 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Control Points-based 6DoF Pose Tracking for Industrial Metal Objects
Jul 02, 2025Visual pose tracking is playing an increasingly vital role in industrial contexts in recent years. However, the pose tracking for industrial metal objects remains a challenging task especially in the real world-environments, due to the reflection characteristic of metal objects. To address this issue, we propose a novel 6DoF pose tracking method based on active control points. The method uses image control points to generate edge feature for optimization actively instead of 6DoF pose-based rendering, and serve them as optimization variables. We also introduce an optimal control point regression method to improve robustness. The proposed tracking method performs effectively in both dataset evaluation and real world tasks, providing a viable solution for real-time tracking of industrial metal objects. Our source code is made publicly available at: https://github.com/tomatoma00/ACPTracking.
COIG-P: A High-Quality and Large-Scale Chinese Preference Dataset for Alignment with Human Values
Apr 07, 2025Aligning large language models (LLMs) with human preferences has achieved remarkable success. However, existing Chinese preference datasets are limited by small scale, narrow domain coverage, and lack of rigorous data validation. Additionally, the reliance on human annotators for instruction and response labeling significantly constrains the scalability of human preference datasets. To address these challenges, we design an LLM-based Chinese preference dataset annotation pipeline with no human intervention. Specifically, we crawled and carefully filtered 92k high-quality Chinese queries and employed 15 mainstream LLMs to generate and score chosen-rejected response pairs. Based on it, we introduce COIG-P (Chinese Open Instruction Generalist - Preference), a high-quality, large-scale Chinese preference dataset, comprises 1,009k Chinese preference pairs spanning 6 diverse domains: Chat, Code, Math, Logic, Novel, and Role. Building upon COIG-P, to reduce the overhead of using LLMs for scoring, we trained a 8B-sized Chinese Reward Model (CRM) and meticulously constructed a Chinese Reward Benchmark (CRBench). Evaluation results based on AlignBench \citep{liu2024alignbenchbenchmarkingchinesealignment} show that that COIG-P significantly outperforms other Chinese preference datasets, and it brings significant performance improvements ranging from 2% to 12% for the Qwen2/2.5 and Infinity-Instruct-3M-0625 model series, respectively. The results on CRBench demonstrate that our CRM has a strong and robust scoring ability. We apply it to filter chosen-rejected response pairs in a test split of COIG-P, and our experiments show that it is comparable to GPT-4o in identifying low-quality samples while maintaining efficiency and cost-effectiveness. Our codes and data are released in https://github.com/multimodal-art-projection/COIG-P.
Deep generative modelling of canonical ensemble with differentiable thermal properties
Apr 29, 2024We propose a variational modelling method with differentiable temperature for canonical ensembles. Using a deep generative model, the free energy is estimated and minimized simultaneously in a continuous temperature range. At optimal, this generative model is a Boltzmann distribution with temperature dependence. The training process requires no dataset, and works with arbitrary explicit density generative models. We applied our method to study the phase transitions (PT) in the Ising and XY models, and showed that the direct-sampling simulation of our model is as accurate as the Markov Chain Monte Carlo (MCMC) simulation, but more efficient. Moreover, our method can give thermodynamic quantities as differentiable functions of temperature akin to an analytical solution. The free energy aligns closely with the exact one to the second-order derivative, so this inclusion of temperature dependence enables the otherwise biased variational model to capture the subtle thermal effects at the PTs. These findings shed light on the direct simulation of physical systems using deep generative models
Chinese Tiny LLM: Pretraining a Chinese-Centric Large Language Model
Apr 09, 2024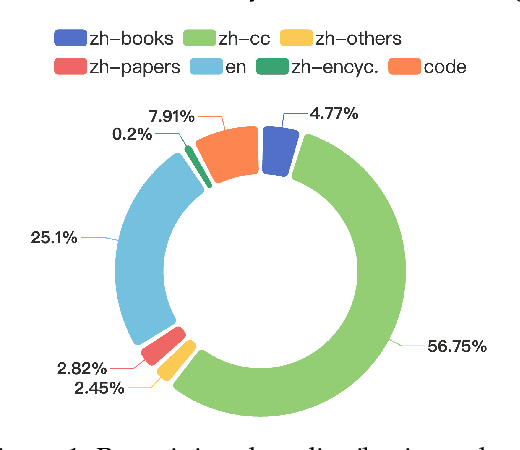

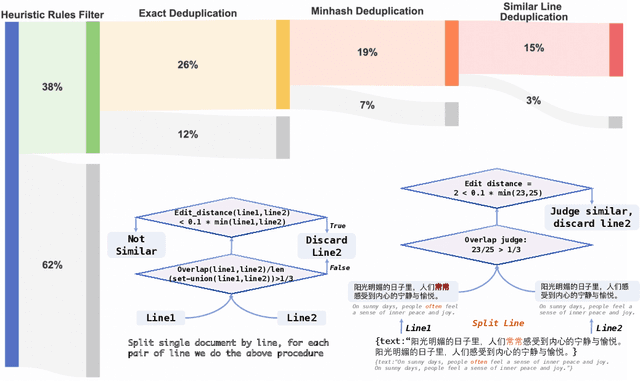

In this study, we introduce CT-LLM, a 2B large language model (LLM) that illustrates a pivotal shift towards prioritizing the Chinese language in developing LLMs. Uniquely initiated from scratch, CT-LLM diverges from the conventional methodology by primarily incorporating Chinese textual data, utilizing an extensive corpus of 1,200 billion tokens, including 800 billion Chinese tokens, 300 billion English tokens, and 100 billion code tokens. This strategic composition facilitates the model's exceptional proficiency in understanding and processing Chinese, a capability further enhanced through alignment techniques. Demonstrating remarkable performance on the CHC-Bench, CT-LLM excels in Chinese language tasks, and showcases its adeptness in English through SFT. This research challenges the prevailing paradigm of training LLMs predominantly on English corpora and then adapting them to other languages, broadening the horizons for LLM training methodologies. By open-sourcing the full process of training a Chinese LLM, including a detailed data processing procedure with the obtained Massive Appropriate Pretraining Chinese Corpus (MAP-CC), a well-chosen multidisciplinary Chinese Hard Case Benchmark (CHC-Bench), and the 2B-size Chinese Tiny LLM (CT-LLM), we aim to foster further exploration and innovation in both academia and industry, paving the way for more inclusive and versatile language models.
CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
Apr 06, 2024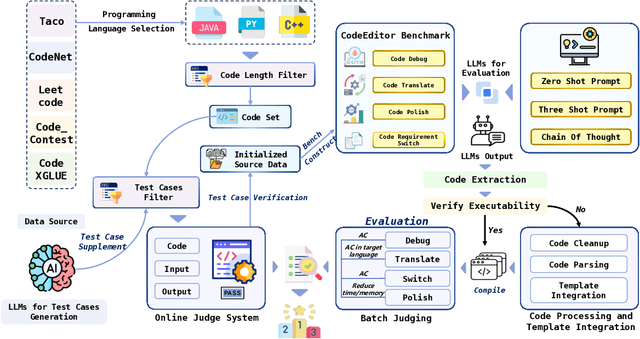
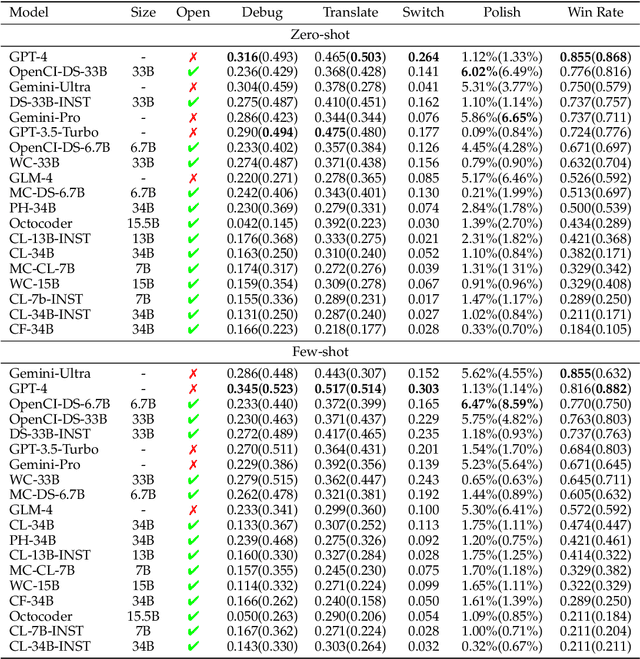
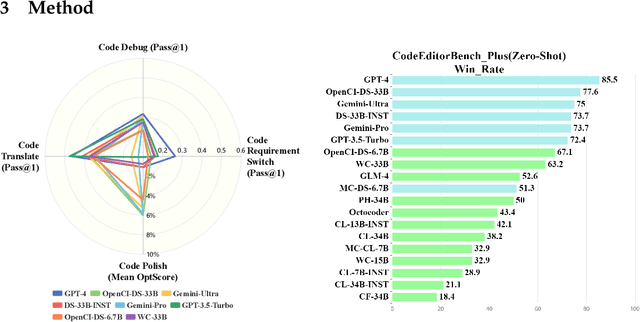

Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.
Probing Deep Speaker Embeddings for Speaker-related Tasks
Dec 14, 2022



Deep speaker embeddings have shown promising results in speaker recognition, as well as in other speaker-related tasks. However, some issues are still under explored, for instance, the information encoded in these representations and their influence on downstream tasks. Four deep speaker embeddings are studied in this paper, namely, d-vector, x-vector, ResNetSE-34 and ECAPA-TDNN. Inspired by human voice mechanisms, we explored possibly encoded information from perspectives of identity, contents and channels; Based on this, experiments were conducted on three categories of speaker-related tasks to further explore impacts of different deep embeddings, including discriminative tasks (speaker verification and diarization), guiding tasks (target speaker detection and extraction) and regulating tasks (multi-speaker text-to-speech). Results show that all deep embeddings encoded channel and content information in addition to speaker identity, but the extent could vary and their performance on speaker-related tasks can be tremendously different: ECAPA-TDNN is dominant in discriminative tasks, and d-vector leads the guiding tasks, while regulating task is less sensitive to the choice of speaker representations. These may benefit future research utilizing speaker embeddings.