 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-shot Federated Learning Methods: A Practical Guide
Feb 13, 2025One-shot Federated Learning (OFL) is a distributed machine learning paradigm that constrains client-server communication to a single round, addressing privacy and communication overhead issues associated with multiple rounds of data exchange in traditional Federated Learning (FL). OFL demonstrates the practical potential for integration with future approaches that require collaborative training models, such as large language models (LLMs). However, current OFL methods face two major challenges: data heterogeneity and model heterogeneity, which result in subpar performance compared to conventional FL methods. Worse still, despite numerous studies addressing these limitations, a comprehensive summary is still lacking. To address these gaps, this paper presents a systematic analysis of the challenges faced by OFL and thoroughly reviews the current methods. We also offer an innovative categorization method and analyze the trade-offs of various techniques. Additionally, we discuss the most promising future directions and the technologies that should be integrated into the OFL field. This work aims to provide guidance and insights for future research.
Automatic Pruning via Structured Lasso with Class-wise Information
Feb 13, 2025Most pruning methods concentrate on unimportant filters of neural networks. However, they face the loss of statistical information due to a lack of consideration for class-wise data. In this paper, from the perspective of leveraging precise class-wise information for model pruning, we utilize structured lasso with guidance from Information Bottleneck theory. Our approach ensures that statistical information is retained during the pruning process. With these techniques, we introduce two innovative adaptive network pruning schemes: sparse graph-structured lasso pruning with Information Bottleneck (\textbf{sGLP-IB}) and sparse tree-guided lasso pruning with Information Bottleneck (\textbf{sTLP-IB}). The key aspect is pruning model filters using sGLP-IB and sTLP-IB to better capture class-wise relatedness. Compared to multiple state-of-the-art methods, our approaches demonstrate superior performance across three datasets and six model architectures in extensive experiments. For instance, using the VGG16 model on the CIFAR-10 dataset, we achieve a parameter reduction of 85%, a decrease in FLOPs by 61%, and maintain an accuracy of 94.10% (0.14% higher than the original model); we reduce the parameters by 55% with the accuracy at 76.12% using the ResNet architecture on ImageNet (only drops 0.03%). In summary, we successfully reduce model size and computational resource usage while maintaining accuracy. Our codes are at https://anonymous.4open.science/r/IJCAI-8104.
ED-ViT: Splitting Vision Transformer for Distributed Inference on Edge Devices
Oct 15, 2024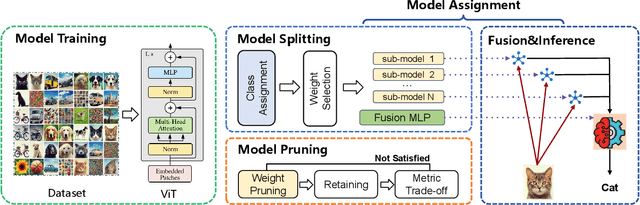

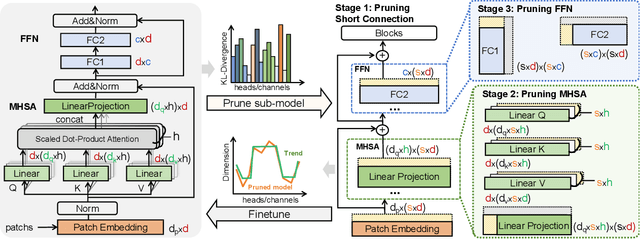
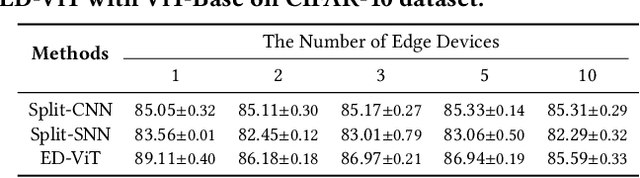
Deep learning models are increasingly deployed on resource-constrained edge devices for real-time data analytics. In recent years, Vision Transformer models and their variants have demonstrated outstanding performance across various computer vision tasks. However, their high computational demands and inference latency pose significant challenges for model deployment on resource-constraint edge devices. To address this issue, we propose a novel Vision Transformer splitting framework, ED-ViT, designed to execute complex models across multiple edge devices efficiently. Specifically, we partition Vision Transformer models into several sub-models, where each sub-model is tailored to handle a specific subset of data classes. To further minimize computation overhead and inference latency, we introduce a class-wise pruning technique that reduces the size of each sub-model. We conduct extensive experiments on five datasets with three model structures, demonstrating that our approach significantly reduces inference latency on edge devices and achieves a model size reduction of up to 28.9 times and 34.1 times, respectively, while maintaining test accuracy comparable to the original Vision Transformer. Additionally, we compare ED-ViT with two state-of-the-art methods that deploy CNN and SNN models on edge devices, evaluating accuracy, inference time, and overall model size. Our comprehensive evaluation underscores the effectiveness of the proposed ED-ViT framework.
Weakly-Supervised Multi-Level Attentional Reconstruction Network for Grounding Textual Queries in Videos
Mar 16, 2020

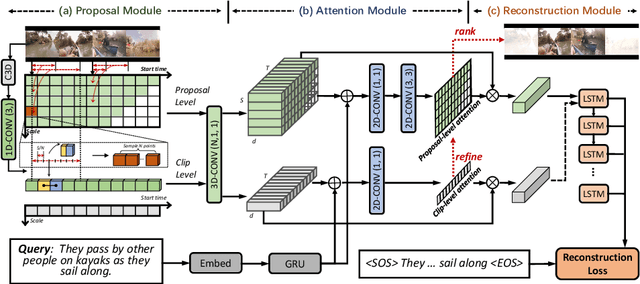

The task of temporally grounding textual queries in videos is to localize one video segment that semantically corresponds to the given query. Most of the existing approaches rely on segment-sentence pairs (temporal annotations) for training, which are usually unavailable in real-world scenarios. In this work we present an effective weakly-supervised model, named as Multi-Level Attentional Reconstruction Network (MARN), which only relies on video-sentence pairs during the training stage. The proposed method leverages the idea of attentional reconstruction and directly scores the candidate segments with the learnt proposal-level attentions. Moreover, another branch learning clip-level attention is exploited to refine the proposals at both the training and testing stage. We develop a novel proposal sampling mechanism to leverage intra-proposal information for learning better proposal representation and adopt 2D convolution to exploit inter-proposal clues for learning reliable attention map. Experiments on Charades-STA and ActivityNet-Captions datasets demonstrate the superiority of our MARN over the existing weakly-supervised methods.