 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Loss Score for Dynamic Data Pruning
Apr 06, 2026Dynamic data pruning accelerates deep learning by selectively omitting less informative samples during training. While per-sample loss is a common importance metric, obtaining it can be challenging or infeasible for complex models or loss functions, often requiring significant implementation effort. This work proposes the Batch Loss Score (BLS), a computationally efficient alternative using an Exponential Moving Average (EMA) of readily available batch losses to assign scores to individual samples. We frame the batch loss, from the perspective of a single sample, as a noisy measurement of its scaled individual loss, with noise originating from stochastic batch composition. It is formally shown that the EMA mechanism functions as a first-order low-pass filter, attenuating high-frequency batch composition noise. This yields a score approximating the smoothed and persistent contribution of the individual sample to the loss, providing a theoretical grounding for BLS as a proxy for sample importance. BLS demonstrates remarkable code integration simplicity (\textbf{three-line injection}) and readily adapts existing per-sample loss-based methods (\textbf{one-line proxy}). Its effectiveness is demonstrated by enhancing two such methods to losslessly prune \textbf{20\%-50\%} of samples across \textit{14 datasets}, \textit{11 tasks} and \textit{18 models}, highlighting its utility and broad applicability, especially for complex scenarios where per-sample loss is difficult to access. Code is available at https://github.com/mrazhou/BLS.
Efficient Reasoning via Thought Compression for Language Segmentation
Apr 02, 2026Chain-of-thought (CoT) reasoning has significantly improved the performance of large multimodal models in language-guided segmentation, yet its prohibitive computational cost, stemming from generating verbose rationales, limits real-world applicability. We introduce WISE (Wisdom from Internal Self-Exploration), a novel paradigm for efficient reasoning guided by the principle of \textit{thinking twice -- once for learning, once for speed}. WISE trains a model to generate a structured sequence: a concise rationale, the final answer, and then a detailed explanation. By placing the concise rationale first, our method leverages autoregressive conditioning to enforce that the concise rationale acts as a sufficient summary for generating the detailed explanation. This structure is reinforced by a self-distillation objective that jointly rewards semantic fidelity and conciseness, compelling the model to internalize its detailed reasoning into a compact form. At inference, the detailed explanation is omitted. To address the resulting conditional distribution shift, our inference strategy, WISE-S, employs a simple prompting technique that injects a brevity-focused instruction into the user's query. This final adjustment facilitates the robust activation of the learned concise policy, unlocking the full benefits of our framework. Extensive experiments show that WISE-S achieves state-of-the-art zero-shot performance on the ReasonSeg benchmark with 58.3 cIoU, while reducing the average reasoning length by nearly \textbf{5$\times$} -- from 112 to just 23 tokens. Code is available at \href{https://github.com/mrazhou/WISE}{WISE}.
SHARP: Spectrum-aware Highly-dynamic Adaptation for Resolution Promotion in Remote Sensing Synthesis
Mar 23, 2026Text-to-image generation powered by Diffusion Transformers (DiTs) has made remarkable strides, yet remote sensing (RS) synthesis lags behind due to two barriers: the absence of a domain-specialized DiT prior and the prohibitive cost of training at the large resolutions that RS applications demand. Training-free resolution promotion via Rotary Position Embedding (RoPE) rescaling offers a practical remedy, but every existing method applies a static positional scaling rule throughout the denoising process. This uniform compression is particularly harmful for RS imagery, whose substantially denser medium- and high-frequency energy encodes the fine structures critical for aerial-scene realism, such as vehicles, building contours, and road markings. Addressing both challenges requires a domain-specialized generative prior coupled with a denoising-aware positional adaptation strategy. To this end, we fine-tune FLUX on over 100,000 curated RS images to build a strong domain prior (RS-FLUX), and propose Spectrum-aware Highly-dynamic Adaptation for Resolution Promotion (SHARP), a training-free method that introduces a rational fractional time schedule k_rs(t) into RoPE. SHARP applies strong positional promotion during the early layout-formation stage and progressively relaxes it during detail recovery, aligning extrapolation strength with the frequency-progressive nature of diffusion denoising. Its resolution-agnostic formulation further enables robust multi-scale generation from a single set of hyperparameters. Extensive experiments across six square and rectangular resolutions show that SHARP consistently outperforms all training-free baselines on CLIP Score, Aesthetic Score, and HPSv2, with widening margins at more aggressive extrapolation factors and negligible computational overhead. Code and weights are available at https://github.com/bxuanz/SHARP.
Discriminative Perception via Anchored Description for Reasoning Segmentation
Mar 04, 2026Reasoning segmentation increasingly employs reinforcement learning to generate explanatory reasoning chains that guide Multimodal Large Language Models. While these geometric rewards are primarily confined to guiding the final localization, they are incapable of discriminating whether the reasoning process remains anchored on the referred region or strays into irrelevant context. Lacking this discriminative guidance, the model's reasoning often devolves into unfocused and verbose chains that ultimately fail to disambiguate and perceive the target in complex scenes. This suggests a need to complement the RL objective with Discriminative Perception, an ability to actively distinguish a target from its context. To realize this, we propose DPAD to compel the model to generate a descriptive caption of the referred object, which is then used to explicitly discriminate by contrasting the caption's semantic relevance to the referred object against the wider context. By optimizing for this discriminative capability, the model is forced to focus on the unique attributes of the target, leading to a more converged and efficient reasoning chain. The descriptive caption also serves as an interpretability rationale that aligns with the segmentation. Experiments on the benchmarks confirm the validity of our approach, delivering substantial performance gains, with the cIoU on ReasonSeg increasing by 3.09% and the reasoning chain length decreasing by approximately 42%. Code is available at https://github.com/mrazhou/DPAD
Towards Seamless Interaction: Causal Turn-Level Modeling of Interactive 3D Conversational Head Dynamics
Dec 17, 2025



Human conversation involves continuous exchanges of speech and nonverbal cues such as head nods, gaze shifts, and facial expressions that convey attention and emotion. Modeling these bidirectional dynamics in 3D is essential for building expressive avatars and interactive robots. However, existing frameworks often treat talking and listening as independent processes or rely on non-causal full-sequence modeling, hindering temporal coherence across turns. We present TIMAR (Turn-level Interleaved Masked AutoRegression), a causal framework for 3D conversational head generation that models dialogue as interleaved audio-visual contexts. It fuses multimodal information within each turn and applies turn-level causal attention to accumulate conversational history, while a lightweight diffusion head predicts continuous 3D head dynamics that captures both coordination and expressive variability. Experiments on the DualTalk benchmark show that TIMAR reduces Fréchet Distance and MSE by 15-30% on the test set, and achieves similar gains on out-of-distribution data. The source code will be released in the GitHub repository https://github.com/CoderChen01/towards-seamleass-interaction.
Nonlinear Causal Discovery through a Sequential Edge Orientation Approach
Jun 05, 2025Recent advances have established the identifiability of a directed acyclic graph (DAG) under additive noise models (ANMs), spurring the development of various causal discovery methods. However, most existing methods make restrictive model assumptions, rely heavily on general independence tests, or require substantial computational time. To address these limitations, we propose a sequential procedure to orient undirected edges in a completed partial DAG (CPDAG), representing an equivalence class of DAGs, by leveraging the pairwise additive noise model (PANM) to identify their causal directions. We prove that this procedure can recover the true causal DAG assuming a restricted ANM. Building on this result, we develop a novel constraint-based algorithm for learning causal DAGs under nonlinear ANMs. Given an estimated CPDAG, we develop a ranking procedure that sorts undirected edges by their adherence to the PANM, which defines an evaluation order of the edges. To determine the edge direction, we devise a statistical test that compares the log-likelihood values, evaluated with respect to the competing directions, of a sub-graph comprising just the candidate nodes and their identified parents in the partial DAG. We further establish the structural learning consistency of our algorithm in the large-sample limit. Extensive experiments on synthetic and real-world datasets demonstrate that our method is computationally efficient, robust to model misspecification, and consistently outperforms many existing nonlinear DAG learning methods.
Scale Efficient Training for Large Datasets
Mar 17, 2025



The rapid growth of dataset scales has been a key driver in advancing deep learning research. However, as dataset scale increases, the training process becomes increasingly inefficient due to the presence of low-value samples, including excessive redundant samples, overly challenging samples, and inefficient easy samples that contribute little to model improvement.To address this challenge, we propose Scale Efficient Training (SeTa) for large datasets, a dynamic sample pruning approach that losslessly reduces training time. To remove low-value samples, SeTa first performs random pruning to eliminate redundant samples, then clusters the remaining samples according to their learning difficulty measured by loss. Building upon this clustering, a sliding window strategy is employed to progressively remove both overly challenging and inefficient easy clusters following an easy-to-hard curriculum.We conduct extensive experiments on large-scale synthetic datasets, including ToCa, SS1M, and ST+MJ, each containing over 3 million samples.SeTa reduces training costs by up to 50\% while maintaining or improving performance, with minimal degradation even at 70\% cost reduction. Furthermore, experiments on various scale real datasets across various backbones (CNNs, Transformers, and Mambas) and diverse tasks (instruction tuning, multi-view stereo, geo-localization, composed image retrieval, referring image segmentation) demonstrate the powerful effectiveness and universality of our approach. Code is available at https://github.com/mrazhou/SeTa.
A Benchmark for Multi-Lingual Vision-Language Learning in Remote Sensing Image Captioning
Mar 06, 2025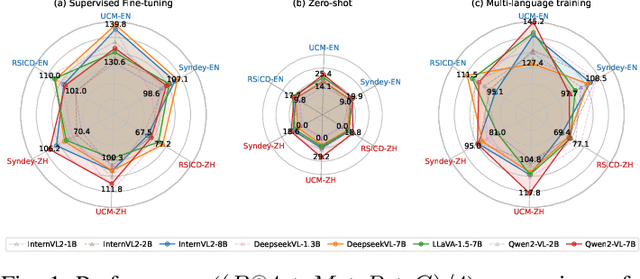

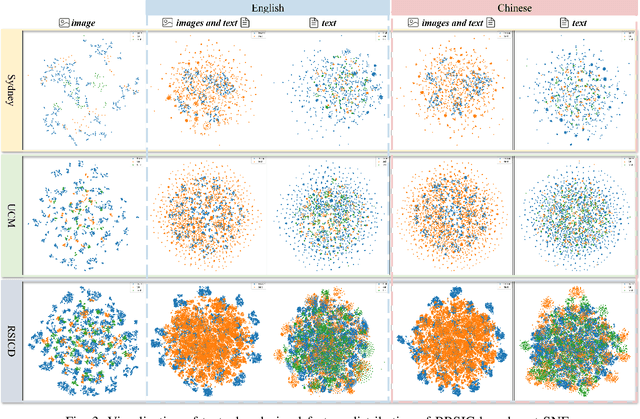
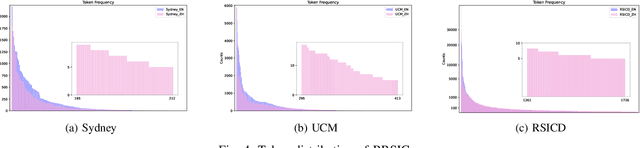
Remote Sensing Image Captioning (RSIC) is a cross-modal field bridging vision and language, aimed at automatically generating natural language descriptions of features and scenes in remote sensing imagery. Despite significant advances in developing sophisticated methods and large-scale datasets for training vision-language models (VLMs), two critical challenges persist: the scarcity of non-English descriptive datasets and the lack of multilingual capability evaluation for models. These limitations fundamentally impede the progress and practical deployment of RSIC, particularly in the era of large VLMs. To address these challenges, this paper presents several significant contributions to the field. First, we introduce and analyze BRSIC (Bilingual Remote Sensing Image Captioning), a comprehensive bilingual dataset that enriches three established English RSIC datasets with Chinese descriptions, encompassing 13,634 images paired with 68,170 bilingual captions. Building upon this foundation, we develop a systematic evaluation framework that addresses the prevalent inconsistency in evaluation protocols, enabling rigorous assessment of model performance through standardized retraining procedures on BRSIC. Furthermore, we present an extensive empirical study of eight state-of-the-art large vision-language models (LVLMs), examining their capabilities across multiple paradigms including zero-shot inference, supervised fine-tuning, and multi-lingual training. This comprehensive evaluation provides crucial insights into the strengths and limitations of current LVLMs in handling multilingual remote sensing tasks. Additionally, our cross-dataset transfer experiments reveal interesting findings. The code and data will be available at https://github.com/mrazhou/BRSIC.
Causal bandits with backdoor adjustment on unknown Gaussian DAGs
Feb 04, 2025The causal bandit problem aims to sequentially learn the intervention that maximizes the expectation of a reward variable within a system governed by a causal graph. Most existing approaches assume prior knowledge of the graph structure, or impose unrealistically restrictive conditions on the graph. In this paper, we assume a Gaussian linear directed acyclic graph (DAG) over arms and the reward variable, and study the causal bandit problem when the graph structure is unknown. We identify backdoor adjustment sets for each arm using sequentially generated experimental and observational data during the decision process, which allows us to estimate causal effects and construct upper confidence bounds. By integrating estimates from both data sources, we develop a novel bandit algorithm, based on modified upper confidence bounds, to sequentially determine the optimal intervention. We establish both case-dependent and case-independent upper bounds on the cumulative regret for our algorithm, which improve upon the bounds of the standard multi-armed bandit algorithms. Our empirical study demonstrates its advantage over existing methods with respect to cumulative regret and computation time.
Causal Discovery on Dependent Binary Data
Dec 28, 2024


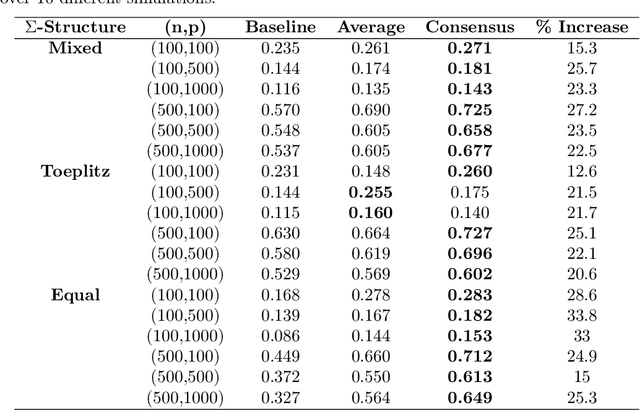
The assumption of independence between observations (units) in a dataset is prevalent across various methodologies for learning causal graphical models. However, this assumption often finds itself in conflict with real-world data, posing challenges to accurate structure learning. We propose a decorrelation-based approach for causal graph learning on dependent binary data, where the local conditional distribution is defined by a latent utility model with dependent errors across units. We develop a pairwise maximum likelihood method to estimate the covariance matrix for the dependence among the units. Then, leveraging the estimated covariance matrix, we develop an EM-like iterative algorithm to generate and decorrelate samples of the latent utility variables, which serve as decorrelated data. Any standard causal discovery method can be applied on the decorrelated data to learn the underlying causal graph. We demonstrate that the proposed decorrelation approach significantly improves the accuracy in causal graph learning, through numerical experiments on both synthetic and real-world datasets.