 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSettleFL: Trustless and Scalable Reward Settlement Protocol for Federated Learning on Permissionless Blockchains (Extended version)
Feb 26, 2026In open Federated Learning (FL) environments where no central authority exists, ensuring collaboration fairness relies on decentralized reward settlement, yet the prohibitive cost of permissionless blockchains directly clashes with the high-frequency, iterative nature of model training. Existing solutions either compromise decentralization or suffer from scalability bottlenecks due to linear on-chain costs. To address this, we present SettleFL, a trustless and scalable reward settlement protocol designed to minimize total economic friction by offering a family of two interoperable protocols. Leveraging a shared domain-specific circuit architecture, SettleFL offers two interoperable strategies: (1) a Commit-and-Challenge variant that minimizes on-chain costs via optimistic execution and dispute-driven arbitration, and (2) a Commit-with-Proof variant that guarantees instant finality through per-round validity proofs. This design allows the protocol to flexibly adapt to varying latency and cost constraints while enforcing rational robustness without trusted coordination. We conduct extensive experiments combining real FL workloads and controlled simulations. Results show that SettleFL remains practical when scaling to 800 participants, achieving substantially lower gas cost.
POLAR: Policy-based Layerwise Reinforcement Learning Method for Stealthy Backdoor Attacks in Federated Learning
Oct 21, 2025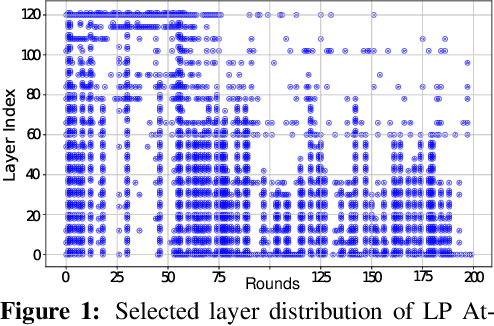



Federated Learning (FL) enables decentralized model training across multiple clients without exposing local data, but its distributed feature makes it vulnerable to backdoor attacks. Despite early FL backdoor attacks modifying entire models, recent studies have explored the concept of backdoor-critical (BC) layers, which poison the chosen influential layers to maintain stealthiness while achieving high effectiveness. However, existing BC layers approaches rely on rule-based selection without consideration of the interrelations between layers, making them ineffective and prone to detection by advanced defenses. In this paper, we propose POLAR (POlicy-based LAyerwise Reinforcement learning), the first pipeline to creatively adopt RL to solve the BC layer selection problem in layer-wise backdoor attack. Different from other commonly used RL paradigm, POLAR is lightweight with Bernoulli sampling. POLAR dynamically learns an attack strategy, optimizing layer selection using policy gradient updates based on backdoor success rate (BSR) improvements. To ensure stealthiness, we introduce a regularization constraint that limits the number of modified layers by penalizing large attack footprints. Extensive experiments demonstrate that POLAR outperforms the latest attack methods by up to 40% against six state-of-the-art (SOTA) defenses.
Hypernetworks for Model-Heterogeneous Personalized Federated Learning
Jul 30, 2025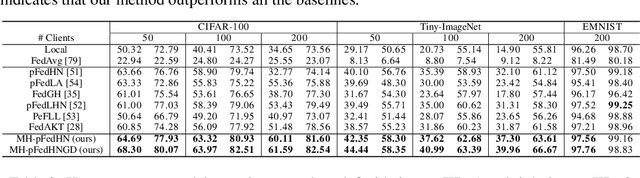
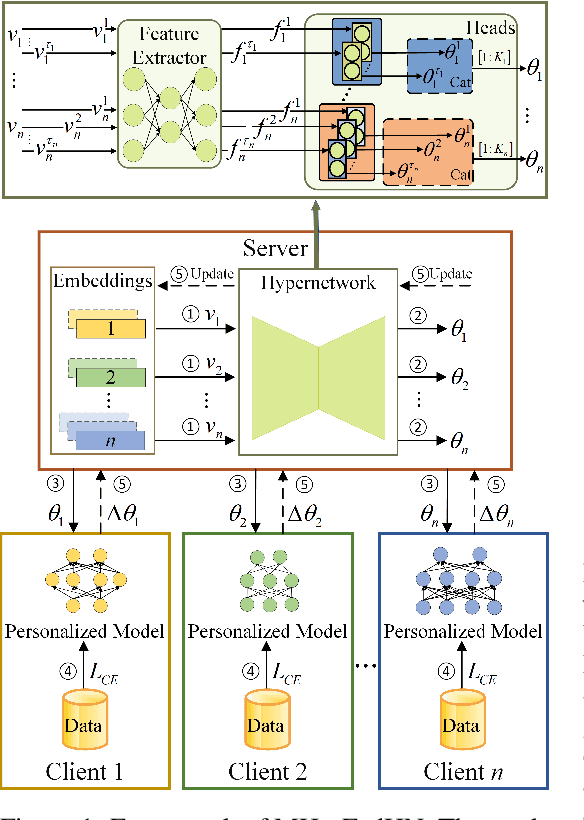
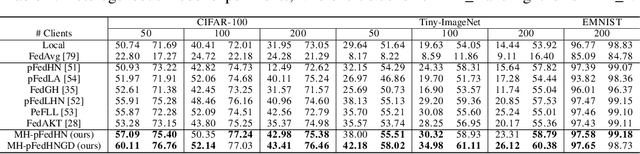

Recent advances in personalized federated learning have focused on addressing client model heterogeneity. However, most existing methods still require external data, rely on model decoupling, or adopt partial learning strategies, which can limit their practicality and scalability. In this paper, we revisit hypernetwork-based methods and leverage their strong generalization capabilities to design a simple yet effective framework for heterogeneous personalized federated learning. Specifically, we propose MH-pFedHN, which leverages a server-side hypernetwork that takes client-specific embedding vectors as input and outputs personalized parameters tailored to each client's heterogeneous model. To promote knowledge sharing and reduce computation, we introduce a multi-head structure within the hypernetwork, allowing clients with similar model sizes to share heads. Furthermore, we further propose MH-pFedHNGD, which integrates an optional lightweight global model to improve generalization. Our framework does not rely on external datasets and does not require disclosure of client model architectures, thereby offering enhanced privacy and flexibility. Extensive experiments on multiple benchmarks and model settings demonstrate that our approach achieves competitive accuracy, strong generalization, and serves as a robust baseline for future research in model-heterogeneous personalized federated learning.
Edge Intelligence with Spiking Neural Networks
Jul 18, 2025The convergence of artificial intelligence and edge computing has spurred growing interest in enabling intelligent services directly on resource-constrained devices. While traditional deep learning models require significant computational resources and centralized data management, the resulting latency, bandwidth consumption, and privacy concerns have exposed critical limitations in cloud-centric paradigms. Brain-inspired computing, particularly Spiking Neural Networks (SNNs), offers a promising alternative by emulating biological neuronal dynamics to achieve low-power, event-driven computation. This survey provides a comprehensive overview of Edge Intelligence based on SNNs (EdgeSNNs), examining their potential to address the challenges of on-device learning, inference, and security in edge scenarios. We present a systematic taxonomy of EdgeSNN foundations, encompassing neuron models, learning algorithms, and supporting hardware platforms. Three representative practical considerations of EdgeSNN are discussed in depth: on-device inference using lightweight SNN models, resource-aware training and updating under non-stationary data conditions, and secure and privacy-preserving issues. Furthermore, we highlight the limitations of evaluating EdgeSNNs on conventional hardware and introduce a dual-track benchmarking strategy to support fair comparisons and hardware-aware optimization. Through this study, we aim to bridge the gap between brain-inspired learning and practical edge deployment, offering insights into current advancements, open challenges, and future research directions. To the best of our knowledge, this is the first dedicated and comprehensive survey on EdgeSNNs, providing an essential reference for researchers and practitioners working at the intersection of neuromorphic computing and edge intelligence.
Automatic Pruning via Structured Lasso with Class-wise Information
Feb 13, 2025Most pruning methods concentrate on unimportant filters of neural networks. However, they face the loss of statistical information due to a lack of consideration for class-wise data. In this paper, from the perspective of leveraging precise class-wise information for model pruning, we utilize structured lasso with guidance from Information Bottleneck theory. Our approach ensures that statistical information is retained during the pruning process. With these techniques, we introduce two innovative adaptive network pruning schemes: sparse graph-structured lasso pruning with Information Bottleneck (\textbf{sGLP-IB}) and sparse tree-guided lasso pruning with Information Bottleneck (\textbf{sTLP-IB}). The key aspect is pruning model filters using sGLP-IB and sTLP-IB to better capture class-wise relatedness. Compared to multiple state-of-the-art methods, our approaches demonstrate superior performance across three datasets and six model architectures in extensive experiments. For instance, using the VGG16 model on the CIFAR-10 dataset, we achieve a parameter reduction of 85%, a decrease in FLOPs by 61%, and maintain an accuracy of 94.10% (0.14% higher than the original model); we reduce the parameters by 55% with the accuracy at 76.12% using the ResNet architecture on ImageNet (only drops 0.03%). In summary, we successfully reduce model size and computational resource usage while maintaining accuracy. Our codes are at https://anonymous.4open.science/r/IJCAI-8104.
One-shot Federated Learning Methods: A Practical Guide
Feb 13, 2025One-shot Federated Learning (OFL) is a distributed machine learning paradigm that constrains client-server communication to a single round, addressing privacy and communication overhead issues associated with multiple rounds of data exchange in traditional Federated Learning (FL). OFL demonstrates the practical potential for integration with future approaches that require collaborative training models, such as large language models (LLMs). However, current OFL methods face two major challenges: data heterogeneity and model heterogeneity, which result in subpar performance compared to conventional FL methods. Worse still, despite numerous studies addressing these limitations, a comprehensive summary is still lacking. To address these gaps, this paper presents a systematic analysis of the challenges faced by OFL and thoroughly reviews the current methods. We also offer an innovative categorization method and analyze the trade-offs of various techniques. Additionally, we discuss the most promising future directions and the technologies that should be integrated into the OFL field. This work aims to provide guidance and insights for future research.
FedLEC: Effective Federated Learning Algorithm with Spiking Neural Networks Under Label Skews
Dec 23, 2024With the advancement of neuromorphic chips, implementing Federated Learning (FL) with Spiking Neural Networks (SNNs) potentially offers a more energy-efficient schema for collaborative learning across various resource-constrained edge devices. However, one significant challenge in the FL systems is that the data from different clients are often non-independently and identically distributed (non-IID), with label skews presenting substantial difficulties in various federated SNN learning tasks. In this study, we propose a practical post-hoc framework named FedLEC to address the challenge. This framework penalizes the corresponding local logits for locally missing labels to enhance each local model's generalization ability. Additionally, it leverages the pertinent label distribution information distilled from the global model to mitigate label bias. Extensive experiments with three different structured SNNs across five datasets (i.e., three non-neuromorphic and two neuromorphic datasets) demonstrate the efficiency of FedLEC. Compared to seven state-of-the-art FL algorithms, FedLEC achieves an average accuracy improvement of approximately 11.59\% under various label skew distribution settings.
"They've Stolen My GPL-Licensed Model!": Toward Standardized and Transparent Model Licensing
Dec 16, 2024



As model parameter sizes reach the billion-level range and their training consumes zettaFLOPs of computation, components reuse and collaborative development are become increasingly prevalent in the Machine Learning (ML) community. These components, including models, software, and datasets, may originate from various sources and be published under different licenses, which govern the use and distribution of licensed works and their derivatives. However, commonly chosen licenses, such as GPL and Apache, are software-specific and are not clearly defined or bounded in the context of model publishing. Meanwhile, the reused components may also have free-content licenses and model licenses, which pose a potential risk of license noncompliance and rights infringement within the model production workflow. In this paper, we propose addressing the above challenges along two lines: 1) For license analysis, we have developed a new vocabulary for ML workflow management and encoded license rules to enable ontological reasoning for analyzing rights granting and compliance issues. 2) For standardized model publishing, we have drafted a set of model licenses that provide flexible options to meet the diverse needs of model publishing. Our analysis tool is built on Turtle language and Notation3 reasoning engine, envisioned as a first step toward Linked Open Model Production Data. We have also encoded our proposed model licenses into rules and demonstrated the effects of GPL and other commonly used licenses in model publishing, along with the flexibility advantages of our licenses, through comparisons and experiments.
ED-ViT: Splitting Vision Transformer for Distributed Inference on Edge Devices
Oct 15, 2024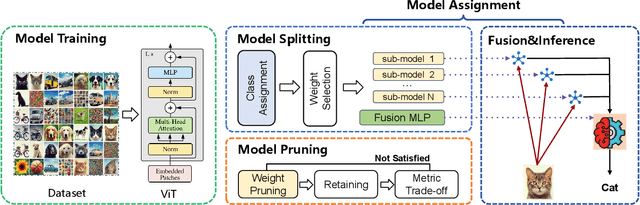

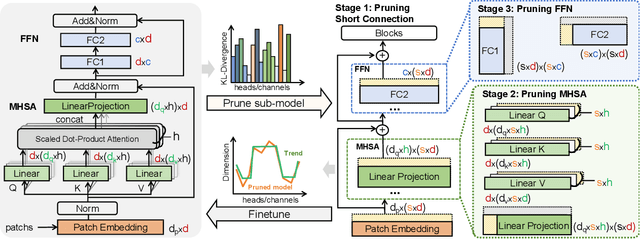
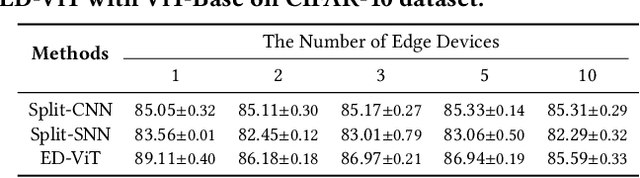
Deep learning models are increasingly deployed on resource-constrained edge devices for real-time data analytics. In recent years, Vision Transformer models and their variants have demonstrated outstanding performance across various computer vision tasks. However, their high computational demands and inference latency pose significant challenges for model deployment on resource-constraint edge devices. To address this issue, we propose a novel Vision Transformer splitting framework, ED-ViT, designed to execute complex models across multiple edge devices efficiently. Specifically, we partition Vision Transformer models into several sub-models, where each sub-model is tailored to handle a specific subset of data classes. To further minimize computation overhead and inference latency, we introduce a class-wise pruning technique that reduces the size of each sub-model. We conduct extensive experiments on five datasets with three model structures, demonstrating that our approach significantly reduces inference latency on edge devices and achieves a model size reduction of up to 28.9 times and 34.1 times, respectively, while maintaining test accuracy comparable to the original Vision Transformer. Additionally, we compare ED-ViT with two state-of-the-art methods that deploy CNN and SNN models on edge devices, evaluating accuracy, inference time, and overall model size. Our comprehensive evaluation underscores the effectiveness of the proposed ED-ViT framework.
FedLPA: Personalized One-shot Federated Learning with Layer-Wise Posterior Aggregation
Oct 03, 2023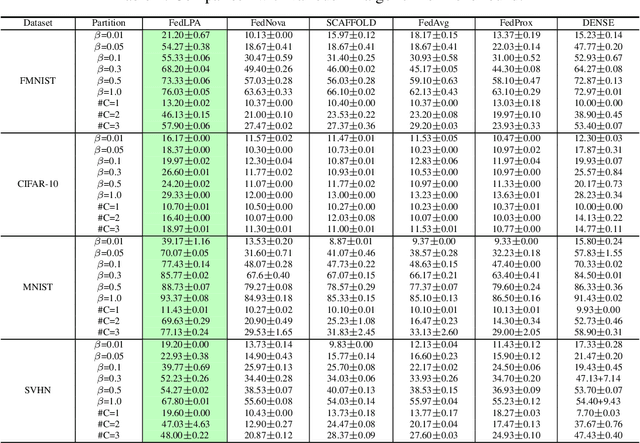
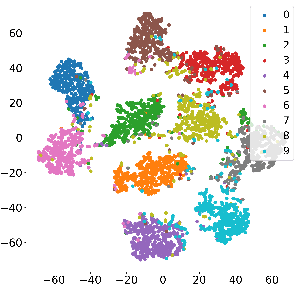
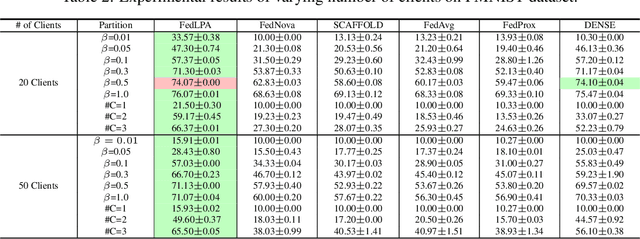
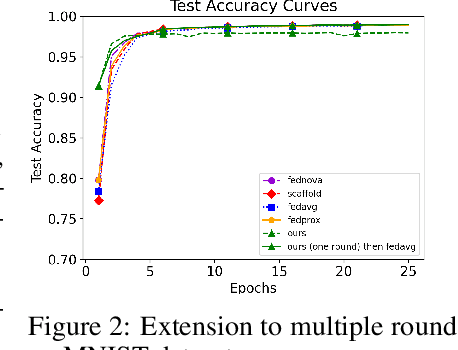
Efficiently aggregating trained neural networks from local clients into a global model on a server is a widely researched topic in federated learning. Recently, motivated by diminishing privacy concerns, mitigating potential attacks, and reducing the overhead of communication, one-shot federated learning (i.e., limiting client-server communication into a single round) has gained popularity among researchers. However, the one-shot aggregation performances are sensitively affected by the non-identical training data distribution, which exhibits high statistical heterogeneity in some real-world scenarios. To address this issue, we propose a novel one-shot aggregation method with Layer-wise Posterior Aggregation, named FedLPA. FedLPA aggregates local models to obtain a more accurate global model without requiring extra auxiliary datasets or exposing any confidential local information, e.g., label distributions. To effectively capture the statistics maintained in the biased local datasets in the practical non-IID scenario, we efficiently infer the posteriors of each layer in each local model using layer-wise Laplace approximation and aggregate them to train the global parameters. Extensive experimental results demonstrate that FedLPA significantly improves learning performance over state-of-the-art methods across several metrics.