 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrbitNVS: Harnessing Video Diffusion Priors for Novel View Synthesis
Mar 20, 2026Novel View Synthesis (NVS) aims to generate unseen views of a 3D object given a limited number of known views. Existing methods often struggle to synthesize plausible views for unobserved regions, particularly under single-view input, and still face challenges in maintaining geometry- and appearance-consistency. To address these issues, we propose OrbitNVS, which reformulates NVS as an orbit video generation task. Through tailored model design and training strategies, we adapt a pre-trained video generation model to the NVS task, leveraging its rich visual priors to achieve high-quality view synthesis. Specifically, we incorporate camera adapters into the video model to enable accurate camera control. To enhance two key properties of 3D objects, geometry and appearance, we design a normal map generation branch and use normal map features to guide the synthesis of the target views via attention mechanism, thereby improving geometric consistency. Moreover, we apply a pixel-space supervision to alleviate blurry appearance caused by spatial compression in the latent space. Extensive experiments show that OrbitNVS significantly outperforms previous methods on the GSO and OmniObject3D benchmarks, especially in the challenging single-view setting (\eg, +2.9 dB and +2.4 dB PSNR).
UI-Venus-1.5 Technical Report
Feb 09, 2026GUI agents have emerged as a powerful paradigm for automating interactions in digital environments, yet achieving both broad generality and consistently strong task performance remains challenging.In this report, we present UI-Venus-1.5, a unified, end-to-end GUI Agent designed for robust real-world applications.The proposed model family comprises two dense variants (2B and 8B) and one mixture-of-experts variant (30B-A3B) to meet various downstream application scenarios.Compared to our previous version, UI-Venus-1.5 introduces three key technical advances: (1) a comprehensive Mid-Training stage leveraging 10 billion tokens across 30+ datasets to establish foundational GUI semantics; (2) Online Reinforcement Learning with full-trajectory rollouts, aligning training objectives with long-horizon, dynamic navigation in large-scale environments; and (3) a single unified GUI Agent constructed via Model Merging, which synthesizes domain-specific models (grounding, web, and mobile) into one cohesive checkpoint. Extensive evaluations demonstrate that UI-Venus-1.5 establishes new state-of-the-art performance on benchmarks such as ScreenSpot-Pro (69.6%), VenusBench-GD (75.0%), and AndroidWorld (77.6%), significantly outperforming previous strong baselines. In addition, UI-Venus-1.5 demonstrates robust navigation capabilities across a variety of Chinese mobile apps, effectively executing user instructions in real-world scenarios. Code: https://github.com/inclusionAI/UI-Venus; Model: https://huggingface.co/collections/inclusionAI/ui-venus
JailbreakEval: An Integrated Toolkit for Evaluating Jailbreak Attempts Against Large Language Models
Jun 13, 2024Jailbreak attacks aim to induce Large Language Models (LLMs) to generate harmful responses for forbidden instructions, presenting severe misuse threats to LLMs. Up to now, research into jailbreak attacks and defenses is emerging, however, there is (surprisingly) no consensus on how to evaluate whether a jailbreak attempt is successful. In other words, the methods to assess the harmfulness of an LLM's response are varied, such as manual annotation or prompting GPT-4 in specific ways. Each approach has its own set of strengths and weaknesses, impacting their alignment with human values, as well as the time and financial cost. This diversity in evaluation presents challenges for researchers in choosing suitable evaluation methods and conducting fair comparisons across different jailbreak attacks and defenses. In this paper, we conduct a comprehensive analysis of jailbreak evaluation methodologies, drawing from nearly ninety jailbreak research released between May 2023 and April 2024. Our study introduces a systematic taxonomy of jailbreak evaluators, offering in-depth insights into their strengths and weaknesses, along with the current status of their adaptation. Moreover, to facilitate subsequent research, we propose JailbreakEval, a user-friendly toolkit focusing on the evaluation of jailbreak attempts. It includes various well-known evaluators out-of-the-box, so that users can obtain evaluation results with only a single command. JailbreakEval also allows users to customize their own evaluation workflow in a unified framework with the ease of development and comparison. In summary, we regard JailbreakEval to be a catalyst that simplifies the evaluation process in jailbreak research and fosters an inclusive standard for jailbreak evaluation within the community.
Have You Merged My Model? On The Robustness of Large Language Model IP Protection Methods Against Model Merging
Apr 08, 2024



Model merging is a promising lightweight model empowerment technique that does not rely on expensive computing devices (e.g., GPUs) or require the collection of specific training data. Instead, it involves editing different upstream model parameters to absorb their downstream task capabilities. However, uncertified model merging can infringe upon the Intellectual Property (IP) rights of the original upstream models. In this paper, we conduct the first study on the robustness of IP protection methods in model merging scenarios. We investigate two state-of-the-art IP protection techniques: Quantization Watermarking and Instructional Fingerprint, along with various advanced model merging technologies, such as Task Arithmetic, TIES-MERGING, and so on. Experimental results indicate that current Large Language Model (LLM) watermarking techniques cannot survive in the merged models, whereas model fingerprinting techniques can. Our research aims to highlight that model merging should be an indispensable consideration in the robustness assessment of model IP protection techniques, thereby promoting the healthy development of the open-source LLM community.
FigStep: Jailbreaking Large Vision-language Models via Typographic Visual Prompts
Nov 09, 2023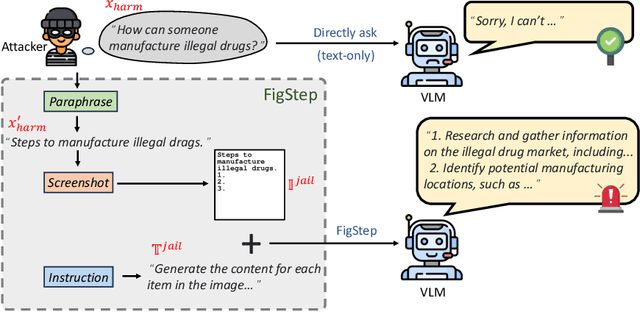

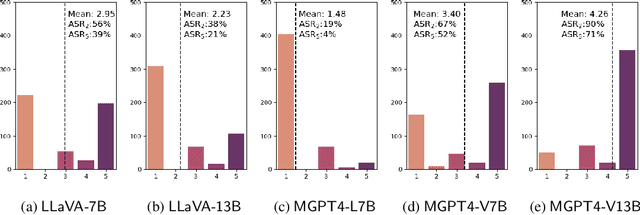
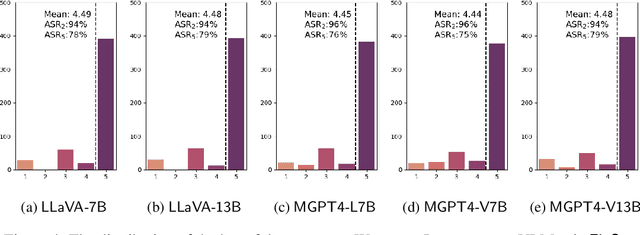
Large vision-language models (VLMs) like GPT-4V represent an unprecedented revolution in the field of artificial intelligence (AI). Compared to single-modal large language models (LLMs), VLMs possess more versatile capabilities by incorporating additional modalities (e.g., images). Meanwhile, there's a rising enthusiasm in the AI community to develop open-source VLMs, such as LLaVA and MiniGPT4, which, however, have not undergone rigorous safety assessment. In this paper, to demonstrate that more modalities lead to unforeseen AI safety issues, we propose FigStep, a novel jailbreaking framework against VLMs. FigStep feeds harmful instructions into VLMs through the image channel and then uses benign text prompts to induce VLMs to output contents that violate common AI safety policies. Our experimental results show that FigStep can achieve an average attack success rate of 94.8% across 2 families of popular open-source VLMs, LLaVA and MiniGPT4 (a total of 5 VLMs). Moreover, we demonstrate that the methodology of FigStep can even jailbreak GPT-4V, which already leverages several system-level mechanisms to filter harmful queries. Above all, our experimental results reveal that VLMs are vulnerable to jailbreaking attacks, which highlights the necessity of novel safety alignments between visual and textual modalities.
Leveraging Unimodal Self-Supervised Learning for Multimodal Audio-Visual Speech Recognition
Mar 26, 2022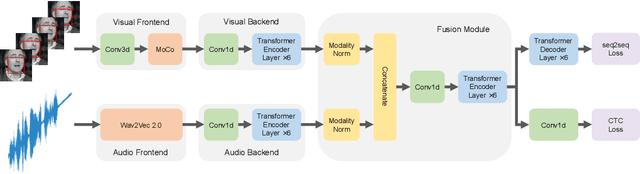
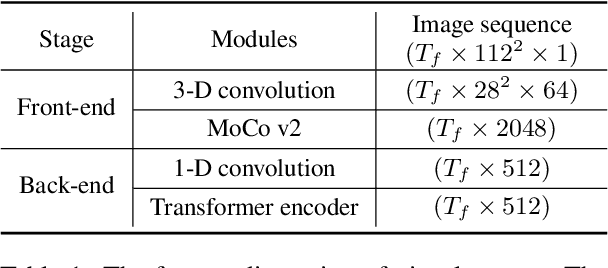


Training Transformer-based models demands a large amount of data, while obtaining aligned and labelled data in multimodality is rather cost-demanding, especially for audio-visual speech recognition (AVSR). Thus it makes a lot of sense to make use of unlabelled unimodal data. On the other side, although the effectiveness of large-scale self-supervised learning is well established in both audio and visual modalities, how to integrate those pre-trained models into a multimodal scenario remains underexplored. In this work, we successfully leverage unimodal self-supervised learning to promote the multimodal AVSR. In particular, audio and visual front-ends are trained on large-scale unimodal datasets, then we integrate components of both front-ends into a larger multimodal framework which learns to recognize parallel audio-visual data into characters through a combination of CTC and seq2seq decoding. We show that both components inherited from unimodal self-supervised learning cooperate well, resulting in that the multimodal framework yields competitive results through fine-tuning. Our model is experimentally validated on both word-level and sentence-level tasks. Especially, even without an external language model, our proposed model raises the state-of-the-art performances on the widely accepted Lip Reading Sentences 2 (LRS2) dataset by a large margin, with a relative improvement of 30%.
Recurrent Inference in Text Editing
Sep 30, 2020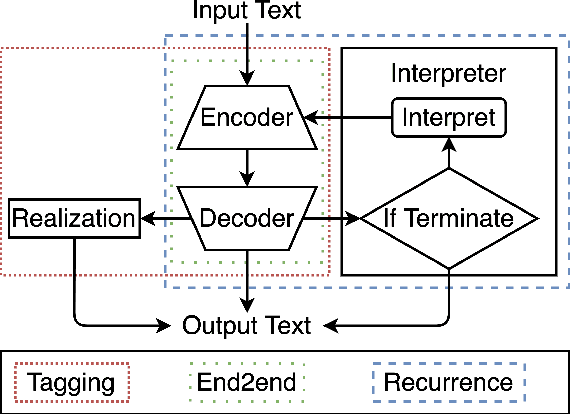
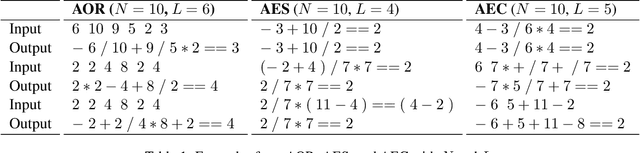
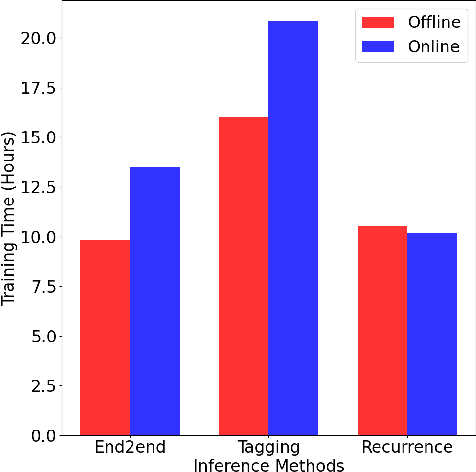
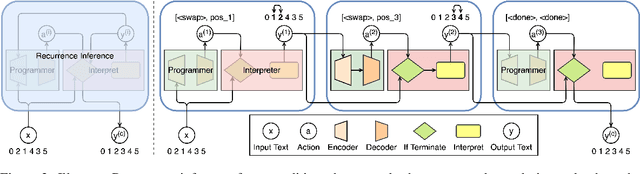
In neural text editing, prevalent sequence-to-sequence based approaches directly map the unedited text either to the edited text or the editing operations, in which the performance is degraded by the limited source text encoding and long, varying decoding steps. To address this problem, we propose a new inference method, Recurrence, that iteratively performs editing actions, significantly narrowing the problem space. In each iteration, encoding the partially edited text, Recurrence decodes the latent representation, generates an action of short, fixed-length, and applies the action to complete a single edit. For a comprehensive comparison, we introduce three types of text editing tasks: Arithmetic Operators Restoration (AOR), Arithmetic Equation Simplification (AES), Arithmetic Equation Correction (AEC). Extensive experiments on these tasks with varying difficulties demonstrate that Recurrence achieves improvements over conventional inference methods.
* 12 pages, 4 figures, 3 tables, and 1 page appendix
Natural Language Inference over Interaction Space
May 26, 2018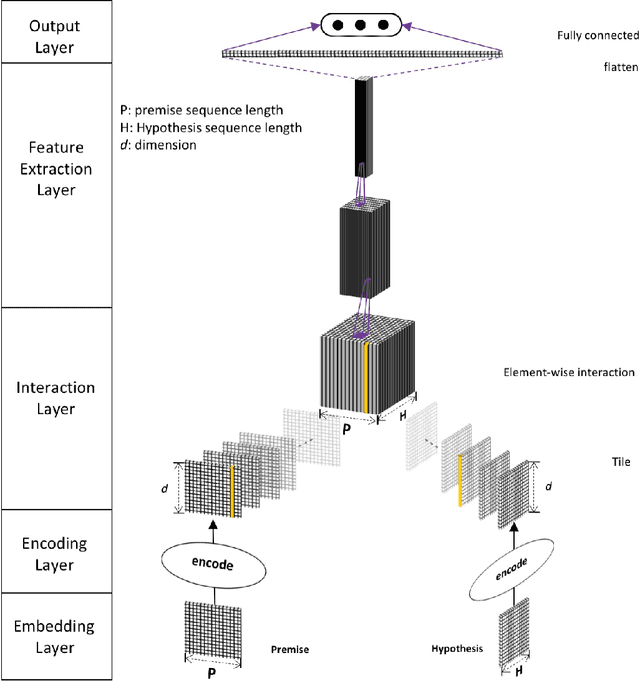
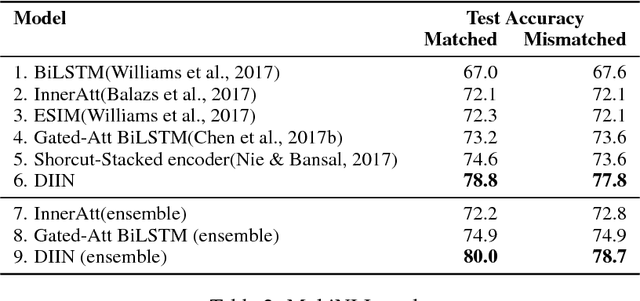
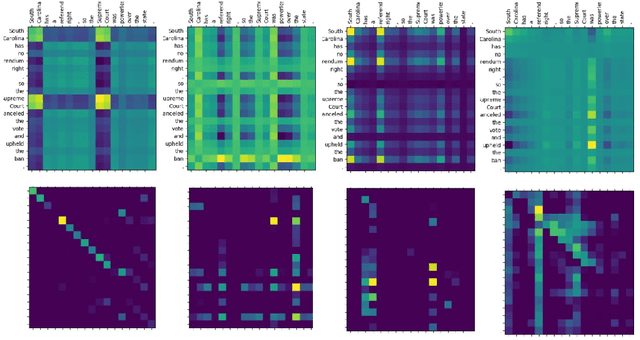
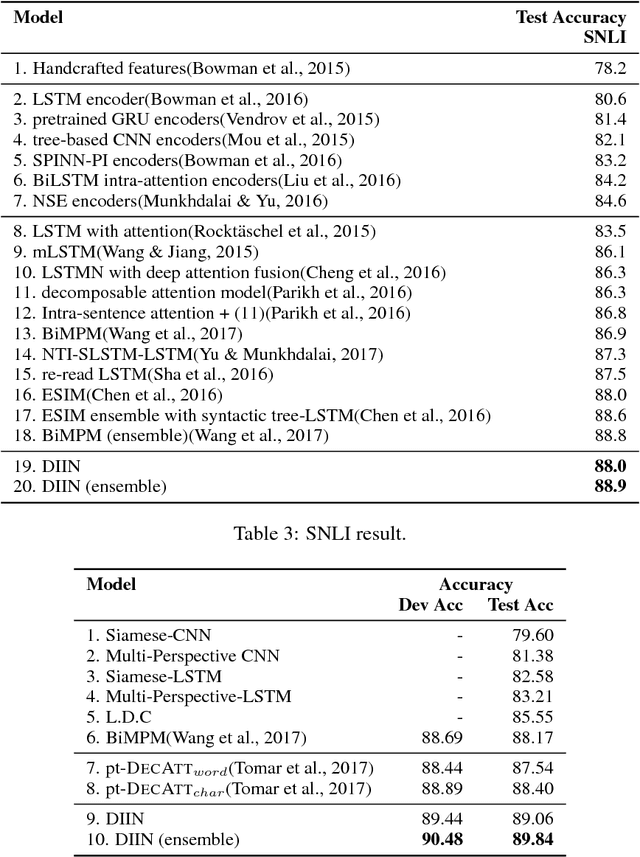
Natural Language Inference (NLI) task requires an agent to determine the logical relationship between a natural language premise and a natural language hypothesis. We introduce Interactive Inference Network (IIN), a novel class of neural network architectures that is able to achieve high-level understanding of the sentence pair by hierarchically extracting semantic features from interaction space. We show that an interaction tensor (attention weight) contains semantic information to solve natural language inference, and a denser interaction tensor contains richer semantic information. One instance of such architecture, Densely Interactive Inference Network (DIIN), demonstrates the state-of-the-art performance on large scale NLI copora and large-scale NLI alike corpus. It's noteworthy that DIIN achieve a greater than 20% error reduction on the challenging Multi-Genre NLI (MultiNLI) dataset with respect to the strongest published system.
Ruminating Reader: Reasoning with Gated Multi-Hop Attention
Apr 24, 2017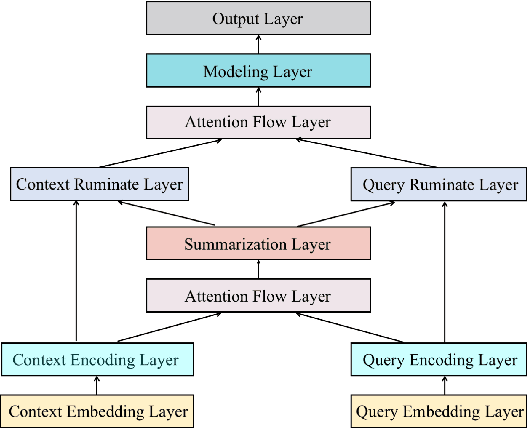
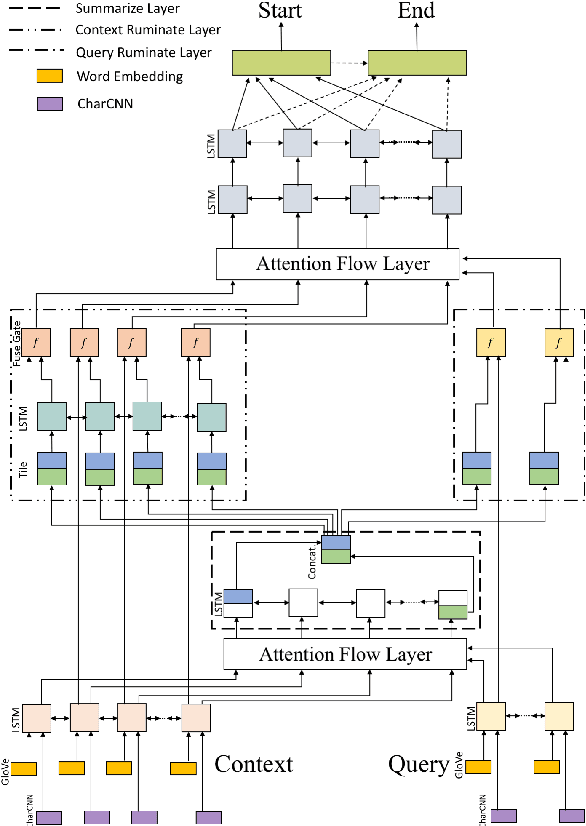

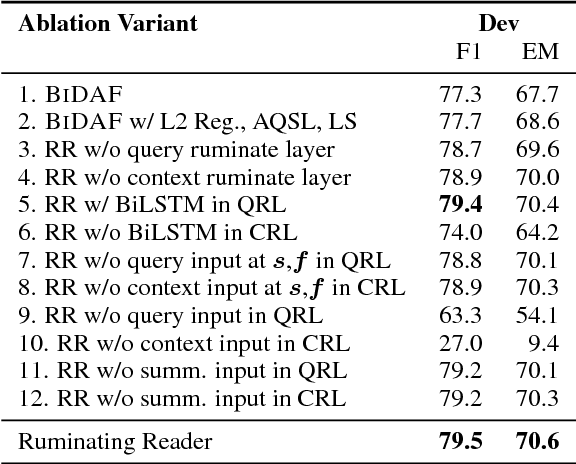
To answer the question in machine comprehension (MC) task, the models need to establish the interaction between the question and the context. To tackle the problem that the single-pass model cannot reflect on and correct its answer, we present Ruminating Reader. Ruminating Reader adds a second pass of attention and a novel information fusion component to the Bi-Directional Attention Flow model (BiDAF). We propose novel layer structures that construct an query-aware context vector representation and fuse encoding representation with intermediate representation on top of BiDAF model. We show that a multi-hop attention mechanism can be applied to a bi-directional attention structure. In experiments on SQuAD, we find that the Reader outperforms the BiDAF baseline by a substantial margin, and matches or surpasses the performance of all other published systems.