 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpochX: Building the Infrastructure for an Emergent Agent Civilization
Mar 28, 2026General-purpose technologies reshape economies less by improving individual tools than by enabling new ways to organize production and coordination. We believe AI agents are approaching a similar inflection point: as foundation models make broad task execution and tool use increasingly accessible, the binding constraint shifts from raw capability to how work is delegated, verified, and rewarded at scale. We introduce EpochX, a credits-native marketplace infrastructure for human-agent production networks. EpochX treats humans and agents as peer participants who can post tasks or claim them. Claimed tasks can be decomposed into subtasks and executed through an explicit delivery workflow with verification and acceptance. Crucially, EpochX is designed so that each completed transaction can produce reusable ecosystem assets, including skills, workflows, execution traces, and distilled experience. These assets are stored with explicit dependency structure, enabling retrieval, composition, and cumulative improvement over time. EpochX also introduces a native credit mechanism to make participation economically viable under real compute costs. Credits lock task bounties, budget delegation, settle rewards upon acceptance, and compensate creators when verified assets are reused. By formalizing the end-to-end transaction model together with its asset and incentive layers, EpochX reframes agentic AI as an organizational design problem: building infrastructures where verifiable work leaves persistent, reusable artifacts, and where value flows support durable human-agent collaboration.
Are Dilemmas and Conflicts in LLM Alignment Solvable? A View from Priority Graph
Mar 16, 2026As Large Language Models (LLMs) become more powerful and autonomous, they increasingly face conflicts and dilemmas in many scenarios. We first summarize and taxonomize these diverse conflicts. Then, we model the LLM's preferences to make different choices as a priority graph, where instructions and values are nodes, and the edges represent context-specific priorities determined by the model's output distribution. This graph reveals that a unified stable LLM alignment is very challenging, because the graph is neither static nor necessarily consistent in different contexts. Besides, it also reveals a potential vulnerability: priority hacking, where adversaries can craft deceptive contexts to manipulate the graph and bypass safety alignments. To counter this, we propose a runtime verification mechanism, enabling LLMs to query external sources to ground their context and resist manipulation. While this approach enhances robustness, we also acknowledge that many ethical and value dilemmas are philosophically irreducible, posing a long-term, open challenge for the future of AI alignment.
OmniReview: A Large-scale Benchmark and LLM-enhanced Framework for Realistic Reviewer Recommendation
Feb 09, 2026Academic peer review remains the cornerstone of scholarly validation, yet the field faces some challenges in data and methods. From the data perspective, existing research is hindered by the scarcity of large-scale, verified benchmarks and oversimplified evaluation metrics that fail to reflect real-world editorial workflows. To bridge this gap, we present OmniReview, a comprehensive dataset constructed by integrating multi-source academic platforms encompassing comprehensive scholarly profiles through the disambiguation pipeline, yielding 202, 756 verified review records. Based on this data, we introduce a three-tier hierarchical evaluaion framework to assess recommendations from recall to precise expert identification. From the method perspective, existing embedding-based approaches suffer from the information bottleneck of semantic compression and limited interpretability. To resolve these method limitations, we propose Profiling Scholars with Multi-gate Mixture-of-Experts (Pro-MMoE), a novel framework that synergizes Large Language Models (LLMs) with Multi-task Learning. Specifically, it utilizes LLM-generated semantic profiles to preserve fine-grained expertise nuances and interpretability, while employing a Task-Adaptive MMoE architecture to dynamically balance conflicting evaluation goals. Comprehensive experiments demonstrate that Pro-MMoE achieves state-of-the-art performance across six of seven metrics, establishing a new benchmark for realistic reviewer recommendation.
Dissecting Outlier Dynamics in LLM NVFP4 Pretraining
Feb 02, 2026Training large language models using 4-bit arithmetic enhances throughput and memory efficiency. Yet, the limited dynamic range of FP4 increases sensitivity to outliers. While NVFP4 mitigates quantization error via hierarchical microscaling, a persistent loss gap remains compared to BF16. This study conducts a longitudinal analysis of outlier dynamics across architecture during NVFP4 pretraining, focusing on where they localize, why they occur, and how they evolve temporally. We find that, compared with Softmax Attention (SA), Linear Attention (LA) reduces per-tensor heavy tails but still exhibits persistent block-level spikes under block quantization. Our analysis attributes outliers to specific architectural components: Softmax in SA, gating in LA, and SwiGLU in FFN, with "post-QK" operations exhibiting higher sensitivity to quantization. Notably, outliers evolve from transient spikes early in training to a small set of persistent hot channels (i.e., channels with persistently large magnitudes) in later stages. Based on these findings, we introduce Hot-Channel Patch (HCP), an online compensation mechanism that identifies hot channels and reinjects residuals using hardware-efficient kernels. We then develop CHON, an NVFP4 training recipe integrating HCP with post-QK operation protection. On GLA-1.3B model trained for 60B tokens, CHON reduces the loss gap to BF16 from 0.94% to 0.58% while maintaining downstream accuracy.
On the Spectral Flattening of Quantized Embeddings
Feb 01, 2026Training Large Language Models (LLMs) at ultra-low precision is critically impeded by instability rooted in the conflict between discrete quantization constraints and the intrinsic heavy-tailed spectral nature of linguistic data. By formalizing the connection between Zipfian statistics and random matrix theory, we prove that the power-law decay in the singular value spectra of embeddings is a fundamental requisite for semantic encoding. We derive theoretical bounds showing that uniform quantization introduces a noise floor that disproportionately truncates this spectral tail, which induces spectral flattening and a strictly provable increase in the stable rank of representations. Empirical validation across diverse architectures including GPT-2 and TinyLlama corroborates that this geometric degradation precipitates representational collapse. This work not only quantifies the spectral sensitivity of LLMs but also establishes spectral fidelity as a necessary condition for stable low-bit optimization.
EvoFSM: Controllable Self-Evolution for Deep Research with Finite State Machines
Jan 14, 2026While LLM-based agents have shown promise for deep research, most existing approaches rely on fixed workflows that struggle to adapt to real-world, open-ended queries. Recent work therefore explores self-evolution by allowing agents to rewrite their own code or prompts to improve problem-solving ability, but unconstrained optimization often triggers instability, hallucinations, and instruction drift. We propose EvoFSM, a structured self-evolving framework that achieves both adaptability and control by evolving an explicit Finite State Machine (FSM) instead of relying on free-form rewriting. EvoFSM decouples the optimization space into macroscopic Flow (state-transition logic) and microscopic Skill (state-specific behaviors), enabling targeted improvements under clear behavioral boundaries. Guided by a critic mechanism, EvoFSM refines the FSM through a small set of constrained operations, and further incorporates a self-evolving memory that distills successful trajectories as reusable priors and failure patterns as constraints for future queries. Extensive evaluations on five multi-hop QA benchmarks demonstrate the effectiveness of EvoFSM. In particular, EvoFSM reaches 58.0% accuracy on the DeepSearch benchmark. Additional results on interactive decision-making tasks further validate its generalization.
CloneMem: Benchmarking Long-Term Memory for AI Clones
Jan 11, 2026AI Clones aim to simulate an individual's thoughts and behaviors to enable long-term, personalized interaction, placing stringent demands on memory systems to model experiences, emotions, and opinions over time. Existing memory benchmarks primarily rely on user-agent conversational histories, which are temporally fragmented and insufficient for capturing continuous life trajectories. We introduce CloneMem, a benchmark for evaluating longterm memory in AI Clone scenarios grounded in non-conversational digital traces, including diaries, social media posts, and emails, spanning one to three years. CloneMem adopts a hierarchical data construction framework to ensure longitudinal coherence and defines tasks that assess an agent's ability to track evolving personal states. Experiments show that current memory mechanisms struggle in this setting, highlighting open challenges for life-grounded personalized AI. Code and dataset are available at https://github.com/AvatarMemory/CloneMemBench
Efficient MoE Inference with Fine-Grained Scheduling of Disaggregated Expert Parallelism
Dec 25, 2025



The mixture-of-experts (MoE) architecture scales model size with sublinear computational increase but suffers from memory-intensive inference due to KV caches and sparse expert activation. Recent disaggregated expert parallelism (DEP) distributes attention and experts to dedicated GPU groups but lacks support for shared experts and efficient task scheduling, limiting performance. We propose FinDEP, a fine-grained task scheduling algorithm for DEP that maximizes task overlap to improve MoE inference throughput. FinDEP introduces three innovations: 1) partitioning computation/communication into smaller tasks for fine-grained pipelining, 2) formulating a scheduling optimization supporting variable granularity and ordering, and 3) developing an efficient solver for this large search space. Experiments on four GPU systems with DeepSeek-V2 and Qwen3-MoE show FinDEP improves throughput by up to 1.61x over prior methods, achieving up to 1.24x speedup on a 32-GPU system.
Octopus: Agentic Multimodal Reasoning with Six-Capability Orchestration
Nov 19, 2025Existing multimodal reasoning models and frameworks suffer from fundamental architectural limitations: most lack the human-like ability to autonomously explore diverse reasoning pathways-whether in direct inference, tool-driven visual exploration, programmatic visual manipulation, or intrinsic visual imagination. Consequently, they struggle to adapt to dynamically changing capability requirements in real-world tasks. Meanwhile, humans exhibit a complementary set of thinking abilities when addressing such tasks, whereas existing methods typically cover only a subset of these dimensions. Inspired by this, we propose Octopus: Agentic Multimodal Reasoning with Six-Capability Orchestration, a new paradigm for multimodal agentic reasoning. We define six core capabilities essential for multimodal reasoning and organize a comprehensive evaluation benchmark, Octopus-Bench, accordingly. Octopus is capable of autonomously exploring during reasoning and dynamically selecting the most appropriate capability based on the current state. Experimental results show that Octopus achieves the best performance on the vast majority of tasks in Octopus-Bench, highlighting the crucial role of capability coordination in agentic multimodal reasoning.
GitTaskBench: A Benchmark for Code Agents Solving Real-World Tasks Through Code Repository Leveraging
Aug 26, 2025

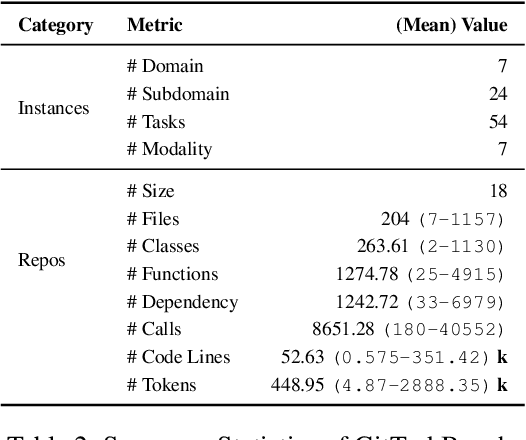
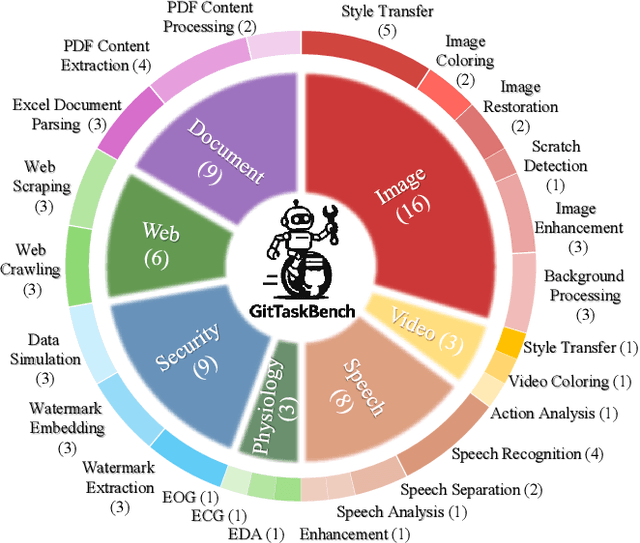
Beyond scratch coding, exploiting large-scale code repositories (e.g., GitHub) for practical tasks is vital in real-world software development, yet current benchmarks rarely evaluate code agents in such authentic, workflow-driven scenarios. To bridge this gap, we introduce GitTaskBench, a benchmark designed to systematically assess this capability via 54 realistic tasks across 7 modalities and 7 domains. Each task pairs a relevant repository with an automated, human-curated evaluation harness specifying practical success criteria. Beyond measuring execution and task success, we also propose the alpha-value metric to quantify the economic benefit of agent performance, which integrates task success rates, token cost, and average developer salaries. Experiments across three state-of-the-art agent frameworks with multiple advanced LLMs show that leveraging code repositories for complex task solving remains challenging: even the best-performing system, OpenHands+Claude 3.7, solves only 48.15% of tasks. Error analysis attributes over half of failures to seemingly mundane yet critical steps like environment setup and dependency resolution, highlighting the need for more robust workflow management and increased timeout preparedness. By releasing GitTaskBench, we aim to drive progress and attention toward repository-aware code reasoning, execution, and deployment -- moving agents closer to solving complex, end-to-end real-world tasks. The benchmark and code are open-sourced at https://github.com/QuantaAlpha/GitTaskBench.