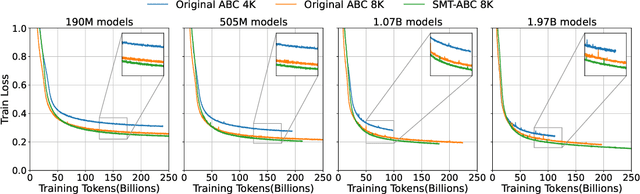
In this paper, we explore the application of Large Language Models (LLMs) to the pre-training of music. While the prevalent use of MIDI in music modeling is well-established, our findings suggest that LLMs are inherently more compatible with ABC Notation, which aligns more closely with their design and strengths, thereby enhancing the model's performance in musical composition. To address the challenges associated with misaligned measures from different tracks during generation, we propose the development of a Synchronized Multi-Track ABC Notation (SMT-ABC Notation), which aims to preserve coherence across multiple musical tracks. Our contributions include a series of models capable of handling up to 8192 tokens, covering 90% of the symbolic music data in our training set. Furthermore, we explore the implications of the Symbolic Music Scaling Law (SMS Law) on model performance. The results indicate a promising direction for future research in music generation, offering extensive resources for community-led research through our open-source contributions.
CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
Apr 06, 2024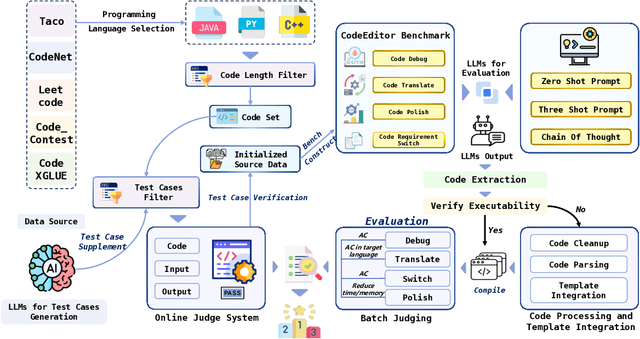
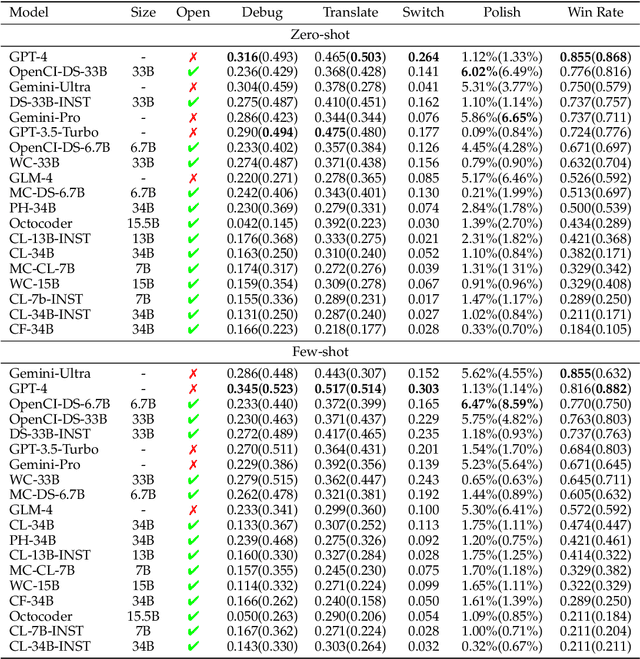
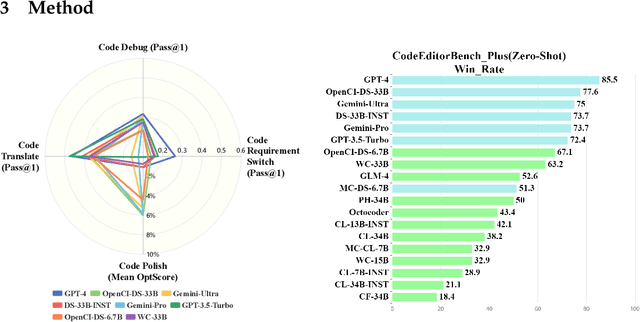

Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.
OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement
Feb 28, 2024



The introduction of large language models has significantly advanced code generation. However, open-source models often lack the execution capabilities and iterative refinement of advanced systems like the GPT-4 Code Interpreter. To address this, we introduce OpenCodeInterpreter, a family of open-source code systems designed for generating, executing, and iteratively refining code. Supported by Code-Feedback, a dataset featuring 68K multi-turn interactions, OpenCodeInterpreter integrates execution and human feedback for dynamic code refinement. Our comprehensive evaluation of OpenCodeInterpreter across key benchmarks such as HumanEval, MBPP, and their enhanced versions from EvalPlus reveals its exceptional performance. Notably, OpenCodeInterpreter-33B achieves an accuracy of 83.2 (76.4) on the average (and plus versions) of HumanEval and MBPP, closely rivaling GPT-4's 84.2 (76.2) and further elevates to 91.6 (84.6) with synthesized human feedback from GPT-4. OpenCodeInterpreter brings the gap between open-source code generation models and proprietary systems like GPT-4 Code Interpreter.
A Fully-Automatic Framework for Parkinson's Disease Diagnosis by Multi-Modality Images
Feb 26, 2019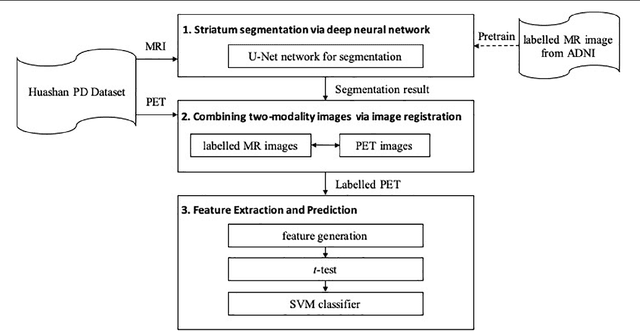
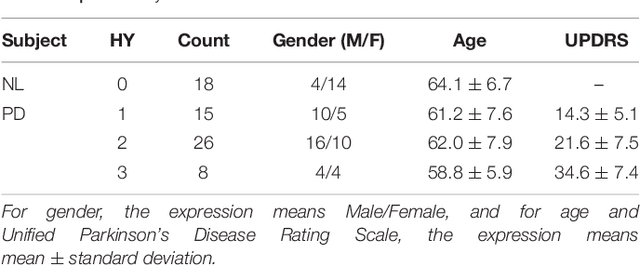
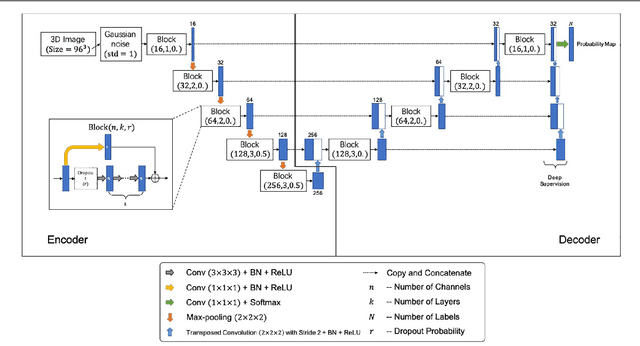
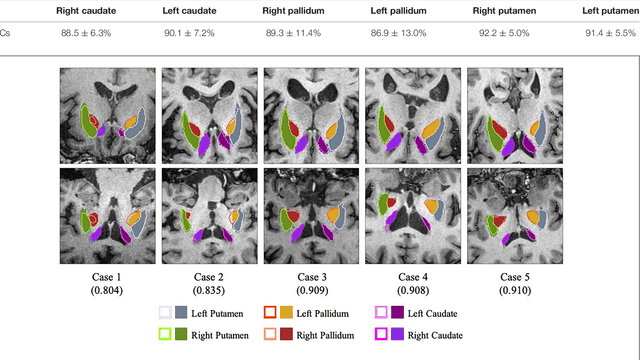
Background: Parkinson's disease (PD) is a prevalent long-term neurodegenerative disease. Though the diagnostic criteria of PD are relatively well defined, the current medical imaging diagnostic procedures are expertise-demanding, and thus call for a higher-integrated AI-based diagnostic algorithm. Methods: In this paper, we proposed an automatic, end-to-end, multi-modality diagnosis framework, including segmentation, registration, feature generation and machine learning, to process the information of the striatum for the diagnosis of PD. Multiple modalities, including T1- weighted MRI and 11C-CFT PET, were used in the proposed framework. The reliability of this framework was then validated on a dataset from the PET center of Huashan Hospital, as the dataset contains paired T1-MRI and CFT-PET images of 18 Normal (NL) subjects and 49 PD subjects. Results: We obtained an accuracy of 100% for the PD/NL classification task, besides, we conducted several comparative experiments to validate the diagnosis ability of our framework. Conclusion: Through experiment we illustrate that (1) automatic segmentation has the same classification effect as the manual segmentation, (2) the multi-modality images generates a better prediction than single modality images, and (3) volume feature is shown to be irrelevant to PD diagnosis.