 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTDA: Spatio-Temporal Dual-Encoder Network Incorporating Driver Attention to Predict Driver Behaviors Under Safety-Critical Scenarios
Aug 03, 2024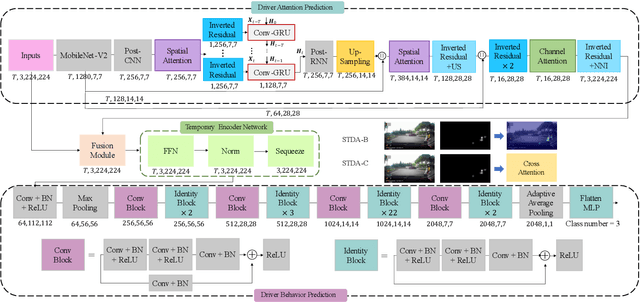
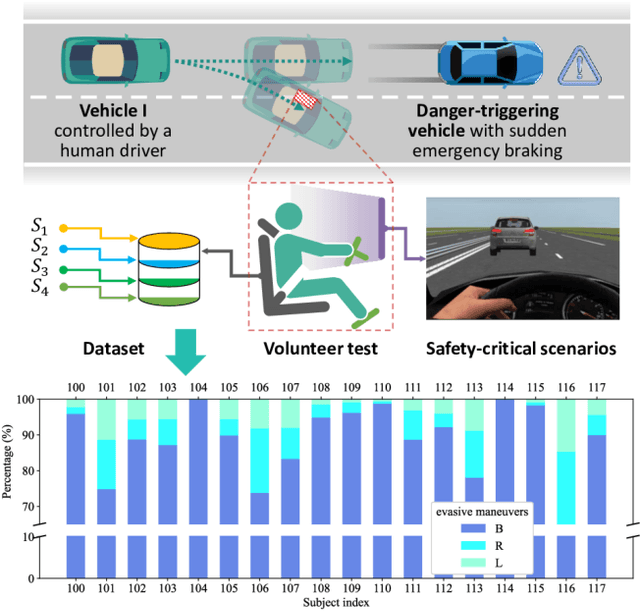
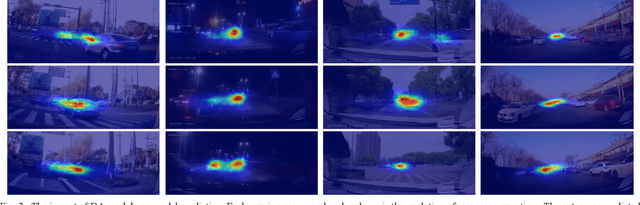
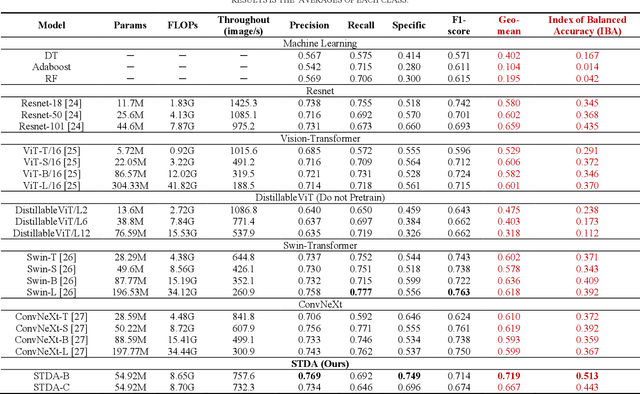
Accurate behavior prediction for vehicles is essential but challenging for autonomous driving. Most existing studies show satisfying performance under regular scenarios, but most neglected safety-critical scenarios. In this study, a spatio-temporal dual-encoder network named STDA for safety-critical scenarios was developed. Considering the exceptional capabilities of human drivers in terms of situational awareness and comprehending risks, driver attention was incorporated into STDA to facilitate swift identification of the critical regions, which is expected to improve both performance and interpretability. STDA contains four parts: the driver attention prediction module, which predicts driver attention; the fusion module designed to fuse the features between driver attention and raw images; the temporary encoder module used to enhance the capability to interpret dynamic scenes; and the behavior prediction module to predict the behavior. The experiment data are used to train and validate the model. The results show that STDA improves the G-mean from 0.659 to 0.719 when incorporating driver attention and adopting a temporal encoder module. In addition, extensive experimentation has been conducted to validate that the proposed module exhibits robust generalization capabilities and can be seamlessly integrated into other mainstream models.
AHMF: Adaptive Hybrid-Memory-Fusion Model for Driver Attention Prediction
Jul 24, 2024



Accurate driver attention prediction can serve as a critical reference for intelligent vehicles in understanding traffic scenes and making informed driving decisions. Though existing studies on driver attention prediction improved performance by incorporating advanced saliency detection techniques, they overlooked the opportunity to achieve human-inspired prediction by analyzing driving tasks from a cognitive science perspective. During driving, drivers' working memory and long-term memory play crucial roles in scene comprehension and experience retrieval, respectively. Together, they form situational awareness, facilitating drivers to quickly understand the current traffic situation and make optimal decisions based on past driving experiences. To explicitly integrate these two types of memory, this paper proposes an Adaptive Hybrid-Memory-Fusion (AHMF) driver attention prediction model to achieve more human-like predictions. Specifically, the model first encodes information about specific hazardous stimuli in the current scene to form working memories. Then, it adaptively retrieves similar situational experiences from the long-term memory for final prediction. Utilizing domain adaptation techniques, the model performs parallel training across multiple datasets, thereby enriching the accumulated driving experience within the long-term memory module. Compared to existing models, our model demonstrates significant improvements across various metrics on multiple public datasets, proving the effectiveness of integrating hybrid memories in driver attention prediction.
Risk-Aware Vehicle Trajectory Prediction Under Safety-Critical Scenarios
Jul 18, 2024Trajectory prediction is significant for intelligent vehicles to achieve high-level autonomous driving, and a lot of relevant research achievements have been made recently. Despite the rapid development, most existing studies solely focused on normal safe scenarios while largely neglecting safety-critical scenarios, particularly those involving imminent collisions. This oversight may result in autonomous vehicles lacking the essential predictive ability in such situations, posing a significant threat to safety. To tackle these, this paper proposes a risk-aware trajectory prediction framework tailored to safety-critical scenarios. Leveraging distinctive hazardous features, we develop three core risk-aware components. First, we introduce a risk-incorporated scene encoder, which augments conventional encoders with quantitative risk information to achieve risk-aware encoding of hazardous scene contexts. Next, we incorporate endpoint-risk-combined intention queries as prediction priors in the decoder to ensure that the predicted multimodal trajectories cover both various spatial intentions and risk levels. Lastly, an auxiliary risk prediction task is implemented for the ultimate risk-aware prediction. Furthermore, to support model training and performance evaluation, we introduce a safety-critical trajectory prediction dataset and tailored evaluation metrics. We conduct comprehensive evaluations and compare our model with several SOTA models. Results demonstrate the superior performance of our model, with a significant improvement in most metrics. This prediction advancement enables autonomous vehicles to execute correct collision avoidance maneuvers under safety-critical scenarios, eventually enhancing road traffic safety.
M2DA: Multi-Modal Fusion Transformer Incorporating Driver Attention for Autonomous Driving
Mar 19, 2024End-to-end autonomous driving has witnessed remarkable progress. However, the extensive deployment of autonomous vehicles has yet to be realized, primarily due to 1) inefficient multi-modal environment perception: how to integrate data from multi-modal sensors more efficiently; 2) non-human-like scene understanding: how to effectively locate and predict critical risky agents in traffic scenarios like an experienced driver. To overcome these challenges, in this paper, we propose a Multi-Modal fusion transformer incorporating Driver Attention (M2DA) for autonomous driving. To better fuse multi-modal data and achieve higher alignment between different modalities, a novel Lidar-Vision-Attention-based Fusion (LVAFusion) module is proposed. By incorporating driver attention, we empower the human-like scene understanding ability to autonomous vehicles to identify crucial areas within complex scenarios precisely and ensure safety. We conduct experiments on the CARLA simulator and achieve state-of-the-art performance with less data in closed-loop benchmarks. Source codes are available at https://anonymous.4open.science/r/M2DA-4772.