 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Spectral Flattening of Quantized Embeddings
Feb 01, 2026Training Large Language Models (LLMs) at ultra-low precision is critically impeded by instability rooted in the conflict between discrete quantization constraints and the intrinsic heavy-tailed spectral nature of linguistic data. By formalizing the connection between Zipfian statistics and random matrix theory, we prove that the power-law decay in the singular value spectra of embeddings is a fundamental requisite for semantic encoding. We derive theoretical bounds showing that uniform quantization introduces a noise floor that disproportionately truncates this spectral tail, which induces spectral flattening and a strictly provable increase in the stable rank of representations. Empirical validation across diverse architectures including GPT-2 and TinyLlama corroborates that this geometric degradation precipitates representational collapse. This work not only quantifies the spectral sensitivity of LLMs but also establishes spectral fidelity as a necessary condition for stable low-bit optimization.
Bandwidth-Aware and Overlap-Weighted Compression for Communication-Efficient Federated Learning
Aug 27, 2024
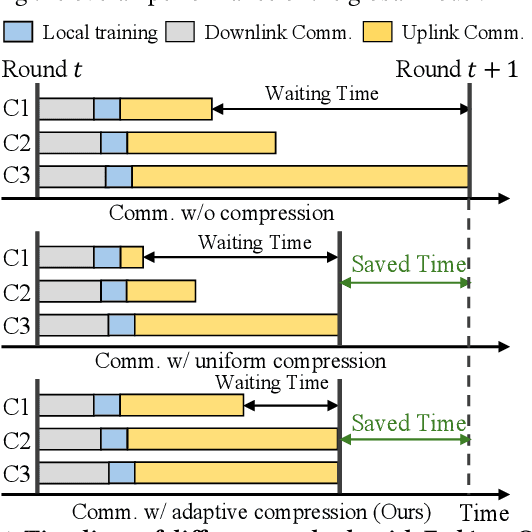

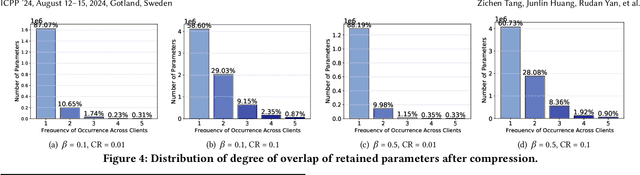
Current data compression methods, such as sparsification in Federated Averaging (FedAvg), effectively enhance the communication efficiency of Federated Learning (FL). However, these methods encounter challenges such as the straggler problem and diminished model performance due to heterogeneous bandwidth and non-IID (Independently and Identically Distributed) data. To address these issues, we introduce a bandwidth-aware compression framework for FL, aimed at improving communication efficiency while mitigating the problems associated with non-IID data. First, our strategy dynamically adjusts compression ratios according to bandwidth, enabling clients to upload their models at a close pace, thus exploiting the otherwise wasted time to transmit more data. Second, we identify the non-overlapped pattern of retained parameters after compression, which results in diminished client update signals due to uniformly averaged weights. Based on this finding, we propose a parameter mask to adjust the client-averaging coefficients at the parameter level, thereby more closely approximating the original updates, and improving the training convergence under heterogeneous environments. Our evaluations reveal that our method significantly boosts model accuracy, with a maximum improvement of 13% over the uncompressed FedAvg. Moreover, it achieves a $3.37\times$ speedup in reaching the target accuracy compared to FedAvg with a Top-K compressor, demonstrating its effectiveness in accelerating convergence with compression. The integration of common compression techniques into our framework further establishes its potential as a versatile foundation for future cross-device, communication-efficient FL research, addressing critical challenges in FL and advancing the field of distributed machine learning.
Text-only Synthesis for Image Captioning
May 28, 2024



From paired image-text training to text-only training for image captioning, the pursuit of relaxing the requirements for high-cost and large-scale annotation of good quality data remains consistent. In this paper, we propose Text-only Synthesis for Image Captioning (ToCa), which further advances this relaxation with fewer human labor and less computing time. Specifically, we deconstruct caption text into structures and lexical words, which serve as the fundamental components of the caption. By combining different structures and lexical words as inputs to the large language model, massive captions that contain various patterns of lexical words are generated. This method not only approaches the target domain but also surpasses it by generating new captions, thereby enhancing the zero-shot generalization ability of the model. Considering the different levels of data access in the real world, we define three synthesis scenarios: cross-domain synthesis, in-domain synthesis, and data-efficient synthesis. Experiments in these scenarios demonstrate the generalizability, transferability and practicability of ToCa with a nearly 5 CIDEr improvement for zero-shot cross-domain captioning and a maximum increase of over 20 CIDEr for data-efficient captioning.
Spatio-Temporal Field Neural Networks for Air Quality Inference
Mar 02, 2024



The air quality inference problem aims to utilize historical data from a limited number of observation sites to infer the air quality index at an unknown location. Considering the sparsity of data due to the high maintenance cost of the stations, good inference algorithms can effectively save the cost and refine the data granularity. While spatio-temporal graph neural networks have made excellent progress on this problem, their non-Euclidean and discrete data structure modeling of reality limits its potential. In this work, we make the first attempt to combine two different spatio-temporal perspectives, fields and graphs, by proposing a new model, Spatio-Temporal Field Neural Network, and its corresponding new framework, Pyramidal Inference. Extensive experiments validate that our model achieves state-of-the-art performance in nationwide air quality inference in the Chinese Mainland, demonstrating the superiority of our proposed model and framework.
Automatic Radio Map Adaptation for Robust Localization with Dynamic Adversarial Learning
Feb 19, 2024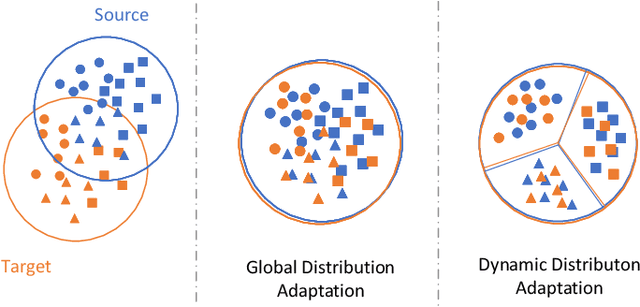
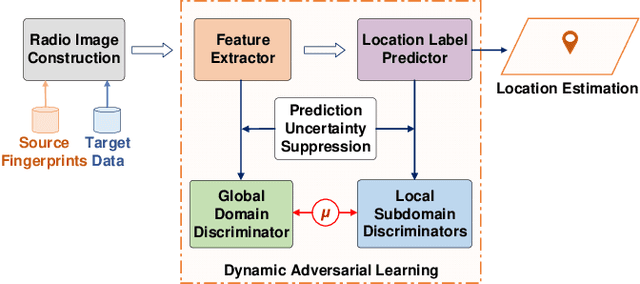
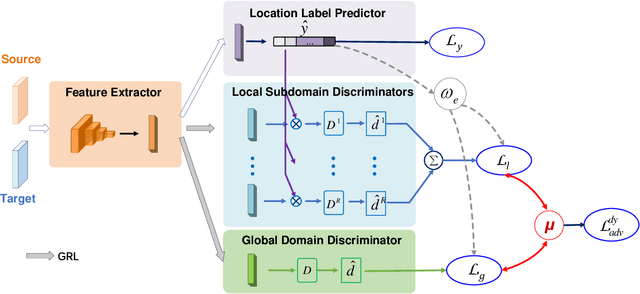
Wireless fingerprint-based localization has become one of the most promising technologies for ubiquitous location-aware computing and intelligent location-based services. However, due to RF vulnerability to environmental dynamics over time, continuous radio map updates are time-consuming and infeasible, resulting in severe accuracy degradation. To address this issue, we propose a novel approach of robust localization with dynamic adversarial learning, known as DadLoc which realizes automatic radio map adaptation by incorporating multiple robust factors underlying RF fingerprints to learn the evolving feature representation with the complicated environmental dynamics. DadLoc performs a finer-grained distribution adaptation with the developed dynamic adversarial adaptation network and quantifies the contributions of both global and local distribution adaptation in a dynamics-adaptive manner. Furthermore, we adopt the strategy of prediction uncertainty suppression to conduct source-supervised training, target-unsupervised training, and source-target dynamic adversarial adaptation which can trade off the environment adaptability and the location discriminability of the learned deep representation for safe and effective feature transfer across different environments. With extensive experimental results, the satisfactory accuracy over other comparative schemes demonstrates that the proposed DanLoc can facilitate fingerprint-based localization for wide deployments.
A geometry method for LED mapping
Oct 28, 2022



With inputs from RGB-D camera, industrial camera and wheel odometer, in this letter, we propose a geometry-based detecting method, by which the 3-D modulated LED map can be acquired with the aid of visual odometry algorithm from ORB-SLAM2 system when the decoding result of LED-ID is inaccurate. Subsequently, an enhanced cost function is proposed to optimize the mapping result of LEDs. The average 3-D mapping error (8.5cm) is evaluated with a real-world experiment. This work can be viewed as a preliminary work of visible light positioning systems, offering a way to prevent the labor-intensive manual site surveys of LEDs.