 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Latent Reasoning via Looped Language Models
Oct 29, 2025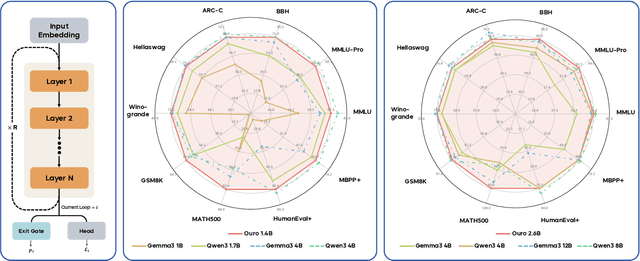
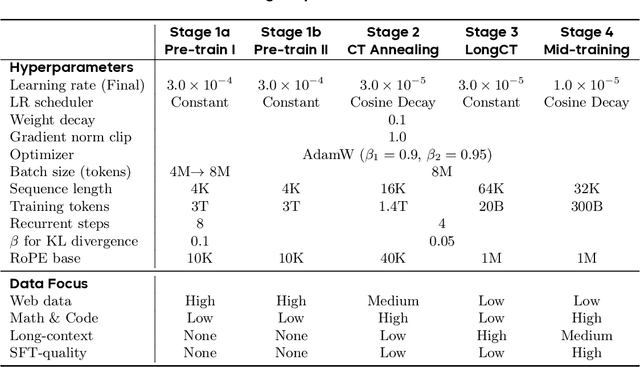
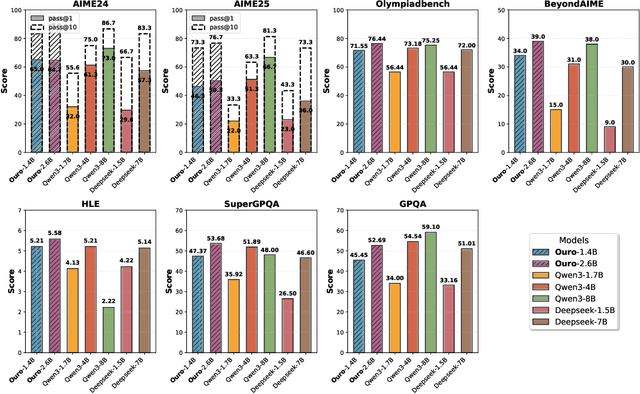

Modern LLMs are trained to "think" primarily via explicit text generation, such as chain-of-thought (CoT), which defers reasoning to post-training and under-leverages pre-training data. We present and open-source Ouro, named after the recursive Ouroboros, a family of pre-trained Looped Language Models (LoopLM) that instead build reasoning into the pre-training phase through (i) iterative computation in latent space, (ii) an entropy-regularized objective for learned depth allocation, and (iii) scaling to 7.7T tokens. Ouro 1.4B and 2.6B models enjoy superior performance that match the results of up to 12B SOTA LLMs across a wide range of benchmarks. Through controlled experiments, we show this advantage stems not from increased knowledge capacity, but from superior knowledge manipulation capabilities. We also show that LoopLM yields reasoning traces more aligned with final outputs than explicit CoT. We hope our results show the potential of LoopLM as a novel scaling direction in the reasoning era. Our model could be found in: http://ouro-llm.github.io.
Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving
Aug 01, 2025LLMs have demonstrated strong mathematical reasoning abilities by leveraging reinforcement learning with long chain-of-thought, yet they continue to struggle with theorem proving due to the lack of clear supervision signals when solely using natural language. Dedicated domain-specific languages like Lean provide clear supervision via formal verification of proofs, enabling effective training through reinforcement learning. In this work, we propose \textbf{Seed-Prover}, a lemma-style whole-proof reasoning model. Seed-Prover can iteratively refine its proof based on Lean feedback, proved lemmas, and self-summarization. To solve IMO-level contest problems, we design three test-time inference strategies that enable both deep and broad reasoning. Seed-Prover proves $78.1\%$ of formalized past IMO problems, saturates MiniF2F, and achieves over 50\% on PutnamBench, outperforming the previous state-of-the-art by a large margin. To address the lack of geometry support in Lean, we introduce a geometry reasoning engine \textbf{Seed-Geometry}, which outperforms previous formal geometry engines. We use these two systems to participate in IMO 2025 and fully prove 5 out of 6 problems. This work represents a significant advancement in automated mathematical reasoning, demonstrating the effectiveness of formal verification with long chain-of-thought reasoning.
CriticLean: Critic-Guided Reinforcement Learning for Mathematical Formalization
Jul 08, 2025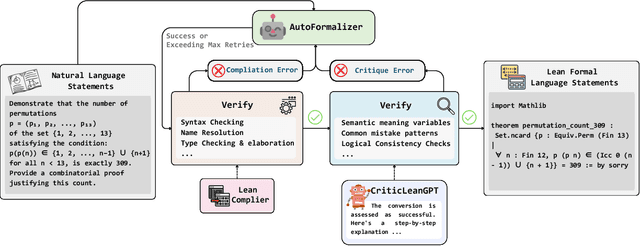

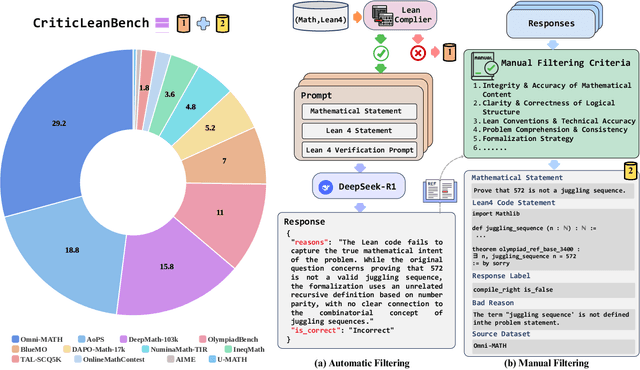
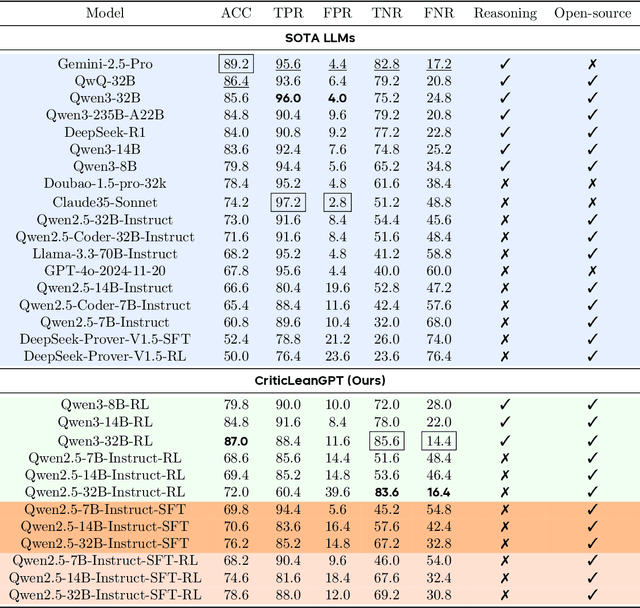
Translating natural language mathematical statements into formal, executable code is a fundamental challenge in automated theorem proving. While prior work has focused on generation and compilation success, little attention has been paid to the critic phase-the evaluation of whether generated formalizations truly capture the semantic intent of the original problem. In this paper, we introduce CriticLean, a novel critic-guided reinforcement learning framework that elevates the role of the critic from a passive validator to an active learning component. Specifically, first, we propose the CriticLeanGPT, trained via supervised fine-tuning and reinforcement learning, to rigorously assess the semantic fidelity of Lean 4 formalizations. Then, we introduce CriticLeanBench, a benchmark designed to measure models' ability to distinguish semantically correct from incorrect formalizations, and demonstrate that our trained CriticLeanGPT models can significantly outperform strong open- and closed-source baselines. Building on the CriticLean framework, we construct FineLeanCorpus, a dataset comprising over 285K problems that exhibits rich domain diversity, broad difficulty coverage, and high correctness based on human evaluation. Overall, our findings highlight that optimizing the critic phase is essential for producing reliable formalizations, and we hope our CriticLean will provide valuable insights for future advances in formal mathematical reasoning.
CoMo: Learning Continuous Latent Motion from Internet Videos for Scalable Robot Learning
May 22, 2025Learning latent motion from Internet videos is crucial for building generalist robots. However, existing discrete latent action methods suffer from information loss and struggle with complex and fine-grained dynamics. We propose CoMo, which aims to learn more informative continuous motion representations from diverse, internet-scale videos. CoMo employs a early temporal feature difference mechanism to prevent model collapse and suppress static appearance noise, effectively discouraging shortcut learning problem. Furthermore, guided by the information bottleneck principle, we constrain the latent motion embedding dimensionality to achieve a better balance between retaining sufficient action-relevant information and minimizing the inclusion of action-irrelevant appearance noise. Additionally, we also introduce two new metrics for more robustly and affordably evaluating motion and guiding motion learning methods development: (i) the linear probing MSE of action prediction, and (ii) the cosine similarity between past-to-current and future-to-current motion embeddings. Critically, CoMo exhibits strong zero-shot generalization, enabling it to generate continuous pseudo actions for previously unseen video domains. This capability facilitates unified policy joint learning using pseudo actions derived from various action-less video datasets (such as cross-embodiment videos and, notably, human demonstration videos), potentially augmented with limited labeled robot data. Extensive experiments show that policies co-trained with CoMo pseudo actions achieve superior performance with both diffusion and autoregressive architectures in simulated and real-world settings.
KORGym: A Dynamic Game Platform for LLM Reasoning Evaluation
May 21, 2025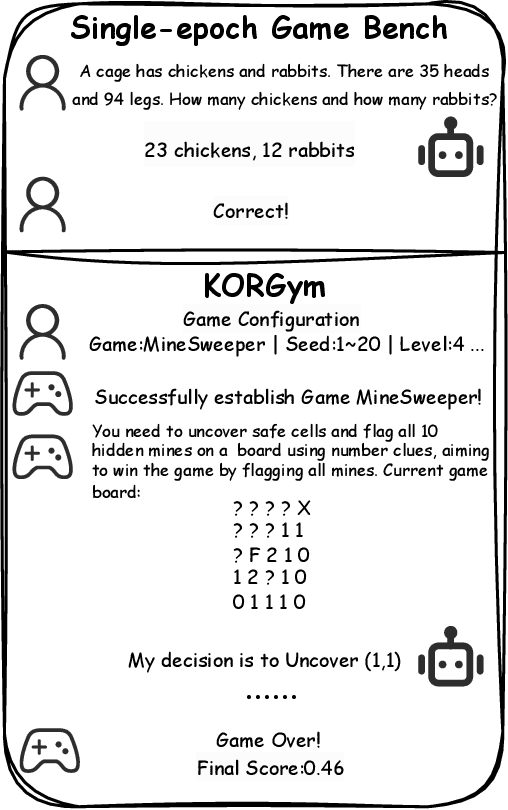
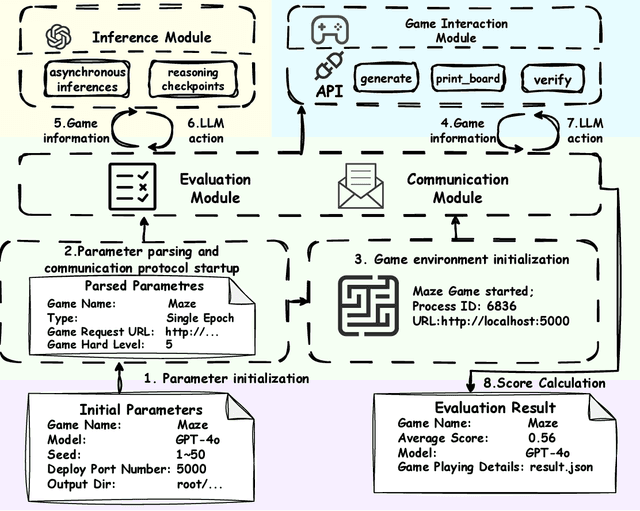

Recent advancements in large language models (LLMs) underscore the need for more comprehensive evaluation methods to accurately assess their reasoning capabilities. Existing benchmarks are often domain-specific and thus cannot fully capture an LLM's general reasoning potential. To address this limitation, we introduce the Knowledge Orthogonal Reasoning Gymnasium (KORGym), a dynamic evaluation platform inspired by KOR-Bench and Gymnasium. KORGym offers over fifty games in either textual or visual formats and supports interactive, multi-turn assessments with reinforcement learning scenarios. Using KORGym, we conduct extensive experiments on 19 LLMs and 8 VLMs, revealing consistent reasoning patterns within model families and demonstrating the superior performance of closed-source models. Further analysis examines the effects of modality, reasoning strategies, reinforcement learning techniques, and response length on model performance. We expect KORGym to become a valuable resource for advancing LLM reasoning research and developing evaluation methodologies suited to complex, interactive environments.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
KARPA: A Training-free Method of Adapting Knowledge Graph as References for Large Language Model's Reasoning Path Aggregation
Dec 30, 2024Large language models (LLMs) demonstrate exceptional performance across a variety of tasks, yet they are often affected by hallucinations and the timeliness of knowledge. Leveraging knowledge graphs (KGs) as external knowledge sources has emerged as a viable solution, but existing methods for LLM-based knowledge graph question answering (KGQA) are often limited by step-by-step decision-making on KGs, restricting the global planning and reasoning capabilities of LLMs, or they require fine-tuning or pre-training on specific KGs. To address these challenges, we propose Knowledge graph Assisted Reasoning Path Aggregation (KARPA), a novel framework that harnesses the global planning abilities of LLMs for efficient and accurate KG reasoning. KARPA operates in three steps: pre-planning relation paths using the LLM's global planning capabilities, matching semantically relevant paths via an embedding model, and reasoning over these paths to generate answers. Unlike existing KGQA methods, KARPA avoids stepwise traversal, requires no additional training, and is adaptable to various LLM architectures. Extensive experimental results show that KARPA achieves state-of-the-art performance in KGQA tasks, delivering both high efficiency and accuracy. Our code will be available on Github.
Trusted Unified Feature-Neighborhood Dynamics for Multi-View Classification
Sep 01, 2024Multi-view classification (MVC) faces inherent challenges due to domain gaps and inconsistencies across different views, often resulting in uncertainties during the fusion process. While Evidential Deep Learning (EDL) has been effective in addressing view uncertainty, existing methods predominantly rely on the Dempster-Shafer combination rule, which is sensitive to conflicting evidence and often neglects the critical role of neighborhood structures within multi-view data. To address these limitations, we propose a Trusted Unified Feature-NEighborhood Dynamics (TUNED) model for robust MVC. This method effectively integrates local and global feature-neighborhood (F-N) structures for robust decision-making. Specifically, we begin by extracting local F-N structures within each view. To further mitigate potential uncertainties and conflicts in multi-view fusion, we employ a selective Markov random field that adaptively manages cross-view neighborhood dependencies. Additionally, we employ a shared parameterized evidence extractor that learns global consensus conditioned on local F-N structures, thereby enhancing the global integration of multi-view features. Experiments on benchmark datasets show that our method improves accuracy and robustness over existing approaches, particularly in scenarios with high uncertainty and conflicting views. The code will be made available at https://github.com/JethroJames/TUNED.
Beyond Uncertainty: Evidential Deep Learning for Robust Video Temporal Grounding
Aug 29, 2024Existing Video Temporal Grounding (VTG) models excel in accuracy but often overlook open-world challenges posed by open-vocabulary queries and untrimmed videos. This leads to unreliable predictions for noisy, corrupted, and out-of-distribution data. Adapting VTG models to dynamically estimate uncertainties based on user input can address this issue. To this end, we introduce SRAM, a robust network module that benefits from a two-stage cross-modal alignment task. More importantly, it integrates Deep Evidential Regression (DER) to explicitly and thoroughly quantify uncertainty during training, thus allowing the model to say "I do not know" in scenarios beyond its handling capacity. However, the direct application of traditional DER theory and its regularizer reveals structural flaws, leading to unintended constraints in VTG tasks. In response, we develop a simple yet effective Geom-regularizer that enhances the uncertainty learning framework from the ground up. To the best of our knowledge, this marks the first successful attempt of DER in VTG. Our extensive quantitative and qualitative results affirm the effectiveness, robustness, and interpretability of our modules and the uncertainty learning paradigm in VTG tasks. The code will be made available.
Disentangle and denoise: Tackling context misalignment for video moment retrieval
Aug 14, 2024Video Moment Retrieval, which aims to locate in-context video moments according to a natural language query, is an essential task for cross-modal grounding. Existing methods focus on enhancing the cross-modal interactions between all moments and the textual description for video understanding. However, constantly interacting with all locations is unreasonable because of uneven semantic distribution across the timeline and noisy visual backgrounds. This paper proposes a cross-modal Context Denoising Network (CDNet) for accurate moment retrieval by disentangling complex correlations and denoising irrelevant dynamics.Specifically, we propose a query-guided semantic disentanglement (QSD) to decouple video moments by estimating alignment levels according to the global and fine-grained correlation. A Context-aware Dynamic Denoisement (CDD) is proposed to enhance understanding of aligned spatial-temporal details by learning a group of query-relevant offsets. Extensive experiments on public benchmarks demonstrate that the proposed CDNet achieves state-of-the-art performances.