 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Embedding 2: A Native Multimodal Embedding Model from Gemini
May 26, 2026We introduce Gemini Embedding 2, a native multimodal embedding model that allows embedding video, audio, image, and text modalities in a unified representation space. We leverage the multimodal capabilities of Gemini to produce embeddings for arbitrary combinations of interleaved inputs across all these modalities that generalize well across a wide variety of tasks. Applying large-scale contrastive learning in a multi-task multi-stage training setup, we achieve state-of-the-art performance on key embedding benchmarks including unimodal, cross-modal, and multimodal retrieval spanning a diverse set of tasks. We show that our embedding model demonstrates strong performance (with a score of 62.9 R@1 on MSCOCO, 68.8 NDCG@10 on Vatex, 69.9 on MTEB multilingual and 84.0 on MTEB Code) across a variety of tasks surpassing the performance of specialized models. These unified capabilities make Gemini Embedding 2 a promising candidate for downstream use cases such as RAG, recommendation and search. Furthermore, its robust zero-shot performance across distinct fields - from astronomy and bioscience to fine arts and the culinary arts - establishes it as a highly reliable, out-of-the-box representation even for specialized domains.
Hallucination-aware intermediate representation edit in large vision-language models
Mar 31, 2026Large Vision-Language Models have demonstrated exceptional performance in multimodal reasoning and complex scene understanding. However, these models still face significant hallucination issues, where outputs contradict visual facts. Recent research on hallucination mitigation has focused on retraining methods and Contrastive Decoding (CD) methods. While both methods perform well, retraining methods require substantial training resources, and CD methods introduce dual inference overhead. These factors hinder their practical applicability. To address the above issue, we propose a framework for dynamically detecting hallucination representations and performing hallucination-eliminating edits on these representations. With minimal additional computational cost, we achieve state-of-the-art performance on existing benchmarks. Extensive experiments demonstrate the effectiveness of our approach, highlighting its efficient and robust hallucination elimination capability and its powerful controllability over hallucinations. Code is available at https://github.com/ASGO-MM/HIRE
Understanding and Mitigating Hallucinations in Multimodal Chain-of-Thought Models
Mar 28, 2026Multimodal Chain-of-Thought (MCoT) models have demonstrated impressive capability in complex visual reasoning tasks. Unfortunately, recent studies reveal that they suffer from severe hallucination problems due to diminished visual attention during the generation process. However, visual attention decay is a well-studied problem in Large Vision-Language Models (LVLMs). Considering the fundamental differences in reasoning processes between MCoT models and traditional LVLMs, we raise a basic question: Whether MCoT models have unique causes of hallucinations? To answer this question, we systematically investigate the hallucination patterns of MCoT models and find that fabricated texts are primarily generated in associative reasoning steps, which we term divergent thinking. Leveraging these insights, we introduce a simple yet effective strategy that can effectively localize divergent thinking steps and intervene in the decoding process to mitigate hallucinations. Extensive experiments show that our method outperforms existing methods by a large margin. More importantly, our proposed method can be conveniently integrated with other hallucination mitigation methods and further boost their performance. The code is publicly available at https://github.com/ASGO-MM/MCoT-hallucination.
Co-jump: Cooperative Jumping with Quadrupedal Robots via Multi-Agent Reinforcement Learning
Feb 11, 2026While single-agent legged locomotion has witnessed remarkable progress, individual robots remain fundamentally constrained by physical actuation limits. To transcend these boundaries, we introduce Co-jump, a cooperative task where two quadrupedal robots synchronize to execute jumps far beyond their solo capabilities. We tackle the high-impulse contact dynamics of this task under a decentralized setting, achieving synchronization without explicit communication or pre-specified motion primitives. Our framework leverages Multi-Agent Proximal Policy Optimization (MAPPO) enhanced by a progressive curriculum strategy, which effectively overcomes the sparse-reward exploration challenges inherent in mechanically coupled systems. We demonstrate robust performance in simulation and successful transfer to physical hardware, executing multi-directional jumps onto platforms up to 1.5 m in height. Specifically, one of the robots achieves a foot-end elevation of 1.1 m, which represents a 144% improvement over the 0.45 m jump height of a standalone quadrupedal robot, demonstrating superior vertical performance. Notably, this precise coordination is achieved solely through proprioceptive feedback, establishing a foundation for communication-free collaborative locomotion in constrained environments.
Learning Human-Like Badminton Skills for Humanoid Robots
Feb 09, 2026Realizing versatile and human-like performance in high-demand sports like badminton remains a formidable challenge for humanoid robotics. Unlike standard locomotion or static manipulation, this task demands a seamless integration of explosive whole-body coordination and precise, timing-critical interception. While recent advances have achieved lifelike motion mimicry, bridging the gap between kinematic imitation and functional, physics-aware striking without compromising stylistic naturalness is non-trivial. To address this, we propose Imitation-to-Interaction, a progressive reinforcement learning framework designed to evolve a robot from a "mimic" to a capable "striker." Our approach establishes a robust motor prior from human data, distills it into a compact, model-based state representation, and stabilizes dynamics via adversarial priors. Crucially, to overcome the sparsity of expert demonstrations, we introduce a manifold expansion strategy that generalizes discrete strike points into a dense interaction volume. We validate our framework through the mastery of diverse skills, including lifts and drop shots, in simulation. Furthermore, we demonstrate the first zero-shot sim-to-real transfer of anthropomorphic badminton skills to a humanoid robot, successfully replicating the kinetic elegance and functional precision of human athletes in the physical world.
Massive Sound Embedding Benchmark (MSEB)
Feb 06, 2026Audio is a critical component of multimodal perception, and any truly intelligent system must demonstrate a wide range of auditory capabilities. These capabilities include transcription, classification, retrieval, reasoning, segmentation, clustering, reranking, and reconstruction. Fundamentally, each task involves transforming a raw audio signal into a meaningful 'embedding' - be it a single vector, a sequence of continuous or discrete representations, or another structured form - which then serves as the basis for generating the task's final response. To accelerate progress towards robust machine auditory intelligence, we present the Massive Sound Embedding Benchmark (MSEB): an extensible framework designed to evaluate the auditory components of any multimodal system. In its first release, MSEB offers a comprehensive suite of eight core tasks, with more planned for the future, supported by diverse datasets, including the new, large-scale Simple Voice Questions (SVQ) dataset. Our initial experiments establish clear performance headrooms, highlighting the significant opportunity to improve real-world multimodal experiences where audio is a core signal. We encourage the research community to use MSEB to assess their algorithms and contribute to its growth. The library is publicly hosted at github.
Retrieval Augmented Question Answering: When Should LLMs Admit Ignorance?
Dec 29, 2025The success of expanded context windows in Large Language Models (LLMs) has driven increased use of broader context in retrieval-augmented generation. We investigate the use of LLMs for retrieval augmented question answering. While longer contexts make it easier to incorporate targeted knowledge, they introduce more irrelevant information that hinders the model's generation process and degrades its performance. To address the issue, we design an adaptive prompting strategy which involves splitting the retrieved information into smaller chunks and sequentially prompting a LLM to answer the question using each chunk. Adjusting the chunk size allows a trade-off between incorporating relevant information and reducing irrelevant information. Experimental results on three open-domain question answering datasets demonstrate that the adaptive strategy matches the performance of standard prompting while using fewer tokens. Our analysis reveals that when encountering insufficient information, the LLM often generates incorrect answers instead of declining to respond, which constitutes a major source of error. This finding highlights the need for further research into enhancing LLMs' ability to effectively decline requests when faced with inadequate information.
Like Playing a Video Game: Spatial-Temporal Optimization of Foot Trajectories for Controlled Football Kicking in Bipedal Robots
Oct 02, 2025Humanoid robot soccer presents several challenges, particularly in maintaining system stability during aggressive kicking motions while achieving precise ball trajectory control. Current solutions, whether traditional position-based control methods or reinforcement learning (RL) approaches, exhibit significant limitations. Model predictive control (MPC) is a prevalent approach for ordinary quadruped and biped robots. While MPC has demonstrated advantages in legged robots, existing studies often oversimplify the leg swing progress, relying merely on simple trajectory interpolation methods. This severely constrains the foot's environmental interaction capability, hindering tasks such as ball kicking. This study innovatively adapts the spatial-temporal trajectory planning method, which has been successful in drone applications, to bipedal robotic systems. The proposed approach autonomously generates foot trajectories that satisfy constraints on target kicking position, velocity, and acceleration while simultaneously optimizing swing phase duration. Experimental results demonstrate that the optimized trajectories closely mimic human kicking behavior, featuring a backswing motion. Simulation and hardware experiments confirm the algorithm's efficiency, with trajectory planning times under 1 ms, and its reliability, achieving nearly 100 % task completion accuracy when the soccer goal is within the range of -90{\deg} to 90{\deg}.
Steering Prosocial AI Agents: Computational Basis of LLM's Decision Making in Social Simulation
Apr 16, 2025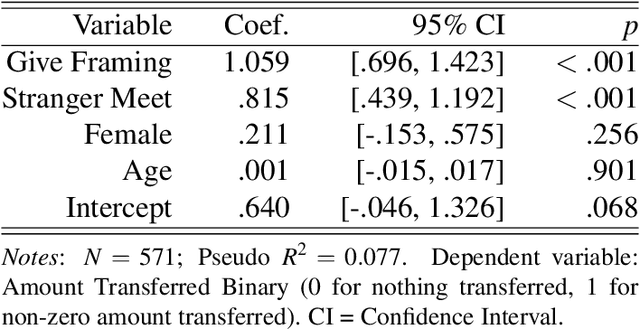
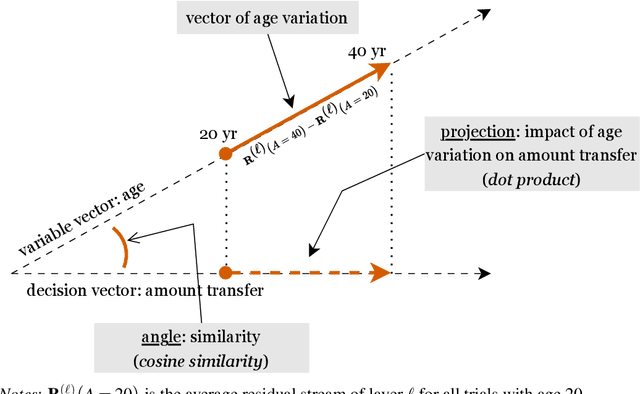
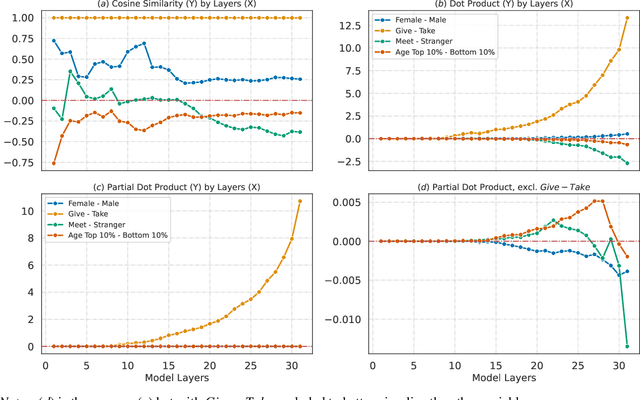
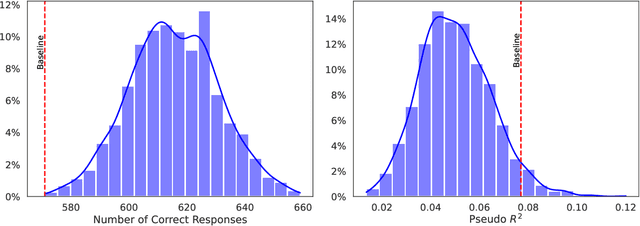
Large language models (LLMs) increasingly serve as human-like decision-making agents in social science and applied settings. These LLM-agents are typically assigned human-like characters and placed in real-life contexts. However, how these characters and contexts shape an LLM's behavior remains underexplored. This study proposes and tests methods for probing, quantifying, and modifying an LLM's internal representations in a Dictator Game -- a classic behavioral experiment on fairness and prosocial behavior. We extract ``vectors of variable variations'' (e.g., ``male'' to ``female'') from the LLM's internal state. Manipulating these vectors during the model's inference can substantially alter how those variables relate to the model's decision-making. This approach offers a principled way to study and regulate how social concepts can be encoded and engineered within transformer-based models, with implications for alignment, debiasing, and designing AI agents for social simulations in both academic and commercial applications.
A Unified Theoretic and Algorithmic Framework for Solving Multivariate Linear Model with $\ell^1$-norm Optimization
Apr 01, 2025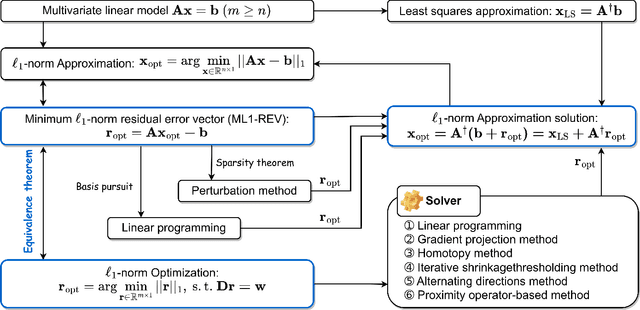

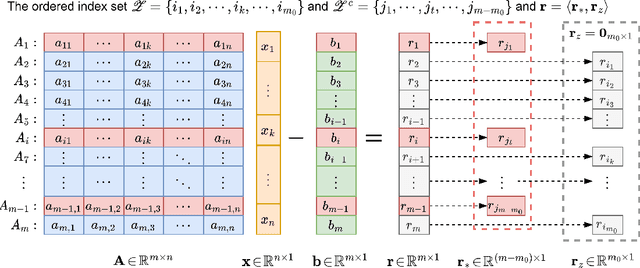

It is a challenging problem that solving the \textit{multivariate linear model} (MLM) $\mathbf{A}\mathbf{x}=\mathbf{b}$ with the $\ell_1 $-norm approximation method such that $||\mathbf{A}\mathbf{x}-\mathbf{b}||_1$, the $\ell_1$-norm of the \textit{residual error vector} (REV), is minimized. In this work, our contributions lie in two aspects: firstly, the equivalence theorem for the structure of the $\ell_1$-norm optimal solution to the MLM is proposed and proved; secondly, a unified algorithmic framework for solving the MLM with $\ell_1$-norm optimization is proposed and six novel algorithms (L1-GPRS, L1-TNIPM, L1-HP, L1-IST, L1-ADM, L1-POB) are designed. There are three significant characteristics in the algorithms discussed: they are implemented with simple matrix operations which do not depend on specific optimization solvers; they are described with algorithmic pseudo-codes and implemented with Python and Octave/MATLAB which means easy usage; and the high accuracy and efficiency of our six new algorithms can be achieved successfully in the scenarios with different levels of data redundancy. We hope that the unified theoretic and algorithmic framework with source code released on GitHub could motivate the applications of the $\ell_1$-norm optimization for parameter estimation of MLM arising in science, technology, engineering, mathematics, economics, and so on.