 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNL2Repo-Bench: Towards Long-Horizon Repository Generation Evaluation of Coding Agents
Dec 14, 2025Recent advances in coding agents suggest rapid progress toward autonomous software development, yet existing benchmarks fail to rigorously evaluate the long-horizon capabilities required to build complete software systems. Most prior evaluations focus on localized code generation, scaffolded completion, or short-term repair tasks, leaving open the question of whether agents can sustain coherent reasoning, planning, and execution over the extended horizons demanded by real-world repository construction. To address this gap, we present NL2Repo Bench, a benchmark explicitly designed to evaluate the long-horizon repository generation ability of coding agents. Given only a single natural-language requirements document and an empty workspace, agents must autonomously design the architecture, manage dependencies, implement multi-module logic, and produce a fully installable Python library. Our experiments across state-of-the-art open- and closed-source models reveal that long-horizon repository generation remains largely unsolved: even the strongest agents achieve below 40% average test pass rates and rarely complete an entire repository correctly. Detailed analysis uncovers fundamental long-horizon failure modes, including premature termination, loss of global coherence, fragile cross-file dependencies, and inadequate planning over hundreds of interaction steps. NL2Repo Bench establishes a rigorous, verifiable testbed for measuring sustained agentic competence and highlights long-horizon reasoning as a central bottleneck for the next generation of autonomous coding agents.
Source Coverage and Citation Bias in LLM-based vs. Traditional Search Engines
Dec 10, 2025LLM-based Search Engines (LLM-SEs) introduces a new paradigm for information seeking. Unlike Traditional Search Engines (TSEs) (e.g., Google), these systems summarize results, often providing limited citation transparency. The implications of this shift remain largely unexplored, yet raises key questions regarding trust and transparency. In this paper, we present a large-scale empirical study of LLM-SEs, analyzing 55,936 queries and the corresponding search results across six LLM-SEs and two TSEs. We confirm that LLM-SEs cites domain resources with greater diversity than TSEs. Indeed, 37% of domains are unique to LLM-SEs. However, certain risks still persist: LLM-SEs do not outperform TSEs in credibility, political neutrality and safety metrics. Finally, to understand the selection criteria of LLM-SEs, we perform a feature-based analysis to identify key factors influencing source choice. Our findings provide actionable insights for end users, website owners, and developers.
GRPO Privacy Is at Risk: A Membership Inference Attack Against Reinforcement Learning With Verifiable Rewards
Nov 18, 2025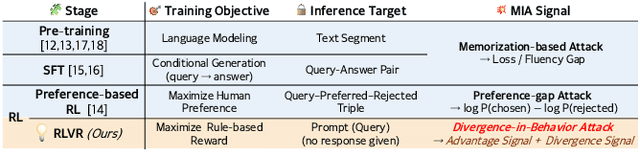
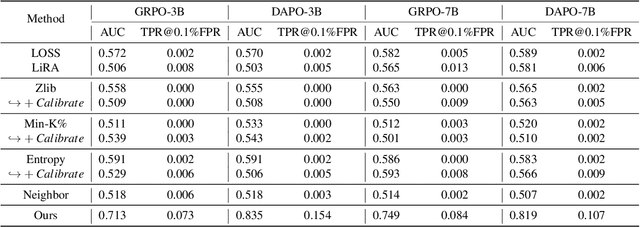
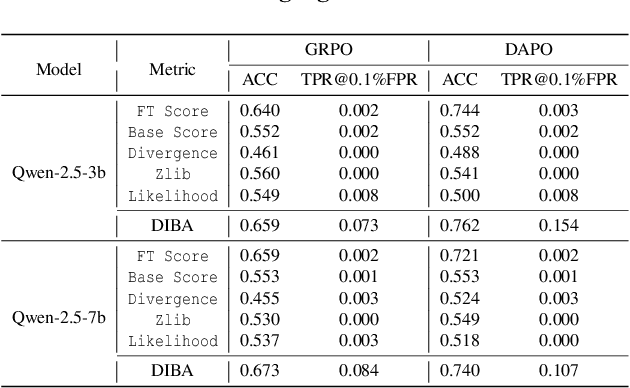
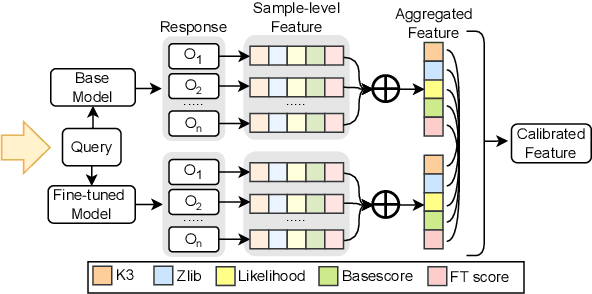
Membership inference attacks (MIAs) on large language models (LLMs) pose significant privacy risks across various stages of model training. Recent advances in Reinforcement Learning with Verifiable Rewards (RLVR) have brought a profound paradigm shift in LLM training, particularly for complex reasoning tasks. However, the on-policy nature of RLVR introduces a unique privacy leakage pattern: since training relies on self-generated responses without fixed ground-truth outputs, membership inference must now determine whether a given prompt (independent of any specific response) is used during fine-tuning. This creates a threat where leakage arises not from answer memorization. To audit this novel privacy risk, we propose Divergence-in-Behavior Attack (DIBA), the first membership inference framework specifically designed for RLVR. DIBA shifts the focus from memorization to behavioral change, leveraging measurable shifts in model behavior across two axes: advantage-side improvement (e.g., correctness gain) and logit-side divergence (e.g., policy drift). Through comprehensive evaluations, we demonstrate that DIBA significantly outperforms existing baselines, achieving around 0.8 AUC and an order-of-magnitude higher TPR@0.1%FPR. We validate DIBA's superiority across multiple settings--including in-distribution, cross-dataset, cross-algorithm, black-box scenarios, and extensions to vision-language models. Furthermore, our attack remains robust under moderate defensive measures. To the best of our knowledge, this is the first work to systematically analyze privacy vulnerabilities in RLVR, revealing that even in the absence of explicit supervision, training data exposure can be reliably inferred through behavioral traces.
ZPD-SCA: Unveiling the Blind Spots of LLMs in Assessing Students' Cognitive Abilities
Aug 20, 2025


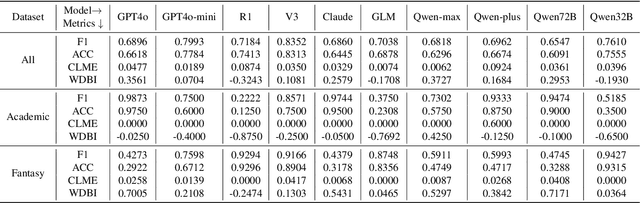
Large language models (LLMs) have demonstrated potential in educational applications, yet their capacity to accurately assess the cognitive alignment of reading materials with students' developmental stages remains insufficiently explored. This gap is particularly critical given the foundational educational principle of the Zone of Proximal Development (ZPD), which emphasizes the need to match learning resources with Students' Cognitive Abilities (SCA). Despite the importance of this alignment, there is a notable absence of comprehensive studies investigating LLMs' ability to evaluate reading comprehension difficulty across different student age groups, especially in the context of Chinese language education. To fill this gap, we introduce ZPD-SCA, a novel benchmark specifically designed to assess stage-level Chinese reading comprehension difficulty. The benchmark is annotated by 60 Special Grade teachers, a group that represents the top 0.15% of all in-service teachers nationwide. Experimental results reveal that LLMs perform poorly in zero-shot learning scenarios, with Qwen-max and GLM even falling below the probability of random guessing. When provided with in-context examples, LLMs performance improves substantially, with some models achieving nearly double the accuracy of their zero-shot baselines. These results reveal that LLMs possess emerging abilities to assess reading difficulty, while also exposing limitations in their current training for educationally aligned judgment. Notably, even the best-performing models display systematic directional biases, suggesting difficulties in accurately aligning material difficulty with SCA. Furthermore, significant variations in model performance across different genres underscore the complexity of task. We envision that ZPD-SCA can provide a foundation for evaluating and improving LLMs in cognitively aligned educational applications.
JALMBench: Benchmarking Jailbreak Vulnerabilities in Audio Language Models
May 23, 2025


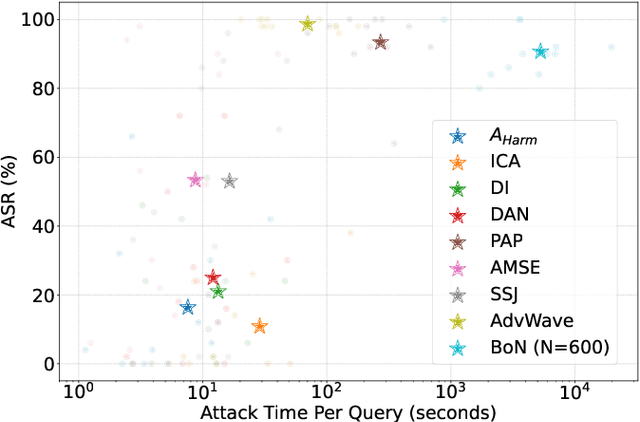
Audio Language Models (ALMs) have made significant progress recently. These models integrate the audio modality directly into the model, rather than converting speech into text and inputting text to Large Language Models (LLMs). While jailbreak attacks on LLMs have been extensively studied, the security of ALMs with audio modalities remains largely unexplored. Currently, there is a lack of an adversarial audio dataset and a unified framework specifically designed to evaluate and compare attacks and ALMs. In this paper, we present JALMBench, the \textit{first} comprehensive benchmark to assess the safety of ALMs against jailbreak attacks. JALMBench includes a dataset containing 2,200 text samples and 51,381 audio samples with over 268 hours. It supports 12 mainstream ALMs, 4 text-transferred and 4 audio-originated attack methods, and 5 defense methods. Using JALMBench, we provide an in-depth analysis of attack efficiency, topic sensitivity, voice diversity, and attack representations. Additionally, we explore mitigation strategies for the attacks at both the prompt level and the response level.
"I Can See Forever!": Evaluating Real-time VideoLLMs for Assisting Individuals with Visual Impairments
May 07, 2025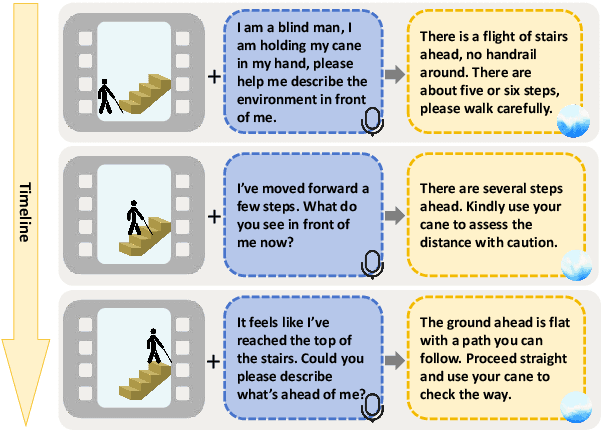
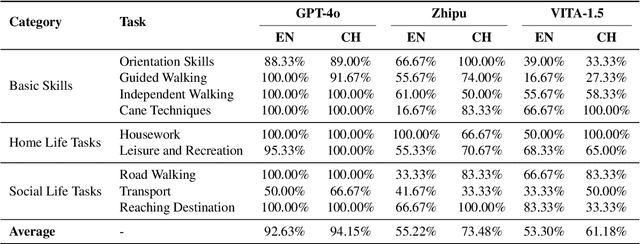
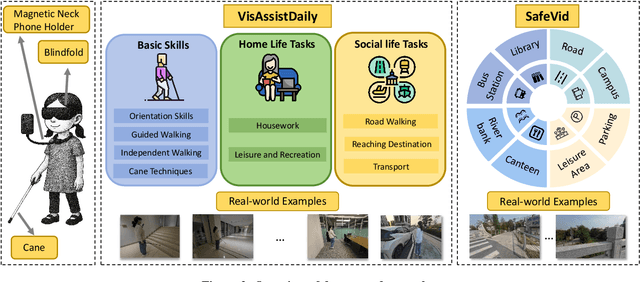
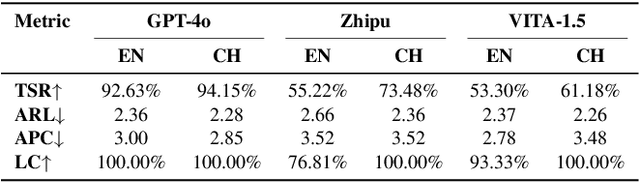
The visually impaired population, especially the severely visually impaired, is currently large in scale, and daily activities pose significant challenges for them. Although many studies use large language and vision-language models to assist the blind, most focus on static content and fail to meet real-time perception needs in dynamic and complex environments, such as daily activities. To provide them with more effective intelligent assistance, it is imperative to incorporate advanced visual understanding technologies. Although real-time vision and speech interaction VideoLLMs demonstrate strong real-time visual understanding, no prior work has systematically evaluated their effectiveness in assisting visually impaired individuals. In this work, we conduct the first such evaluation. First, we construct a benchmark dataset (VisAssistDaily), covering three categories of assistive tasks for visually impaired individuals: Basic Skills, Home Life Tasks, and Social Life Tasks. The results show that GPT-4o achieves the highest task success rate. Next, we conduct a user study to evaluate the models in both closed-world and open-world scenarios, further exploring the practical challenges of applying VideoLLMs in assistive contexts. One key issue we identify is the difficulty current models face in perceiving potential hazards in dynamic environments. To address this, we build an environment-awareness dataset named SafeVid and introduce a polling mechanism that enables the model to proactively detect environmental risks. We hope this work provides valuable insights and inspiration for future research in this field.
Humanizing LLMs: A Survey of Psychological Measurements with Tools, Datasets, and Human-Agent Applications
Apr 30, 2025



As large language models (LLMs) are increasingly used in human-centered tasks, assessing their psychological traits is crucial for understanding their social impact and ensuring trustworthy AI alignment. While existing reviews have covered some aspects of related research, several important areas have not been systematically discussed, including detailed discussions of diverse psychological tests, LLM-specific psychological datasets, and the applications of LLMs with psychological traits. To address this gap, we systematically review six key dimensions of applying psychological theories to LLMs: (1) assessment tools; (2) LLM-specific datasets; (3) evaluation metrics (consistency and stability); (4) empirical findings; (5) personality simulation methods; and (6) LLM-based behavior simulation. Our analysis highlights both the strengths and limitations of current methods. While some LLMs exhibit reproducible personality patterns under specific prompting schemes, significant variability remains across tasks and settings. Recognizing methodological challenges such as mismatches between psychological tools and LLMs' capabilities, as well as inconsistencies in evaluation practices, this study aims to propose future directions for developing more interpretable, robust, and generalizable psychological assessment frameworks for LLMs.
Thought Manipulation: External Thought Can Be Efficient for Large Reasoning Models
Apr 18, 2025Recent advancements in large reasoning models (LRMs) have demonstrated the effectiveness of scaling test-time computation to enhance reasoning capabilities in multiple tasks. However, LRMs typically suffer from "overthinking" problems, where models generate significantly redundant reasoning steps while bringing limited performance gains. Existing work relies on fine-tuning to mitigate overthinking, which requires additional data, unconventional training setups, risky safety misalignment, and poor generalization. Through empirical analysis, we reveal an important characteristic of LRM behaviors that placing external CoTs generated by smaller models between the thinking token ($\texttt{<think>}$ and $\texttt{</think>)}$ can effectively manipulate the model to generate fewer thoughts. Building on these insights, we propose a simple yet efficient pipeline, ThoughtMani, to enable LRMs to bypass unnecessary intermediate steps and reduce computational costs significantly. We conduct extensive experiments to validate the utility and efficiency of ThoughtMani. For instance, when applied to QwQ-32B on the LiveBench/Code dataset, ThoughtMani keeps the original performance and reduces output token counts by approximately 30%, with little overhead from the CoT generator. Furthermore, we find that ThoughtMani enhances safety alignment by an average of 10%. Since model vendors typically serve models of different sizes simultaneously, ThoughtMani provides an effective way to construct more efficient and accessible LRMs for real-world applications.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
Automatic Pruning via Structured Lasso with Class-wise Information
Feb 13, 2025Most pruning methods concentrate on unimportant filters of neural networks. However, they face the loss of statistical information due to a lack of consideration for class-wise data. In this paper, from the perspective of leveraging precise class-wise information for model pruning, we utilize structured lasso with guidance from Information Bottleneck theory. Our approach ensures that statistical information is retained during the pruning process. With these techniques, we introduce two innovative adaptive network pruning schemes: sparse graph-structured lasso pruning with Information Bottleneck (\textbf{sGLP-IB}) and sparse tree-guided lasso pruning with Information Bottleneck (\textbf{sTLP-IB}). The key aspect is pruning model filters using sGLP-IB and sTLP-IB to better capture class-wise relatedness. Compared to multiple state-of-the-art methods, our approaches demonstrate superior performance across three datasets and six model architectures in extensive experiments. For instance, using the VGG16 model on the CIFAR-10 dataset, we achieve a parameter reduction of 85%, a decrease in FLOPs by 61%, and maintain an accuracy of 94.10% (0.14% higher than the original model); we reduce the parameters by 55% with the accuracy at 76.12% using the ResNet architecture on ImageNet (only drops 0.03%). In summary, we successfully reduce model size and computational resource usage while maintaining accuracy. Our codes are at https://anonymous.4open.science/r/IJCAI-8104.