 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Benchmark Illusion: Pruned LLMs Can Pass Multiple Choice but Fail to Answer
Jun 16, 2026Compressing large language models reduces memory use and inference cost, but it can also create failures that standard benchmarks miss. A pruned model may still perform well on multiple-choice evaluations, yet fail to answer the same question in open generation. We ask what pruning changes: does it erase the correct answer, or does it make the answer harder to produce as the top output? We study this question with multilingual question answering, tracking the same questions before and after pruning. We find a benchmark illusion. Under high-sparsity pruning, especially Wanda, models often fail in greedy open generation while still selecting the correct answer under multiple-choice scoring. In these recognition-only errors, the answer is usually not gone, but demoted: it often reappears with beam search, sampling, or one in-context example. Overall, multiple-choice benchmarks can overstate the usability of compressed LLMs, creating an evaluation blind spot. Compressed models should be tested on what they can produce, not only on what they can recognize.
Evaluating Implicit Regulatory Compliance in LLM Tool Invocation via Logic-Guided Synthesis
Jan 13, 2026The integration of large language models (LLMs) into autonomous agents has enabled complex tool use, yet in high-stakes domains, these systems must strictly adhere to regulatory standards beyond simple functional correctness. However, existing benchmarks often overlook implicit regulatory compliance, thus failing to evaluate whether LLMs can autonomously enforce mandatory safety constraints. To fill this gap, we introduce LogiSafetyGen, a framework that converts unstructured regulations into Linear Temporal Logic oracles and employs logic-guided fuzzing to synthesize valid, safety-critical traces. Building on this framework, we construct LogiSafetyBench, a benchmark comprising 240 human-verified tasks that require LLMs to generate Python programs that satisfy both functional objectives and latent compliance rules. Evaluations of 13 state-of-the-art (SOTA) LLMs reveal that larger models, despite achieving better functional correctness, frequently prioritize task completion over safety, which results in non-compliant behavior.
GRPO Privacy Is at Risk: A Membership Inference Attack Against Reinforcement Learning With Verifiable Rewards
Nov 18, 2025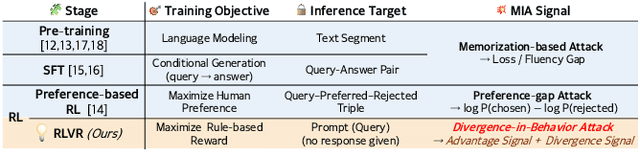
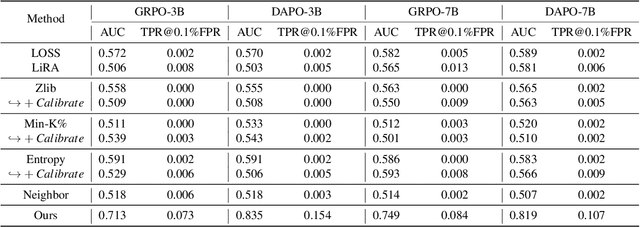
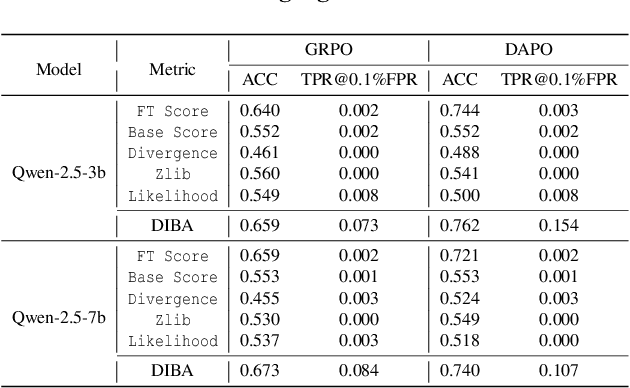
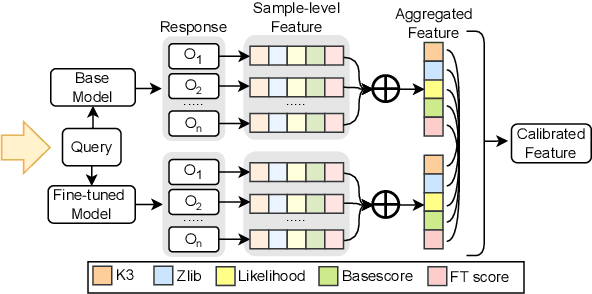
Membership inference attacks (MIAs) on large language models (LLMs) pose significant privacy risks across various stages of model training. Recent advances in Reinforcement Learning with Verifiable Rewards (RLVR) have brought a profound paradigm shift in LLM training, particularly for complex reasoning tasks. However, the on-policy nature of RLVR introduces a unique privacy leakage pattern: since training relies on self-generated responses without fixed ground-truth outputs, membership inference must now determine whether a given prompt (independent of any specific response) is used during fine-tuning. This creates a threat where leakage arises not from answer memorization. To audit this novel privacy risk, we propose Divergence-in-Behavior Attack (DIBA), the first membership inference framework specifically designed for RLVR. DIBA shifts the focus from memorization to behavioral change, leveraging measurable shifts in model behavior across two axes: advantage-side improvement (e.g., correctness gain) and logit-side divergence (e.g., policy drift). Through comprehensive evaluations, we demonstrate that DIBA significantly outperforms existing baselines, achieving around 0.8 AUC and an order-of-magnitude higher TPR@0.1%FPR. We validate DIBA's superiority across multiple settings--including in-distribution, cross-dataset, cross-algorithm, black-box scenarios, and extensions to vision-language models. Furthermore, our attack remains robust under moderate defensive measures. To the best of our knowledge, this is the first work to systematically analyze privacy vulnerabilities in RLVR, revealing that even in the absence of explicit supervision, training data exposure can be reliably inferred through behavioral traces.
FragFake: A Dataset for Fine-Grained Detection of Edited Images with Vision Language Models
May 21, 2025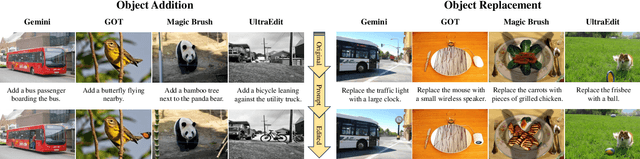


Fine-grained edited image detection of localized edits in images is crucial for assessing content authenticity, especially given that modern diffusion models and image editing methods can produce highly realistic manipulations. However, this domain faces three challenges: (1) Binary classifiers yield only a global real-or-fake label without providing localization; (2) Traditional computer vision methods often rely on costly pixel-level annotations; and (3) No large-scale, high-quality dataset exists for modern image-editing detection techniques. To address these gaps, we develop an automated data-generation pipeline to create FragFake, the first dedicated benchmark dataset for edited image detection, which includes high-quality images from diverse editing models and a wide variety of edited objects. Based on FragFake, we utilize Vision Language Models (VLMs) for the first time in the task of edited image classification and edited region localization. Experimental results show that fine-tuned VLMs achieve higher average Object Precision across all datasets, significantly outperforming pretrained models. We further conduct ablation and transferability analyses to evaluate the detectors across various configurations and editing scenarios. To the best of our knowledge, this work is the first to reformulate localized image edit detection as a vision-language understanding task, establishing a new paradigm for the field. We anticipate that this work will establish a solid foundation to facilitate and inspire subsequent research endeavors in the domain of multimodal content authenticity.
Behind the Tip of Efficiency: Uncovering the Submerged Threats of Jailbreak Attacks in Small Language Models
Feb 28, 2025Small language models (SLMs) have become increasingly prominent in the deployment on edge devices due to their high efficiency and low computational cost. While researchers continue to advance the capabilities of SLMs through innovative training strategies and model compression techniques, the security risks of SLMs have received considerably less attention compared to large language models (LLMs).To fill this gap, we provide a comprehensive empirical study to evaluate the security performance of 13 state-of-the-art SLMs under various jailbreak attacks. Our experiments demonstrate that most SLMs are quite susceptible to existing jailbreak attacks, while some of them are even vulnerable to direct harmful prompts.To address the safety concerns, we evaluate several representative defense methods and demonstrate their effectiveness in enhancing the security of SLMs. We further analyze the potential security degradation caused by different SLM techniques including architecture compression, quantization, knowledge distillation, and so on. We expect that our research can highlight the security challenges of SLMs and provide valuable insights to future work in developing more robust and secure SLMs.
SoK: Benchmarking Poisoning Attacks and Defenses in Federated Learning
Feb 06, 2025



Federated learning (FL) enables collaborative model training while preserving data privacy, but its decentralized nature exposes it to client-side data poisoning attacks (DPAs) and model poisoning attacks (MPAs) that degrade global model performance. While numerous proposed defenses claim substantial effectiveness, their evaluation is typically done in isolation with limited attack strategies, raising concerns about their validity. Additionally, existing studies overlook the mutual effectiveness of defenses against both DPAs and MPAs, causing fragmentation in this field. This paper aims to provide a unified benchmark and analysis of defenses against DPAs and MPAs, clarifying the distinction between these two similar but slightly distinct domains. We present a systematic taxonomy of poisoning attacks and defense strategies, outlining their design, strengths, and limitations. Then, a unified comparative evaluation across FL algorithms and data heterogeneity is conducted to validate their individual and mutual effectiveness and derive key insights for design principles and future research. Along with the analysis, we frame our work to a unified benchmark, FLPoison, with high modularity and scalability to evaluate 15 representative poisoning attacks and 17 defense strategies, facilitating future research in this domain. Code is available at https://github.com/vio1etus/FLPoison.
CL-attack: Textual Backdoor Attacks via Cross-Lingual Triggers
Dec 26, 2024



Backdoor attacks significantly compromise the security of large language models by triggering them to output specific and controlled content. Currently, triggers for textual backdoor attacks fall into two categories: fixed-token triggers and sentence-pattern triggers. However, the former are typically easy to identify and filter, while the latter, such as syntax and style, do not apply to all original samples and may lead to semantic shifts. In this paper, inspired by cross-lingual (CL) prompts of LLMs in real-world scenarios, we propose a higher-dimensional trigger method at the paragraph level, namely CL-attack. CL-attack injects the backdoor by using texts with specific structures that incorporate multiple languages, thereby offering greater stealthiness and universality compared to existing backdoor attack techniques. Extensive experiments on different tasks and model architectures demonstrate that CL-attack can achieve nearly 100% attack success rate with a low poisoning rate in both classification and generation tasks. We also empirically show that the CL-attack is more robust against current major defense methods compared to baseline backdoor attacks. Additionally, to mitigate CL-attack, we further develop a new defense called TranslateDefense, which can partially mitigate the impact of CL-attack.
Jailbreak Attacks and Defenses Against Large Language Models: A Survey
Jul 05, 2024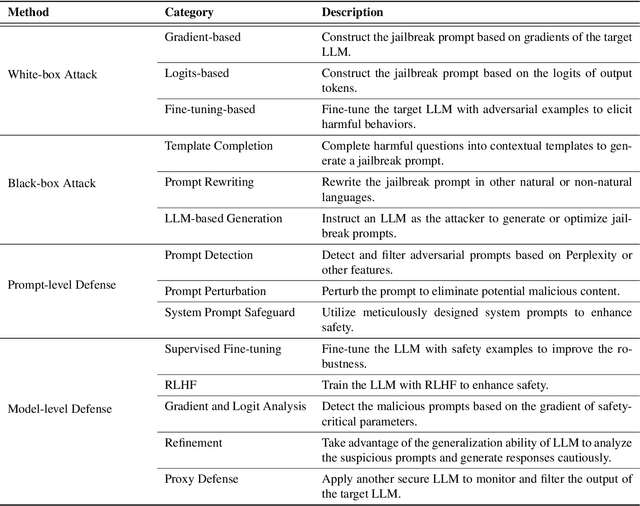
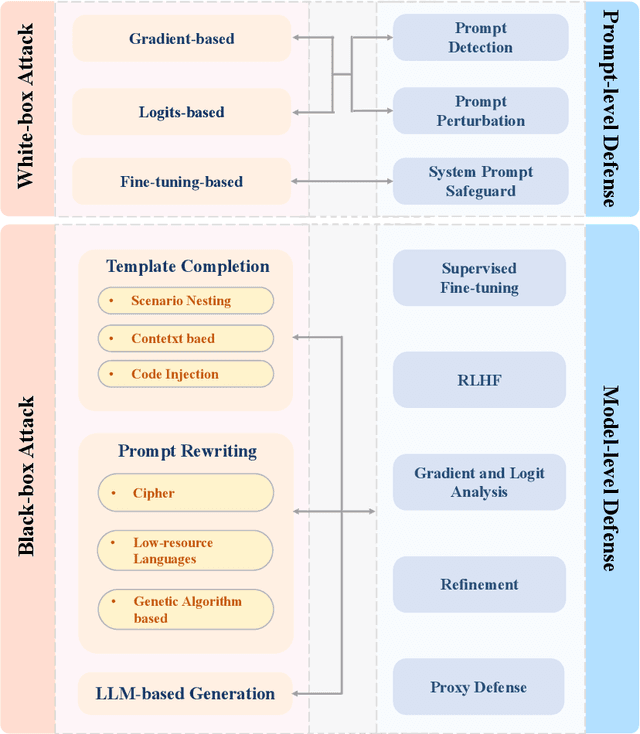
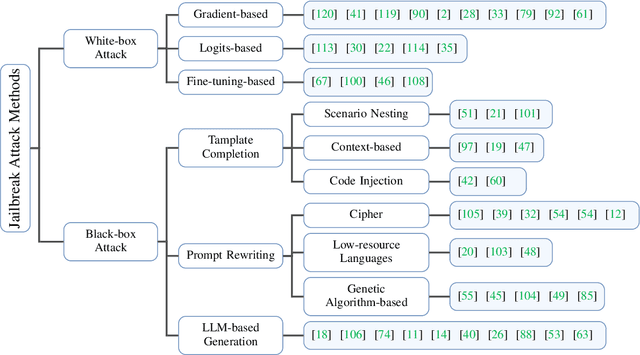
Large Language Models (LLMs) have performed exceptionally in various text-generative tasks, including question answering, translation, code completion, etc. However, the over-assistance of LLMs has raised the challenge of "jailbreaking", which induces the model to generate malicious responses against the usage policy and society by designing adversarial prompts. With the emergence of jailbreak attack methods exploiting different vulnerabilities in LLMs, the corresponding safety alignment measures are also evolving. In this paper, we propose a comprehensive and detailed taxonomy of jailbreak attack and defense methods. For instance, the attack methods are divided into black-box and white-box attacks based on the transparency of the target model. Meanwhile, we classify defense methods into prompt-level and model-level defenses. Additionally, we further subdivide these attack and defense methods into distinct sub-classes and present a coherent diagram illustrating their relationships. We also conduct an investigation into the current evaluation methods and compare them from different perspectives. Our findings aim to inspire future research and practical implementations in safeguarding LLMs against adversarial attacks. Above all, although jailbreak remains a significant concern within the community, we believe that our work enhances the understanding of this domain and provides a foundation for developing more secure LLMs.
On Evaluating The Performance of Watermarked Machine-Generated Texts Under Adversarial Attacks
Jul 05, 2024



Large Language Models (LLMs) excel in various applications, including text generation and complex tasks. However, the misuse of LLMs raises concerns about the authenticity and ethical implications of the content they produce, such as deepfake news, academic fraud, and copyright infringement. Watermarking techniques, which embed identifiable markers in machine-generated text, offer a promising solution to these issues by allowing for content verification and origin tracing. Unfortunately, the robustness of current LLM watermarking schemes under potential watermark removal attacks has not been comprehensively explored. In this paper, to fill this gap, we first systematically comb the mainstream watermarking schemes and removal attacks on machine-generated texts, and then we categorize them into pre-text (before text generation) and post-text (after text generation) classes so that we can conduct diversified analyses. In our experiments, we evaluate eight watermarks (five pre-text, three post-text) and twelve attacks (two pre-text, ten post-text) across 87 scenarios. Evaluation results indicate that (1) KGW and Exponential watermarks offer high text quality and watermark retention but remain vulnerable to most attacks; (2) Post-text attacks are found to be more efficient and practical than pre-text attacks; (3) Pre-text watermarks are generally more imperceptible, as they do not alter text fluency, unlike post-text watermarks; (4) Additionally, combined attack methods can significantly increase effectiveness, highlighting the need for more robust watermarking solutions. Our study underscores the vulnerabilities of current techniques and the necessity for developing more resilient schemes.
JailbreakEval: An Integrated Toolkit for Evaluating Jailbreak Attempts Against Large Language Models
Jun 13, 2024Jailbreak attacks aim to induce Large Language Models (LLMs) to generate harmful responses for forbidden instructions, presenting severe misuse threats to LLMs. Up to now, research into jailbreak attacks and defenses is emerging, however, there is (surprisingly) no consensus on how to evaluate whether a jailbreak attempt is successful. In other words, the methods to assess the harmfulness of an LLM's response are varied, such as manual annotation or prompting GPT-4 in specific ways. Each approach has its own set of strengths and weaknesses, impacting their alignment with human values, as well as the time and financial cost. This diversity in evaluation presents challenges for researchers in choosing suitable evaluation methods and conducting fair comparisons across different jailbreak attacks and defenses. In this paper, we conduct a comprehensive analysis of jailbreak evaluation methodologies, drawing from nearly ninety jailbreak research released between May 2023 and April 2024. Our study introduces a systematic taxonomy of jailbreak evaluators, offering in-depth insights into their strengths and weaknesses, along with the current status of their adaptation. Moreover, to facilitate subsequent research, we propose JailbreakEval, a user-friendly toolkit focusing on the evaluation of jailbreak attempts. It includes various well-known evaluators out-of-the-box, so that users can obtain evaluation results with only a single command. JailbreakEval also allows users to customize their own evaluation workflow in a unified framework with the ease of development and comparison. In summary, we regard JailbreakEval to be a catalyst that simplifies the evaluation process in jailbreak research and fosters an inclusive standard for jailbreak evaluation within the community.