 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws for Differentially Private Language Models
Jan 31, 2025Scaling laws have emerged as important components of large language model (LLM) training as they can predict performance gains through scale, and provide guidance on important hyper-parameter choices that would otherwise be expensive. LLMs also rely on large, high-quality training datasets, like those sourced from (sometimes sensitive) user data. Training models on this sensitive user data requires careful privacy protections like differential privacy (DP). However, the dynamics of DP training are significantly different, and consequently their scaling laws are not yet fully understood. In this work, we establish scaling laws that accurately model the intricacies of DP LLM training, providing a complete picture of the compute-privacy-utility tradeoffs and the optimal training configurations in many settings.
MMRA: A Benchmark for Evaluating Multi-Granularity and Multi-Image Relational Association Capabilities in Large Visual Language Models
Aug 06, 2024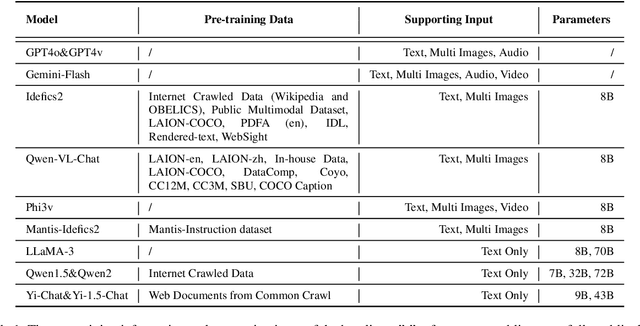



Given the remarkable success that large visual language models (LVLMs) have achieved in image perception tasks, the endeavor to make LVLMs perceive the world like humans is drawing increasing attention. Current multi-modal benchmarks primarily focus on facts or specific topic-related knowledge contained within individual images. However, they often overlook the associative relations between multiple images, which require the identification and analysis of similarities among entities or content present in different images. Therefore, we propose the multi-image relation association task and a meticulously curated Multi-granularity Multi-image Relational Association (MMRA) benchmark, comprising 1,024 samples. In order to systematically and comprehensively evaluate current LVLMs, we establish an associational relation system among images that contain 11 subtasks (e.g, UsageSimilarity, SubEvent) at two granularity levels (i.e., image and entity) according to the relations in ConceptNet. Our experiments reveal that on the MMRA benchmark, current multi-image LVLMs exhibit distinct advantages and disadvantages across various subtasks. Notably, fine-grained, entity-level multi-image perception tasks pose a greater challenge for LVLMs compared to image-level tasks. Moreover, LVLMs perform poorly on spatial-related tasks, indicating that LVLMs still have limited spatial awareness. Additionally, our findings indicate that while LVLMs demonstrate a strong capability to perceive image details, enhancing their ability to associate information across multiple images hinges on improving the reasoning capabilities of their language model component. Moreover, we explored the ability of LVLMs to perceive image sequences within the context of our multi-image association task. Our experiments show that the majority of current LVLMs do not adequately model image sequences during the pre-training process.
MMRA: A Benchmark for Multi-granularity Multi-image Relational Association
Jul 24, 2024Given the remarkable success that large visual language models (LVLMs) have achieved in image perception tasks, the endeavor to make LVMLs perceive the world like humans is drawing increasing attention. Current multi-modal benchmarks mainly focus on the objective fact or certain topic related potential knowledge within a image, but overlook the associative relations between multiple images. Therefore, we define a multi-image relation association task, and meticulously curate \textbf{MMRA} benchmark, a \textbf{M}ulti-granularity \textbf{M}ulti-image \textbf{R}elational \textbf{A}ssociation benchmark, consisted of \textbf{1026} samples. In order to systematically and comprehensively evaluate mainstream LVLMs, we establish an associational relation system among images that contain \textbf{11 subtasks} (e.g, UsageSimilarity, SubEvent, etc.) at two granularity levels (i.e., "\textbf{image}" and "\textbf{entity}") according to the relations in ConceptNet. Our experiments demonstrate that, on our MMRA benchmark, current mainstream LVLMs all have their own advantages and disadvantages across different subtasks. It is worth noting that, at the entity level, the performance of all models is worse than that of them at the image level, indicating that the fine-grained multi-image perception task is still challenging for LVLMs. The tasks related to spatial perception are relatively difficult for LVLMs to handle. Furthermore, we find that LVMLs exhibit a good ability to perceive image details, and the key to enhancing their multi-image association capability is to strengthen the reasoning ability of their language model component. All our codes and data are released at htt\url{https://github.com/Wusiwei0410/MMRA}.
II-Bench: An Image Implication Understanding Benchmark for Multimodal Large Language Models
Jun 11, 2024
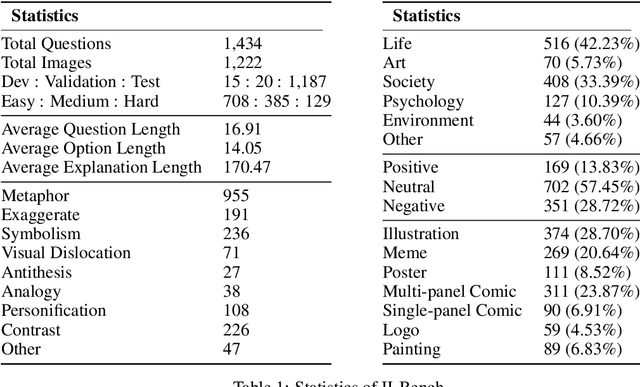
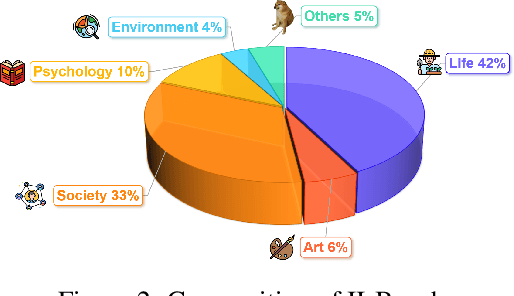
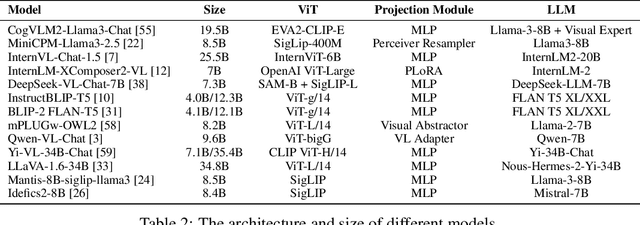
The rapid advancements in the development of multimodal large language models (MLLMs) have consistently led to new breakthroughs on various benchmarks. In response, numerous challenging and comprehensive benchmarks have been proposed to more accurately assess the capabilities of MLLMs. However, there is a dearth of exploration of the higher-order perceptual capabilities of MLLMs. To fill this gap, we propose the Image Implication understanding Benchmark, II-Bench, which aims to evaluate the model's higher-order perception of images. Through extensive experiments on II-Bench across multiple MLLMs, we have made significant findings. Initially, a substantial gap is observed between the performance of MLLMs and humans on II-Bench. The pinnacle accuracy of MLLMs attains 74.8%, whereas human accuracy averages 90%, peaking at an impressive 98%. Subsequently, MLLMs perform worse on abstract and complex images, suggesting limitations in their ability to understand high-level semantics and capture image details. Finally, it is observed that most models exhibit enhanced accuracy when image sentiment polarity hints are incorporated into the prompts. This observation underscores a notable deficiency in their inherent understanding of image sentiment. We believe that II-Bench will inspire the community to develop the next generation of MLLMs, advancing the journey towards expert artificial general intelligence (AGI). II-Bench is publicly available at https://huggingface.co/datasets/m-a-p/II-Bench.
MAP-Neo: Highly Capable and Transparent Bilingual Large Language Model Series
May 29, 2024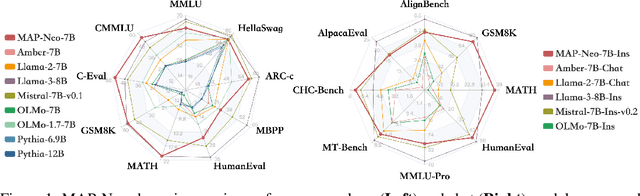

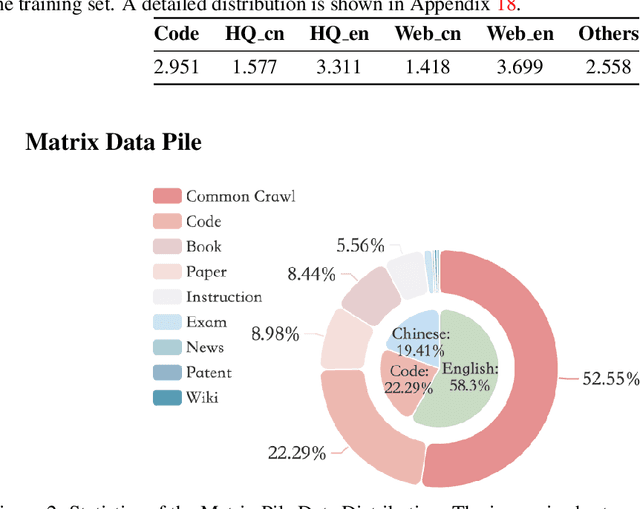
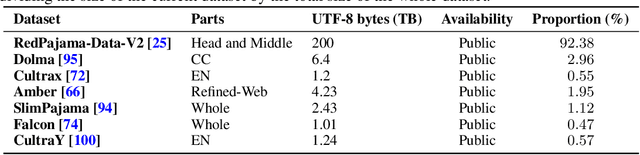
Large Language Models (LLMs) have made great strides in recent years to achieve unprecedented performance across different tasks. However, due to commercial interest, the most competitive models like GPT, Gemini, and Claude have been gated behind proprietary interfaces without disclosing the training details. Recently, many institutions have open-sourced several strong LLMs like LLaMA-3, comparable to existing closed-source LLMs. However, only the model's weights are provided with most details (e.g., intermediate checkpoints, pre-training corpus, and training code, etc.) being undisclosed. To improve the transparency of LLMs, the research community has formed to open-source truly open LLMs (e.g., Pythia, Amber, OLMo), where more details (e.g., pre-training corpus and training code) are being provided. These models have greatly advanced the scientific study of these large models including their strengths, weaknesses, biases and risks. However, we observe that the existing truly open LLMs on reasoning, knowledge, and coding tasks are still inferior to existing state-of-the-art LLMs with similar model sizes. To this end, we open-source MAP-Neo, a highly capable and transparent bilingual language model with 7B parameters trained from scratch on 4.5T high-quality tokens. Our MAP-Neo is the first fully open-sourced bilingual LLM with comparable performance compared to existing state-of-the-art LLMs. Moreover, we open-source all details to reproduce our MAP-Neo, where the cleaned pre-training corpus, data cleaning pipeline, checkpoints, and well-optimized training/evaluation framework are provided. Finally, we hope our MAP-Neo will enhance and strengthen the open research community and inspire more innovations and creativities to facilitate the further improvements of LLMs.
Best Practices and Lessons Learned on Synthetic Data for Language Models
Apr 11, 2024
The success of AI models relies on the availability of large, diverse, and high-quality datasets, which can be challenging to obtain due to data scarcity, privacy concerns, and high costs. Synthetic data has emerged as a promising solution by generating artificial data that mimics real-world patterns. This paper provides an overview of synthetic data research, discussing its applications, challenges, and future directions. We present empirical evidence from prior art to demonstrate its effectiveness and highlight the importance of ensuring its factuality, fidelity, and unbiasedness. We emphasize the need for responsible use of synthetic data to build more powerful, inclusive, and trustworthy language models.
CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
Apr 06, 2024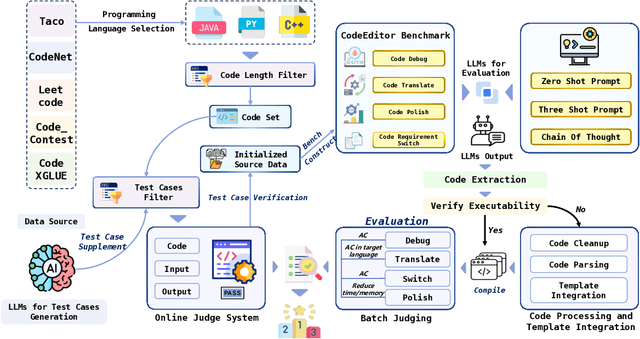
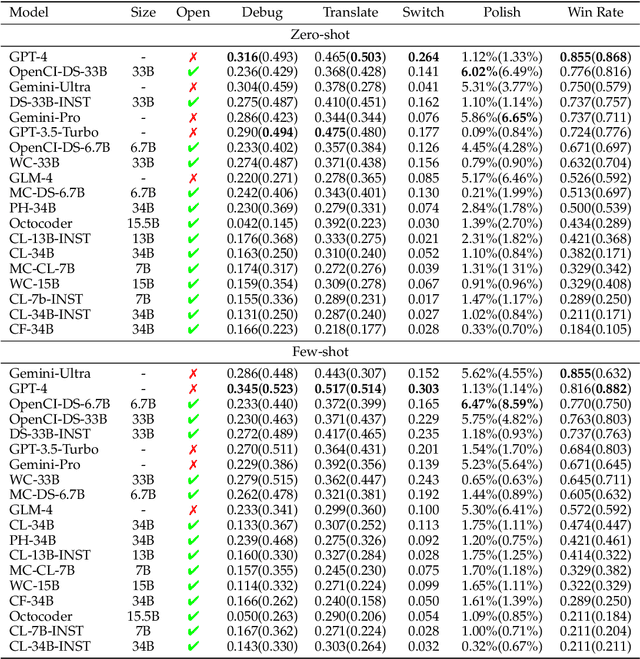
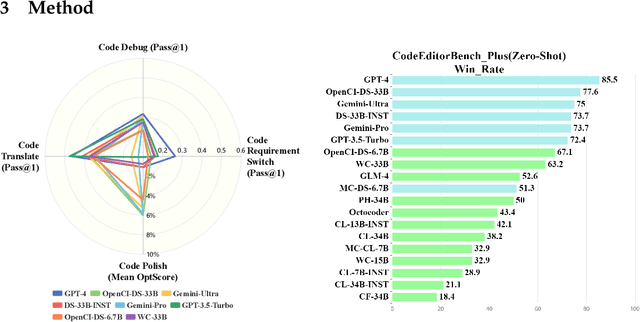

Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.
Long-form factuality in large language models
Apr 03, 2024



Large language models (LLMs) often generate content that contains factual errors when responding to fact-seeking prompts on open-ended topics. To benchmark a model's long-form factuality in open domains, we first use GPT-4 to generate LongFact, a prompt set comprising thousands of questions spanning 38 topics. We then propose that LLM agents can be used as automated evaluators for long-form factuality through a method which we call Search-Augmented Factuality Evaluator (SAFE). SAFE utilizes an LLM to break down a long-form response into a set of individual facts and to evaluate the accuracy of each fact using a multi-step reasoning process comprising sending search queries to Google Search and determining whether a fact is supported by the search results. Furthermore, we propose extending F1 score as an aggregated metric for long-form factuality. To do so, we balance the percentage of supported facts in a response (precision) with the percentage of provided facts relative to a hyperparameter representing a user's preferred response length (recall). Empirically, we demonstrate that LLM agents can outperform crowdsourced human annotators - on a set of ~16k individual facts, SAFE agrees with crowdsourced human annotators 72% of the time, and on a random subset of 100 disagreement cases, SAFE wins 76% of the time. At the same time, SAFE is more than 20 times cheaper than human annotators. We also benchmark thirteen language models on LongFact across four model families (Gemini, GPT, Claude, and PaLM-2), finding that larger language models generally achieve better long-form factuality. LongFact, SAFE, and all experimental code are available at https://github.com/google-deepmind/long-form-factuality.
Reconfigurable Robot Identification from Motion Data
Mar 15, 2024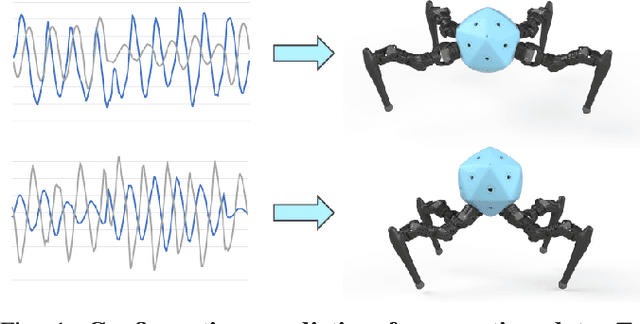
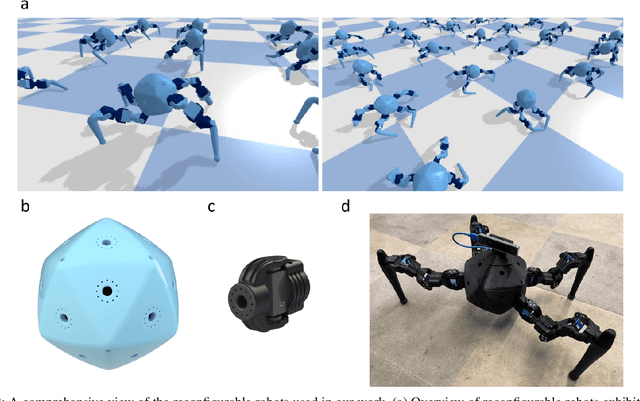
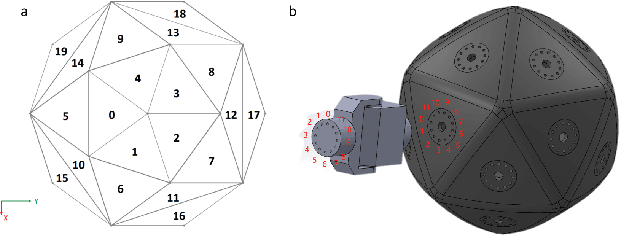
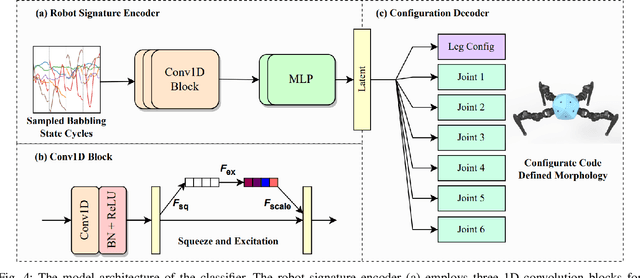
Integrating Large Language Models (VLMs) and Vision-Language Models (VLMs) with robotic systems enables robots to process and understand complex natural language instructions and visual information. However, a fundamental challenge remains: for robots to fully capitalize on these advancements, they must have a deep understanding of their physical embodiment. The gap between AI models cognitive capabilities and the understanding of physical embodiment leads to the following question: Can a robot autonomously understand and adapt to its physical form and functionalities through interaction with its environment? This question underscores the transition towards developing self-modeling robots without reliance on external sensory or pre-programmed knowledge about their structure. Here, we propose a meta self modeling that can deduce robot morphology through proprioception (the internal sense of position and movement). Our study introduces a 12 DoF reconfigurable legged robot, accompanied by a diverse dataset of 200k unique configurations, to systematically investigate the relationship between robotic motion and robot morphology. Utilizing a deep neural network model comprising a robot signature encoder and a configuration decoder, we demonstrate the capability of our system to accurately predict robot configurations from proprioceptive signals. This research contributes to the field of robotic self-modeling, aiming to enhance understanding of their physical embodiment and adaptability in real world scenarios.
Gemma: Open Models Based on Gemini Research and Technology
Mar 13, 2024



This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.