 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Up Models and Data with $\texttt{t5x}$ and $\texttt{seqio}$
Mar 31, 2022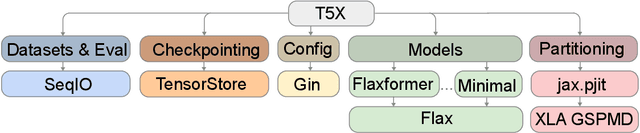
Recent neural network-based language models have benefited greatly from scaling up the size of training datasets and the number of parameters in the models themselves. Scaling can be complicated due to various factors including the need to distribute computation on supercomputer clusters (e.g., TPUs), prevent bottlenecks when infeeding data, and ensure reproducible results. In this work, we present two software libraries that ease these issues: $\texttt{t5x}$ simplifies the process of building and training large language models at scale while maintaining ease of use, and $\texttt{seqio}$ provides a task-based API for simple creation of fast and reproducible training data and evaluation pipelines. These open-source libraries have been used to train models with hundreds of billions of parameters on datasets with multiple terabytes of training data. Along with the libraries, we release configurations and instructions for T5-like encoder-decoder models as well as GPT-like decoder-only architectures. $\texttt{t5x}$ and $\texttt{seqio}$ are open source and available at https://github.com/google-research/t5x and https://github.com/google/seqio, respectively.
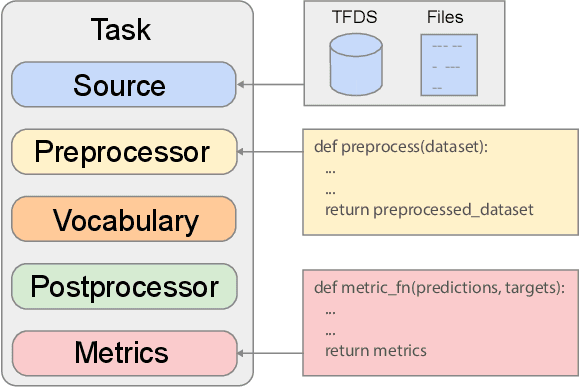
Linear-Time WordPiece Tokenization
Dec 31, 2020
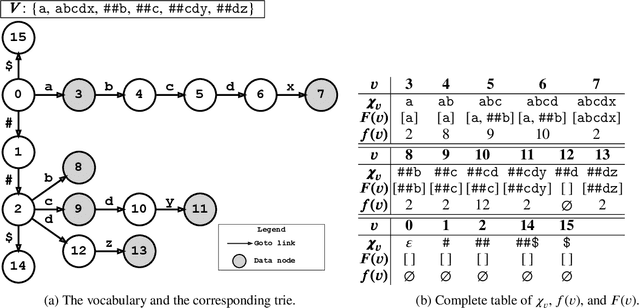

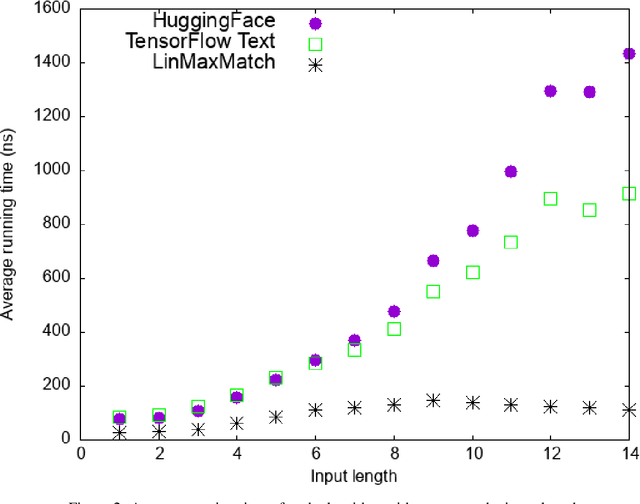
WordPiece tokenization is a subword-based tokenization schema adopted by BERT: it segments the input text via a longest-match-first tokenization strategy, known as Maximum Matching or MaxMatch. To the best of our knowledge, all published MaxMatch algorithms are quadratic (or higher). In this paper, we propose LinMaxMatch, a novel linear-time algorithm for MaxMatch and WordPiece tokenization. Inspired by the Aho-Corasick algorithm, we introduce additional linkages on top of the trie built from the vocabulary, allowing smart transitions when the trie matching cannot continue. Experimental results show that our algorithm is 3x faster on average than two production systems by HuggingFace and TensorFlow Text. Regarding long-tail inputs, our algorithm is 4.5x faster at the 95 percentile. This work has immediate practical value (reducing inference latency, saving compute resources, etc.) and is of theoretical interest by providing an optimal complexity solution to the decades-old MaxMatch problem.
Natural Language Processing with Small Feed-Forward Networks
Aug 01, 2017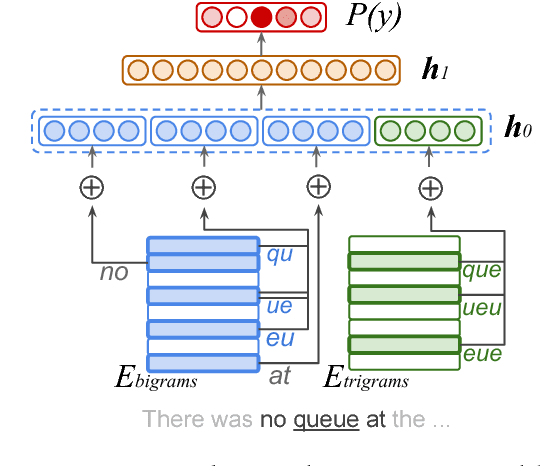
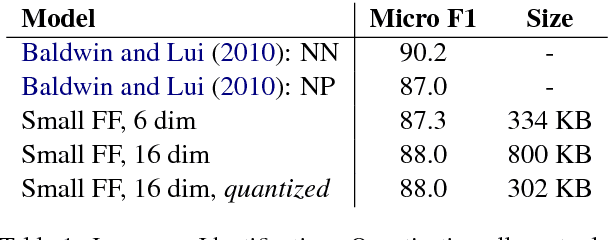
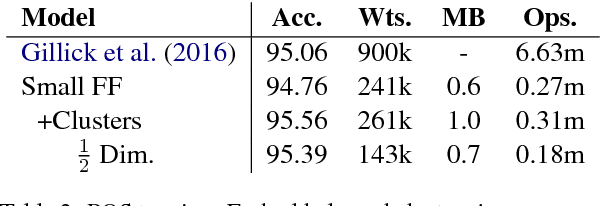
We show that small and shallow feed-forward neural networks can achieve near state-of-the-art results on a range of unstructured and structured language processing tasks while being considerably cheaper in memory and computational requirements than deep recurrent models. Motivated by resource-constrained environments like mobile phones, we showcase simple techniques for obtaining such small neural network models, and investigate different tradeoffs when deciding how to allocate a small memory budget.