 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Gaussian Process Regression with Temporal Feature Extraction for Partially Interpretable Remaining Useful Life Interval Prediction in Aeroengine Prognostics
Nov 19, 2024The estimation of Remaining Useful Life (RUL) plays a pivotal role in intelligent manufacturing systems and Industry 4.0 technologies. While recent advancements have improved RUL prediction, many models still face interpretability and compelling uncertainty modeling challenges. This paper introduces a modified Gaussian Process Regression (GPR) model for RUL interval prediction, tailored for the complexities of manufacturing process development. The modified GPR predicts confidence intervals by learning from historical data and addresses uncertainty modeling in a more structured way. The approach effectively captures intricate time-series patterns and dynamic behaviors inherent in modern manufacturing systems by coupling GPR with deep adaptive learning-enhanced AI process models. Moreover, the model evaluates feature significance to ensure more transparent decision-making, which is crucial for optimizing manufacturing processes. This comprehensive approach supports more accurate RUL predictions and provides transparent, interpretable insights into uncertainty, contributing to robust process development and management.
Learning to Focus: Cascaded Feature Matching Network for Few-shot Image Recognition
Jan 13, 2021

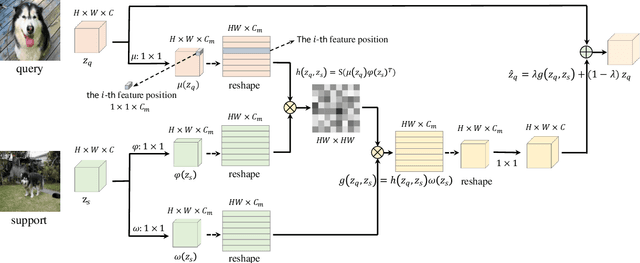

Deep networks can learn to accurately recognize objects of a category by training on a large number of annotated images. However, a meta-learning challenge known as a low-shot image recognition task comes when only a few images with annotations are available for learning a recognition model for one category. The objects in testing/query and training/support images are likely to be different in size, location, style, and so on. Our method, called Cascaded Feature Matching Network (CFMN), is proposed to solve this problem. We train the meta-learner to learn a more fine-grained and adaptive deep distance metric by focusing more on the features that have high correlations between compared images by the feature matching block which can align associated features together and naturally ignore those non-discriminative features. By applying the proposed feature matching block in different layers of the few-shot recognition network, multi-scale information among the compared images can be incorporated into the final cascaded matching feature, which boosts the recognition performance further and generalizes better by learning on relationships. The experiments for few-shot learning on two standard datasets, \emph{mini}ImageNet and Omniglot, have confirmed the effectiveness of our method. Besides, the multi-label few-shot task is first studied on a new data split of COCO which further shows the superiority of the proposed feature matching network when performing few-shot learning in complex images. The code will be made publicly available.
* 14 pages
Diversity Transfer Network for Few-Shot Learning
Dec 31, 2019

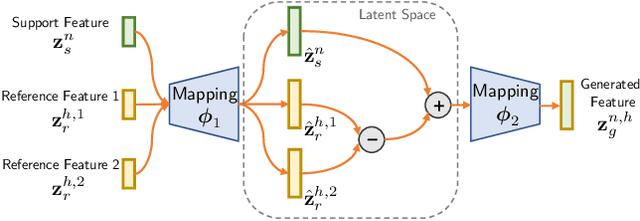
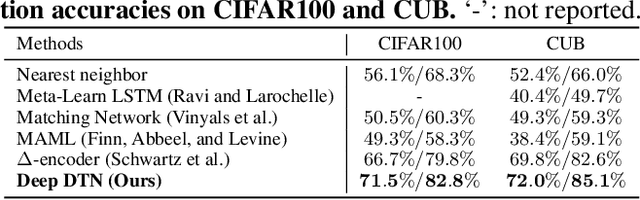
Few-shot learning is a challenging task that aims at training a classifier for unseen classes with only a few training examples. The main difficulty of few-shot learning lies in the lack of intra-class diversity within insufficient training samples. To alleviate this problem, we propose a novel generative framework, Diversity Transfer Network (DTN), that learns to transfer latent diversities from known categories and composite them with support features to generate diverse samples for novel categories in feature space. The learning problem of the sample generation (i.e., diversity transfer) is solved via minimizing an effective meta-classification loss in a single-stage network, instead of the generative loss in previous works. Besides, an organized auxiliary task co-training over known categories is proposed to stabilize the meta-training process of DTN. We perform extensive experiments and ablation studies on three datasets, i.e., \emph{mini}ImageNet, CIFAR100 and CUB. The results show that DTN, with single-stage training and faster convergence speed, obtains the state-of-the-art results among the feature generation based few-shot learning methods. Code and supplementary material are available at: \texttt{https://github.com/Yuxin-CV/DTN}
Combining docking pose rank and structure with deep learning improves protein-ligand binding mode prediction
Oct 07, 2019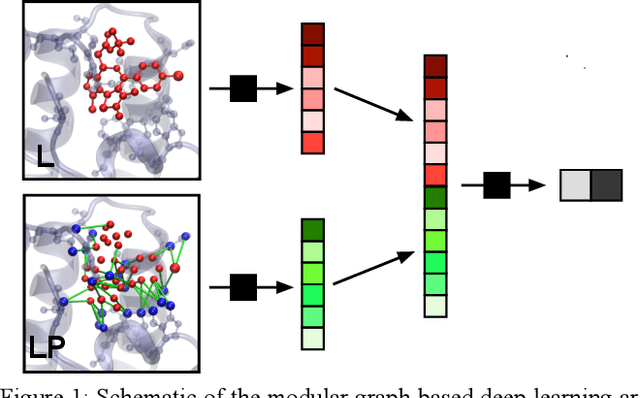
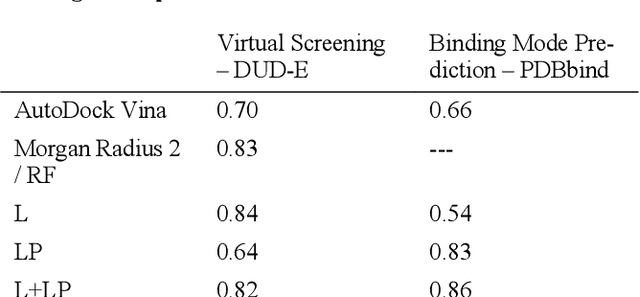
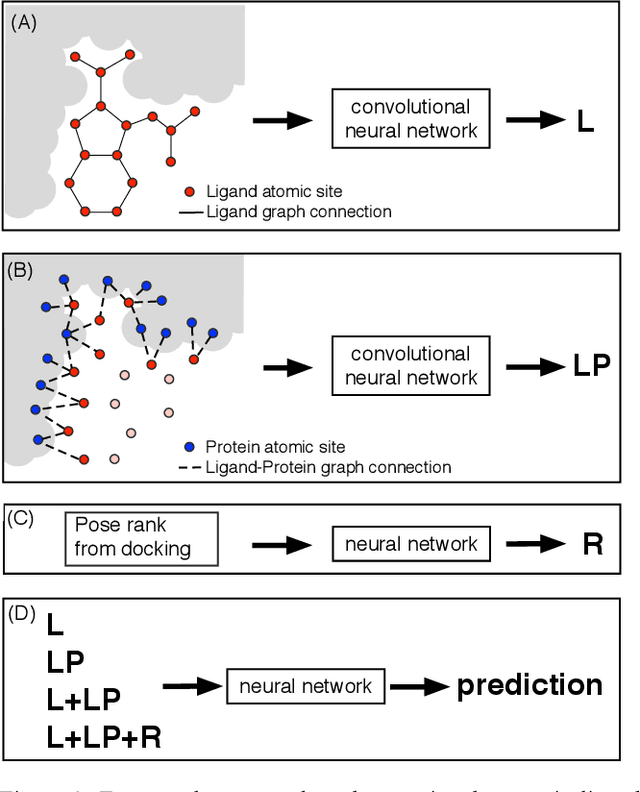
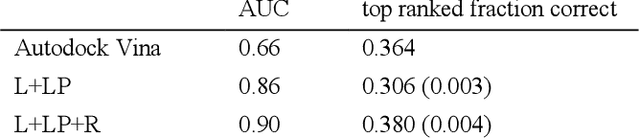
We present a simple, modular graph-based convolutional neural network that takes structural information from protein-ligand complexes as input to generate models for activity and binding mode prediction. Complex structures are generated by a standard docking procedure and fed into a dual-graph architecture that includes separate sub-networks for the ligand bonded topology and the ligand-protein contact map. This network division allows contributions from ligand identity to be distinguished from effects of protein-ligand interactions on classification. We show, in agreement with recent literature, that dataset bias drives many of the promising results on virtual screening that have previously been reported. However, we also show that our neural network is capable of learning from protein structural information when, as in the case of binding mode prediction, an unbiased dataset is constructed. We develop a deep learning model for binding mode prediction that uses docking ranking as input in combination with docking structures. This strategy mirrors past consensus models and outperforms the baseline docking program in a variety of tests, including on cross-docking datasets that mimic real-world docking use cases. Furthermore, the magnitudes of network predictions serve as reliable measures of model confidence
Natural Language Inference over Interaction Space
May 26, 2018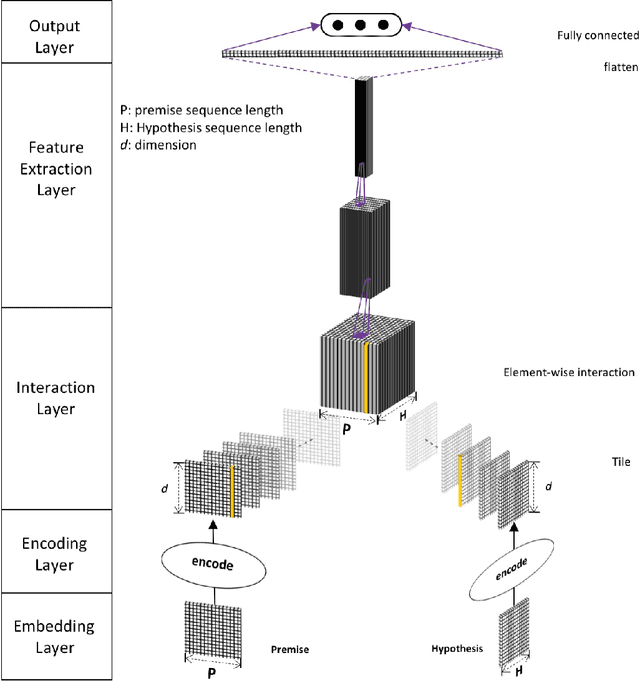
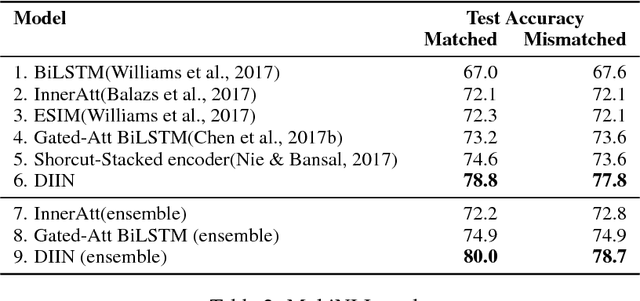
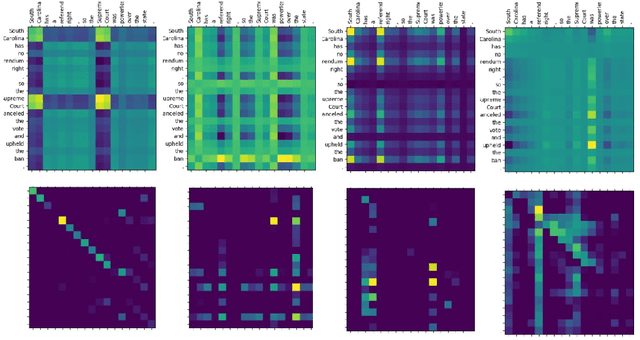
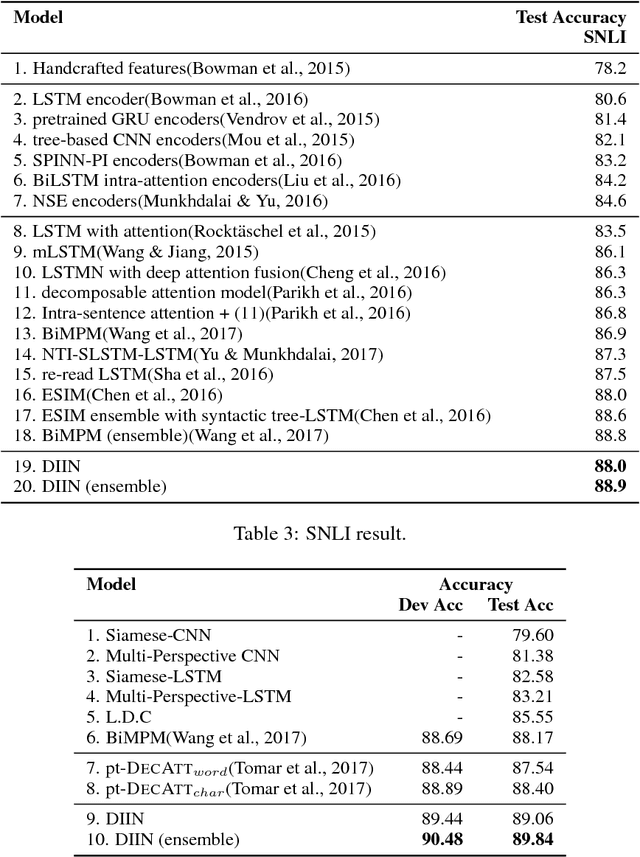
Natural Language Inference (NLI) task requires an agent to determine the logical relationship between a natural language premise and a natural language hypothesis. We introduce Interactive Inference Network (IIN), a novel class of neural network architectures that is able to achieve high-level understanding of the sentence pair by hierarchically extracting semantic features from interaction space. We show that an interaction tensor (attention weight) contains semantic information to solve natural language inference, and a denser interaction tensor contains richer semantic information. One instance of such architecture, Densely Interactive Inference Network (DIIN), demonstrates the state-of-the-art performance on large scale NLI copora and large-scale NLI alike corpus. It's noteworthy that DIIN achieve a greater than 20% error reduction on the challenging Multi-Genre NLI (MultiNLI) dataset with respect to the strongest published system.
Deep Tempering
Oct 01, 2014
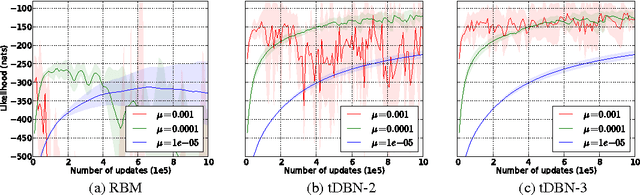
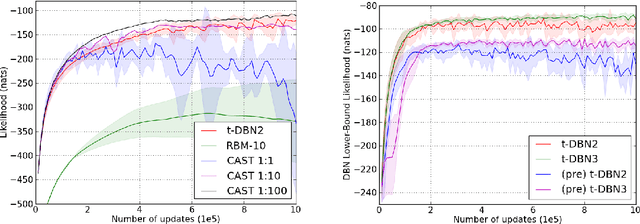
Restricted Boltzmann Machines (RBMs) are one of the fundamental building blocks of deep learning. Approximate maximum likelihood training of RBMs typically necessitates sampling from these models. In many training scenarios, computationally efficient Gibbs sampling procedures are crippled by poor mixing. In this work we propose a novel method of sampling from Boltzmann machines that demonstrates a computationally efficient way to promote mixing. Our approach leverages an under-appreciated property of deep generative models such as the Deep Belief Network (DBN), where Gibbs sampling from deeper levels of the latent variable hierarchy results in dramatically increased ergodicity. Our approach is thus to train an auxiliary latent hierarchical model, based on the DBN. When used in conjunction with parallel-tempering, the method is asymptotically guaranteed to simulate samples from the target RBM. Experimental results confirm the effectiveness of this sampling strategy in the context of RBM training.
Texture Modeling with Convolutional Spike-and-Slab RBMs and Deep Extensions
Nov 24, 2012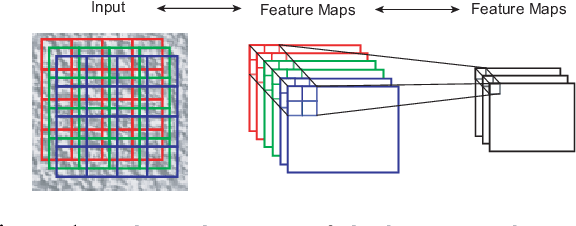

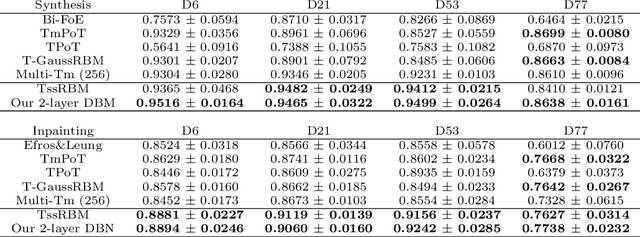

We apply the spike-and-slab Restricted Boltzmann Machine (ssRBM) to texture modeling. The ssRBM with tiled-convolution weight sharing (TssRBM) achieves or surpasses the state-of-the-art on texture synthesis and inpainting by parametric models. We also develop a novel RBM model with a spike-and-slab visible layer and binary variables in the hidden layer. This model is designed to be stacked on top of the TssRBM. We show the resulting deep belief network (DBN) is a powerful generative model that improves on single-layer models and is capable of modeling not only single high-resolution and challenging textures but also multiple textures.
Sparse Group Restricted Boltzmann Machines
Aug 30, 2010
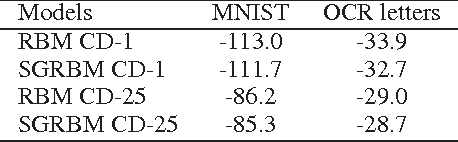


Since learning is typically very slow in Boltzmann machines, there is a need to restrict connections within hidden layers. However, the resulting states of hidden units exhibit statistical dependencies. Based on this observation, we propose using $l_1/l_2$ regularization upon the activation possibilities of hidden units in restricted Boltzmann machines to capture the loacal dependencies among hidden units. This regularization not only encourages hidden units of many groups to be inactive given observed data but also makes hidden units within a group compete with each other for modeling observed data. Thus, the $l_1/l_2$ regularization on RBMs yields sparsity at both the group and the hidden unit levels. We call RBMs trained with the regularizer \emph{sparse group} RBMs. The proposed sparse group RBMs are applied to three tasks: modeling patches of natural images, modeling handwritten digits and pretaining a deep networks for a classification task. Furthermore, we illustrate the regularizer can also be applied to deep Boltzmann machines, which lead to sparse group deep Boltzmann machines. When adapted to the MNIST data set, a two-layer sparse group Boltzmann machine achieves an error rate of $0.84\%$, which is, to our knowledge, the best published result on the permutation-invariant version of the MNIST task.