 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-form factuality in large language models
Apr 03, 2024



Large language models (LLMs) often generate content that contains factual errors when responding to fact-seeking prompts on open-ended topics. To benchmark a model's long-form factuality in open domains, we first use GPT-4 to generate LongFact, a prompt set comprising thousands of questions spanning 38 topics. We then propose that LLM agents can be used as automated evaluators for long-form factuality through a method which we call Search-Augmented Factuality Evaluator (SAFE). SAFE utilizes an LLM to break down a long-form response into a set of individual facts and to evaluate the accuracy of each fact using a multi-step reasoning process comprising sending search queries to Google Search and determining whether a fact is supported by the search results. Furthermore, we propose extending F1 score as an aggregated metric for long-form factuality. To do so, we balance the percentage of supported facts in a response (precision) with the percentage of provided facts relative to a hyperparameter representing a user's preferred response length (recall). Empirically, we demonstrate that LLM agents can outperform crowdsourced human annotators - on a set of ~16k individual facts, SAFE agrees with crowdsourced human annotators 72% of the time, and on a random subset of 100 disagreement cases, SAFE wins 76% of the time. At the same time, SAFE is more than 20 times cheaper than human annotators. We also benchmark thirteen language models on LongFact across four model families (Gemini, GPT, Claude, and PaLM-2), finding that larger language models generally achieve better long-form factuality. LongFact, SAFE, and all experimental code are available at https://github.com/google-deepmind/long-form-factuality.
Large Language Models Cannot Self-Correct Reasoning Yet
Oct 03, 2023



Large Language Models (LLMs) have emerged as a groundbreaking technology with their unparalleled text generation capabilities across various applications. Nevertheless, concerns persist regarding the accuracy and appropriateness of their generated content. A contemporary methodology, self-correction, has been proposed as a remedy to these issues. Building upon this premise, this paper critically examines the role and efficacy of self-correction within LLMs, shedding light on its true potential and limitations. Central to our investigation is the notion of intrinsic self-correction, whereby an LLM attempts to correct its initial responses based solely on its inherent capabilities, without the crutch of external feedback. In the context of reasoning, our research indicates that LLMs struggle to self-correct their responses without external feedback, and at times, their performance might even degrade post self-correction. Drawing from these insights, we offer suggestions for future research and practical applications in this field.
Compositional Semantic Parsing with Large Language Models
Sep 30, 2022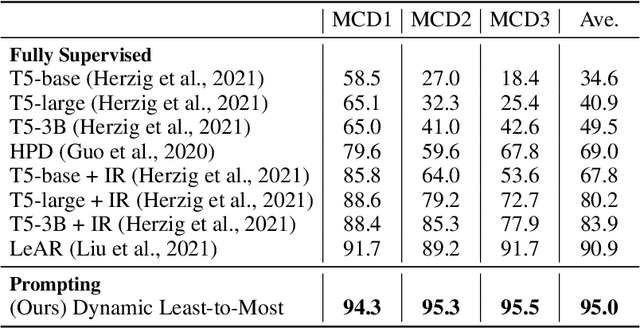
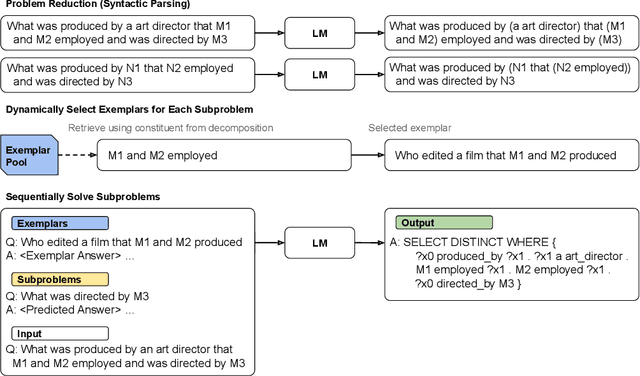
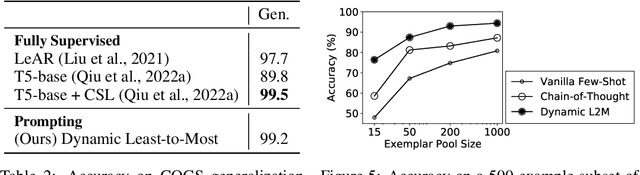
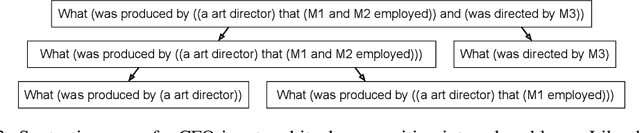
Humans can reason compositionally when presented with new tasks. Previous research shows that appropriate prompting techniques enable large language models (LLMs) to solve artificial compositional generalization tasks such as SCAN. In this work, we identify additional challenges in more realistic semantic parsing tasks with larger vocabulary and refine these prompting techniques to address them. Our best method is based on least-to-most prompting: it decomposes the problem using prompting-based syntactic parsing, then uses this decomposition to select appropriate exemplars and to sequentially generate the semantic parse. This method allows us to set a new state of the art for CFQ while requiring only 1% of the training data used by traditional approaches. Due to the general nature of our approach, we expect similar efforts will lead to new results in other tasks and domains, especially for knowledge-intensive applications.
DETR++: Taming Your Multi-Scale Detection Transformer
Jun 07, 2022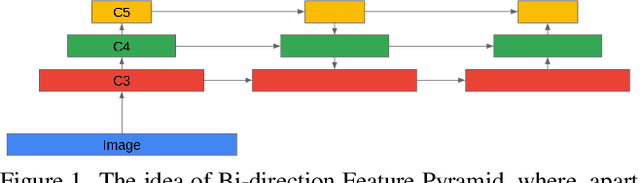
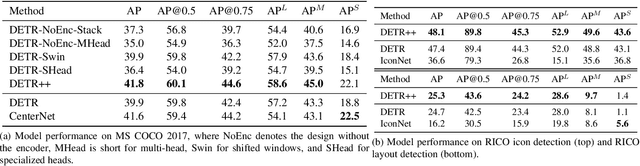
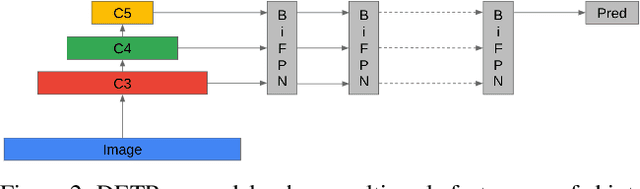
Convolutional Neural Networks (CNN) have dominated the field of detection ever since the success of AlexNet in ImageNet classification [12]. With the sweeping reform of Transformers [27] in natural language processing, Carion et al. [2] introduce the Transformer-based detection method, i.e., DETR. However, due to the quadratic complexity in the self-attention mechanism in the Transformer, DETR is never able to incorporate multi-scale features as performed in existing CNN-based detectors, leading to inferior results in small object detection. To mitigate this issue and further improve performance of DETR, in this work, we investigate different methods to incorporate multi-scale features and find that a Bi-directional Feature Pyramid (BiFPN) works best with DETR in further raising the detection precision. With this discovery, we propose DETR++, a new architecture that improves detection results by 1.9% AP on MS COCO 2017, 11.5% AP on RICO icon detection, and 9.1% AP on RICO layout extraction over existing baselines.
Token Dropping for Efficient BERT Pretraining
Mar 24, 2022
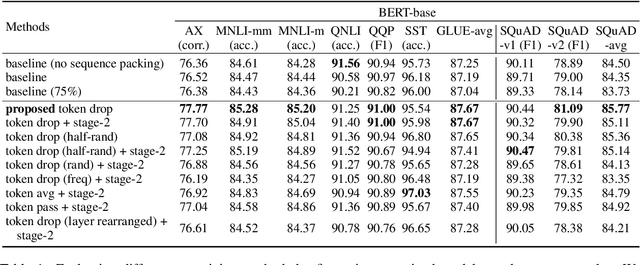
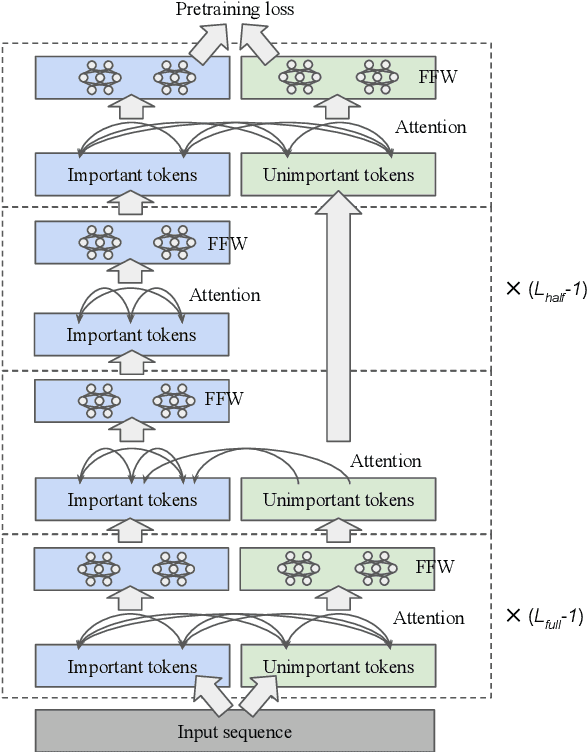
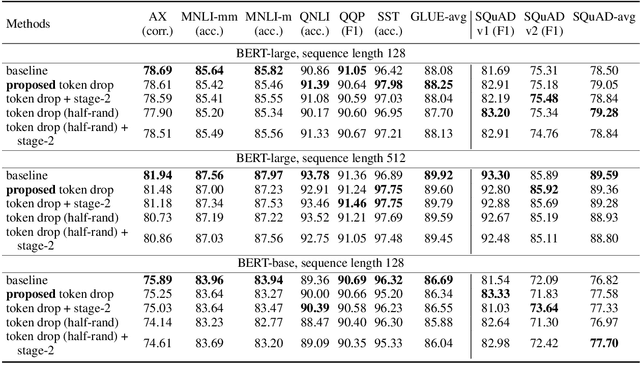
Transformer-based models generally allocate the same amount of computation for each token in a given sequence. We develop a simple but effective "token dropping" method to accelerate the pretraining of transformer models, such as BERT, without degrading its performance on downstream tasks. In short, we drop unimportant tokens starting from an intermediate layer in the model to make the model focus on important tokens; the dropped tokens are later picked up by the last layer of the model so that the model still produces full-length sequences. We leverage the already built-in masked language modeling (MLM) loss to identify unimportant tokens with practically no computational overhead. In our experiments, this simple approach reduces the pretraining cost of BERT by 25% while achieving similar overall fine-tuning performance on standard downstream tasks.
Linear-Time WordPiece Tokenization
Dec 31, 2020
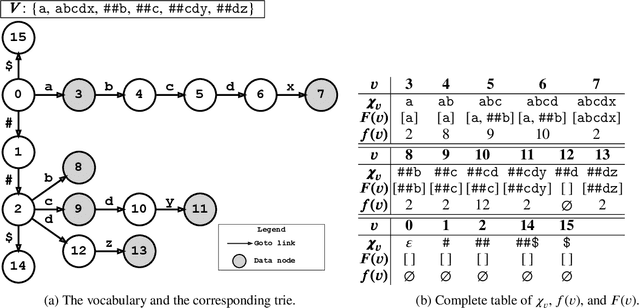

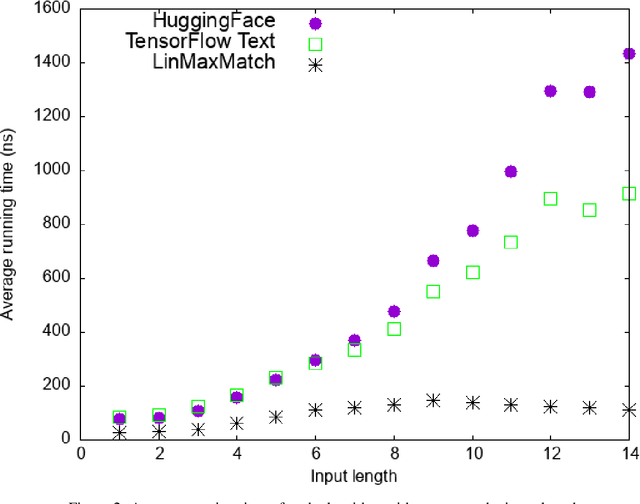
WordPiece tokenization is a subword-based tokenization schema adopted by BERT: it segments the input text via a longest-match-first tokenization strategy, known as Maximum Matching or MaxMatch. To the best of our knowledge, all published MaxMatch algorithms are quadratic (or higher). In this paper, we propose LinMaxMatch, a novel linear-time algorithm for MaxMatch and WordPiece tokenization. Inspired by the Aho-Corasick algorithm, we introduce additional linkages on top of the trie built from the vocabulary, allowing smart transitions when the trie matching cannot continue. Experimental results show that our algorithm is 3x faster on average than two production systems by HuggingFace and TensorFlow Text. Regarding long-tail inputs, our algorithm is 4.5x faster at the 95 percentile. This work has immediate practical value (reducing inference latency, saving compute resources, etc.) and is of theoretical interest by providing an optimal complexity solution to the decades-old MaxMatch problem.
Deep Sentence Embedding Using Long Short-Term Memory Networks: Analysis and Application to Information Retrieval
Jan 16, 2016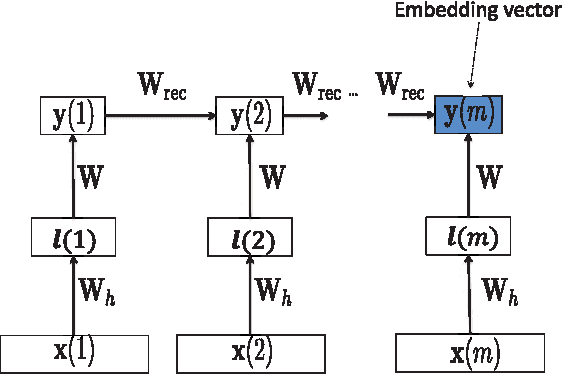

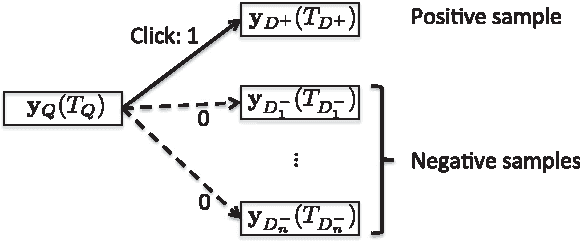
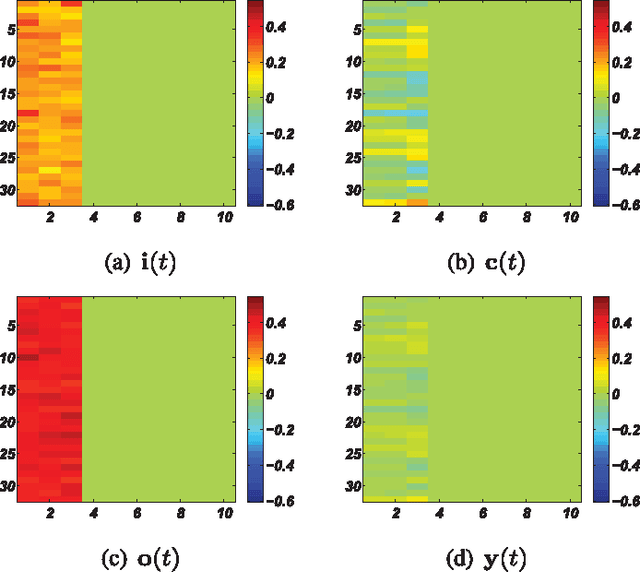
This paper develops a model that addresses sentence embedding, a hot topic in current natural language processing research, using recurrent neural networks with Long Short-Term Memory (LSTM) cells. Due to its ability to capture long term memory, the LSTM-RNN accumulates increasingly richer information as it goes through the sentence, and when it reaches the last word, the hidden layer of the network provides a semantic representation of the whole sentence. In this paper, the LSTM-RNN is trained in a weakly supervised manner on user click-through data logged by a commercial web search engine. Visualization and analysis are performed to understand how the embedding process works. The model is found to automatically attenuate the unimportant words and detects the salient keywords in the sentence. Furthermore, these detected keywords are found to automatically activate different cells of the LSTM-RNN, where words belonging to a similar topic activate the same cell. As a semantic representation of the sentence, the embedding vector can be used in many different applications. These automatic keyword detection and topic allocation abilities enabled by the LSTM-RNN allow the network to perform document retrieval, a difficult language processing task, where the similarity between the query and documents can be measured by the distance between their corresponding sentence embedding vectors computed by the LSTM-RNN. On a web search task, the LSTM-RNN embedding is shown to significantly outperform several existing state of the art methods. We emphasize that the proposed model generates sentence embedding vectors that are specially useful for web document retrieval tasks. A comparison with a well known general sentence embedding method, the Paragraph Vector, is performed. The results show that the proposed method in this paper significantly outperforms it for web document retrieval task.
End-to-end Learning of LDA by Mirror-Descent Back Propagation over a Deep Architecture
Nov 01, 2015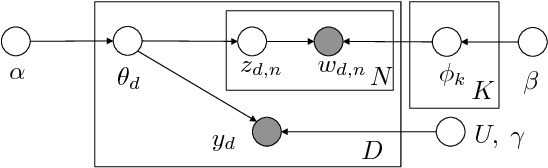
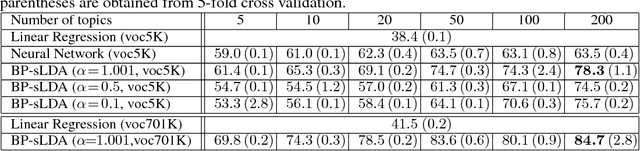
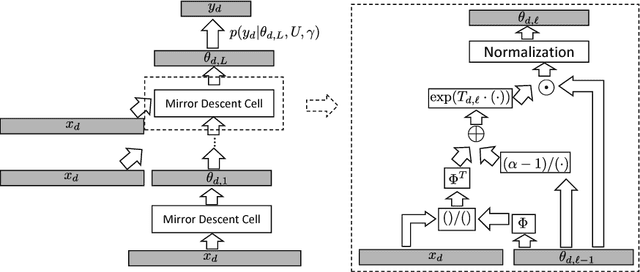
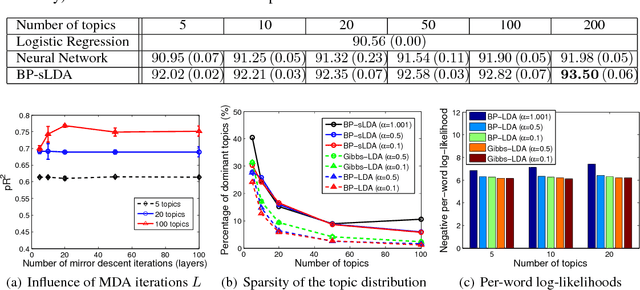
We develop a fully discriminative learning approach for supervised Latent Dirichlet Allocation (LDA) model using Back Propagation (i.e., BP-sLDA), which maximizes the posterior probability of the prediction variable given the input document. Different from traditional variational learning or Gibbs sampling approaches, the proposed learning method applies (i) the mirror descent algorithm for maximum a posterior inference and (ii) back propagation over a deep architecture together with stochastic gradient/mirror descent for model parameter estimation, leading to scalable and end-to-end discriminative learning of the model. As a byproduct, we also apply this technique to develop a new learning method for the traditional unsupervised LDA model (i.e., BP-LDA). Experimental results on three real-world regression and classification tasks show that the proposed methods significantly outperform the previous supervised topic models, neural networks, and is on par with deep neural networks.