 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDACA-Net: A Degradation-Aware Conditional Diffusion Network for Underwater Image Enhancement
Jul 30, 2025Underwater images typically suffer from severe colour distortions, low visibility, and reduced structural clarity due to complex optical effects such as scattering and absorption, which greatly degrade their visual quality and limit the performance of downstream visual perception tasks. Existing enhancement methods often struggle to adaptively handle diverse degradation conditions and fail to leverage underwater-specific physical priors effectively. In this paper, we propose a degradation-aware conditional diffusion model to enhance underwater images adaptively and robustly. Given a degraded underwater image as input, we first predict its degradation level using a lightweight dual-stream convolutional network, generating a continuous degradation score as semantic guidance. Based on this score, we introduce a novel conditional diffusion-based restoration network with a Swin UNet backbone, enabling adaptive noise scheduling and hierarchical feature refinement. To incorporate underwater-specific physical priors, we further propose a degradation-guided adaptive feature fusion module and a hybrid loss function that combines perceptual consistency, histogram matching, and feature-level contrast. Comprehensive experiments on benchmark datasets demonstrate that our method effectively restores underwater images with superior colour fidelity, perceptual quality, and structural details. Compared with SOTA approaches, our framework achieves significant improvements in both quantitative metrics and qualitative visual assessments.
DiffAD: A Unified Diffusion Modeling Approach for Autonomous Driving
Mar 15, 2025End-to-end autonomous driving (E2E-AD) has rapidly emerged as a promising approach toward achieving full autonomy. However, existing E2E-AD systems typically adopt a traditional multi-task framework, addressing perception, prediction, and planning tasks through separate task-specific heads. Despite being trained in a fully differentiable manner, they still encounter issues with task coordination, and the system complexity remains high. In this work, we introduce DiffAD, a novel diffusion probabilistic model that redefines autonomous driving as a conditional image generation task. By rasterizing heterogeneous targets onto a unified bird's-eye view (BEV) and modeling their latent distribution, DiffAD unifies various driving objectives and jointly optimizes all driving tasks in a single framework, significantly reducing system complexity and harmonizing task coordination. The reverse process iteratively refines the generated BEV image, resulting in more robust and realistic driving behaviors. Closed-loop evaluations in Carla demonstrate the superiority of the proposed method, achieving a new state-of-the-art Success Rate and Driving Score. The code will be made publicly available.
Omnidirectional Multi-Object Tracking
Mar 06, 2025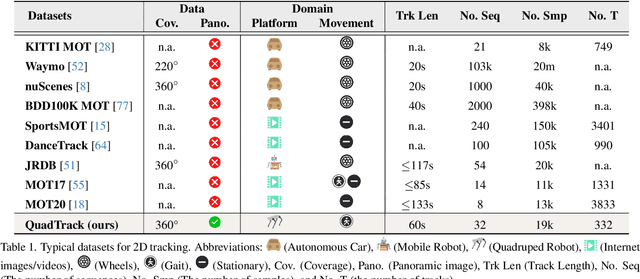
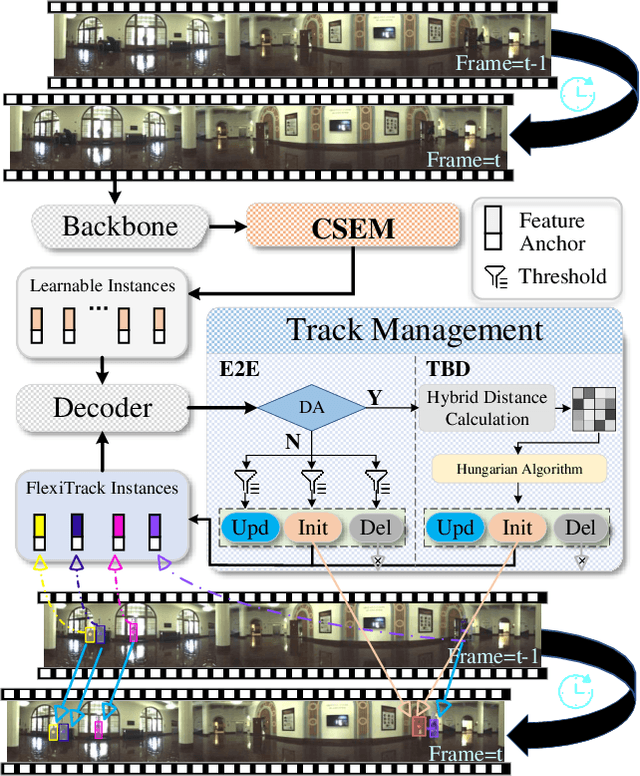
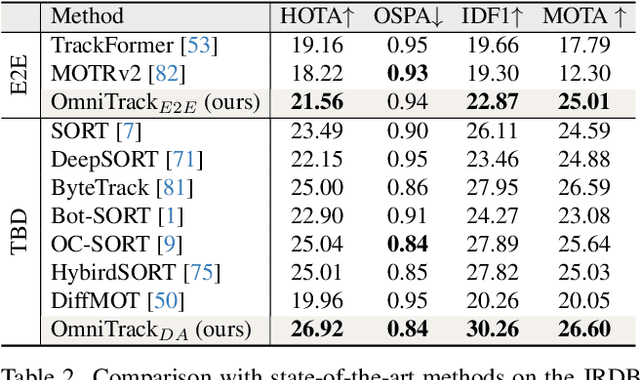
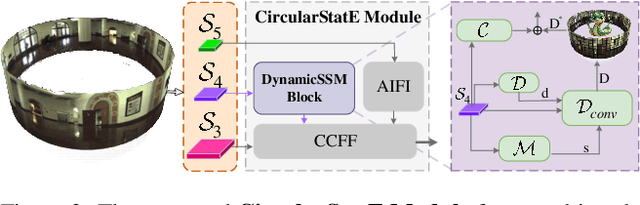
Panoramic imagery, with its 360{\deg} field of view, offers comprehensive information to support Multi-Object Tracking (MOT) in capturing spatial and temporal relationships of surrounding objects. However, most MOT algorithms are tailored for pinhole images with limited views, impairing their effectiveness in panoramic settings. Additionally, panoramic image distortions, such as resolution loss, geometric deformation, and uneven lighting, hinder direct adaptation of existing MOT methods, leading to significant performance degradation. To address these challenges, we propose OmniTrack, an omnidirectional MOT framework that incorporates Tracklet Management to introduce temporal cues, FlexiTrack Instances for object localization and association, and the CircularStatE Module to alleviate image and geometric distortions. This integration enables tracking in large field-of-view scenarios, even under rapid sensor motion. To mitigate the lack of panoramic MOT datasets, we introduce the QuadTrack dataset--a comprehensive panoramic dataset collected by a quadruped robot, featuring diverse challenges such as wide fields of view, intense motion, and complex environments. Extensive experiments on the public JRDB dataset and the newly introduced QuadTrack benchmark demonstrate the state-of-the-art performance of the proposed framework. OmniTrack achieves a HOTA score of 26.92% on JRDB, representing an improvement of 3.43%, and further achieves 23.45% on QuadTrack, surpassing the baseline by 6.81%. The dataset and code will be made publicly available at https://github.com/xifen523/OmniTrack.
Senna: Bridging Large Vision-Language Models and End-to-End Autonomous Driving
Oct 29, 2024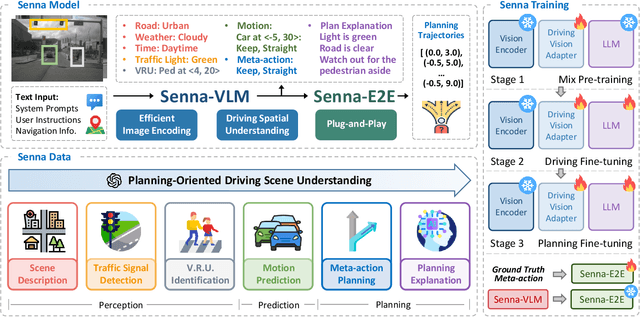
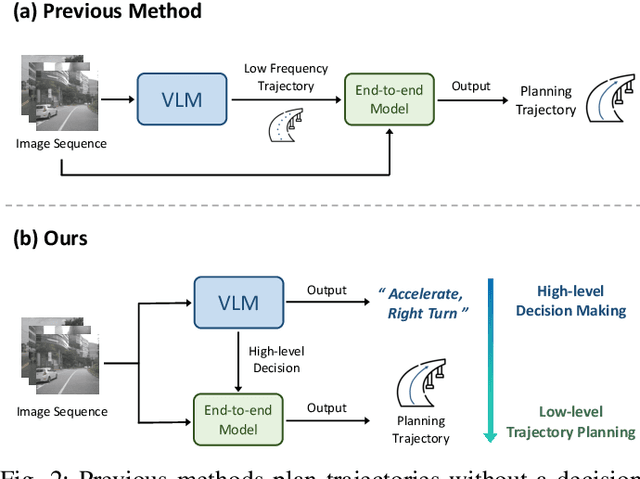
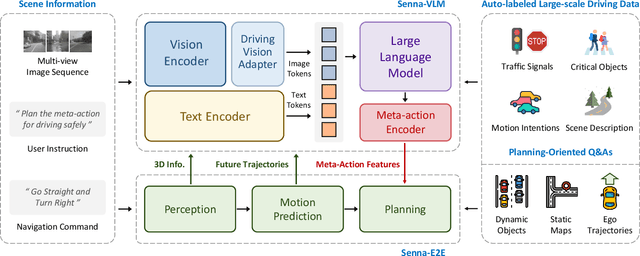

End-to-end autonomous driving demonstrates strong planning capabilities with large-scale data but still struggles in complex, rare scenarios due to limited commonsense. In contrast, Large Vision-Language Models (LVLMs) excel in scene understanding and reasoning. The path forward lies in merging the strengths of both approaches. Previous methods using LVLMs to predict trajectories or control signals yield suboptimal results, as LVLMs are not well-suited for precise numerical predictions. This paper presents Senna, an autonomous driving system combining an LVLM (Senna-VLM) with an end-to-end model (Senna-E2E). Senna decouples high-level planning from low-level trajectory prediction. Senna-VLM generates planning decisions in natural language, while Senna-E2E predicts precise trajectories. Senna-VLM utilizes a multi-image encoding approach and multi-view prompts for efficient scene understanding. Besides, we introduce planning-oriented QAs alongside a three-stage training strategy, which enhances Senna-VLM's planning performance while preserving commonsense. Extensive experiments on two datasets show that Senna achieves state-of-the-art planning performance. Notably, with pre-training on a large-scale dataset DriveX and fine-tuning on nuScenes, Senna significantly reduces average planning error by 27.12% and collision rate by 33.33% over model without pre-training. We believe Senna's cross-scenario generalization and transferability are essential for achieving fully autonomous driving. Code and models will be released at https://github.com/hustvl/Senna.
ViG: Linear-complexity Visual Sequence Learning with Gated Linear Attention
May 29, 2024Recently, linear complexity sequence modeling networks have achieved modeling capabilities similar to Vision Transformers on a variety of computer vision tasks, while using fewer FLOPs and less memory. However, their advantage in terms of actual runtime speed is not significant. To address this issue, we introduce Gated Linear Attention (GLA) for vision, leveraging its superior hardware-awareness and efficiency. We propose direction-wise gating to capture 1D global context through bidirectional modeling and a 2D gating locality injection to adaptively inject 2D local details into 1D global context. Our hardware-aware implementation further merges forward and backward scanning into a single kernel, enhancing parallelism and reducing memory cost and latency. The proposed model, ViG, offers a favorable trade-off in accuracy, parameters, and FLOPs on ImageNet and downstream tasks, outperforming popular Transformer and CNN-based models. Notably, ViG-S matches DeiT-B's accuracy while using only 27% of the parameters and 20% of the FLOPs, running 2$\times$ faster on $224\times224$ images. At $1024\times1024$ resolution, ViG-T uses 5.2$\times$ fewer FLOPs, saves 90% GPU memory, runs 4.8$\times$ faster, and achieves 20.7% higher top-1 accuracy than DeiT-T. These results position ViG as an efficient and scalable solution for visual representation learning. Code is available at \url{https://github.com/hustvl/ViG}.
POWQMIX: Weighted Value Factorization with Potentially Optimal Joint Actions Recognition for Cooperative Multi-Agent Reinforcement Learning
May 15, 2024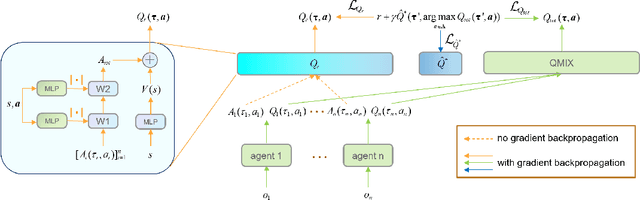
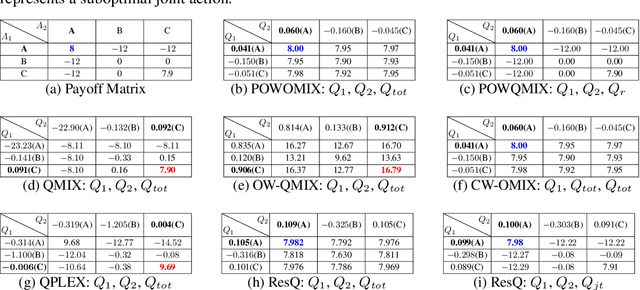
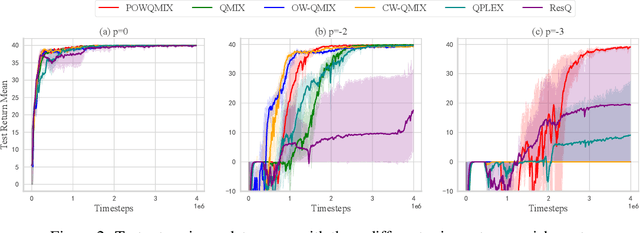
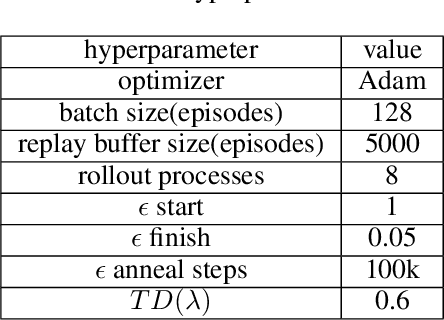
Value function factorization methods are commonly used in cooperative multi-agent reinforcement learning, with QMIX receiving significant attention. Many QMIX-based methods introduce monotonicity constraints between the joint action value and individual action values to achieve decentralized execution. However, such constraints limit the representation capacity of value factorization, restricting the joint action values it can represent and hindering the learning of the optimal policy. To address this challenge, we propose the Potentially Optimal joint actions Weighted QMIX (POWQMIX) algorithm, which recognizes the potentially optimal joint actions and assigns higher weights to the corresponding losses of these joint actions during training. We theoretically prove that with such a weighted training approach the optimal policy is guaranteed to be recovered. Experiments in matrix games, predator-prey, and StarCraft II Multi-Agent Challenge environments demonstrate that our algorithm outperforms the state-of-the-art value-based multi-agent reinforcement learning methods.
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
Feb 20, 2024



Learning a human-like driving policy from large-scale driving demonstrations is promising, but the uncertainty and non-deterministic nature of planning make it challenging. In this work, to cope with the uncertainty problem, we propose VADv2, an end-to-end driving model based on probabilistic planning. VADv2 takes multi-view image sequences as input in a streaming manner, transforms sensor data into environmental token embeddings, outputs the probabilistic distribution of action, and samples one action to control the vehicle. Only with camera sensors, VADv2 achieves state-of-the-art closed-loop performance on the CARLA Town05 benchmark, significantly outperforming all existing methods. It runs stably in a fully end-to-end manner, even without the rule-based wrapper. Closed-loop demos are presented at https://hgao-cv.github.io/VADv2.
Circuit as Set of Points
Oct 26, 2023



As the size of circuit designs continues to grow rapidly, artificial intelligence technologies are being extensively used in Electronic Design Automation (EDA) to assist with circuit design. Placement and routing are the most time-consuming parts of the physical design process, and how to quickly evaluate the placement has become a hot research topic. Prior works either transformed circuit designs into images using hand-crafted methods and then used Convolutional Neural Networks (CNN) to extract features, which are limited by the quality of the hand-crafted methods and could not achieve end-to-end training, or treated the circuit design as a graph structure and used Graph Neural Networks (GNN) to extract features, which require time-consuming preprocessing. In our work, we propose a novel perspective for circuit design by treating circuit components as point clouds and using Transformer-based point cloud perception methods to extract features from the circuit. This approach enables direct feature extraction from raw data without any preprocessing, allows for end-to-end training, and results in high performance. Experimental results show that our method achieves state-of-the-art performance in congestion prediction tasks on both the CircuitNet and ISPD2015 datasets, as well as in design rule check (DRC) violation prediction tasks on the CircuitNet dataset. Our method establishes a bridge between the relatively mature point cloud perception methods and the fast-developing EDA algorithms, enabling us to leverage more collective intelligence to solve this task. To facilitate the research of open EDA design, source codes and pre-trained models are released at https://github.com/hustvl/circuitformer.
MapTRv2: An End-to-End Framework for Online Vectorized HD Map Construction
Aug 10, 2023



High-definition (HD) map provides abundant and precise static environmental information of the driving scene, serving as a fundamental and indispensable component for planning in autonomous driving system. In this paper, we present \textbf{Map} \textbf{TR}ansformer, an end-to-end framework for online vectorized HD map construction. We propose a unified permutation-equivalent modeling approach, \ie, modeling map element as a point set with a group of equivalent permutations, which accurately describes the shape of map element and stabilizes the learning process. We design a hierarchical query embedding scheme to flexibly encode structured map information and perform hierarchical bipartite matching for map element learning. To speed up convergence, we further introduce auxiliary one-to-many matching and dense supervision. The proposed method well copes with various map elements with arbitrary shapes. It runs at real-time inference speed and achieves state-of-the-art performance on both nuScenes and Argoverse2 datasets. Abundant qualitative results show stable and robust map construction quality in complex and various driving scenes. Code and more demos are available at \url{https://github.com/hustvl/MapTR} for facilitating further studies and applications.
Safe Reinforcement Learning with Dead-Ends Avoidance and Recovery
Jun 24, 2023



Safety is one of the main challenges in applying reinforcement learning to realistic environmental tasks. To ensure safety during and after training process, existing methods tend to adopt overly conservative policy to avoid unsafe situations. However, overly conservative policy severely hinders the exploration, and makes the algorithms substantially less rewarding. In this paper, we propose a method to construct a boundary that discriminates safe and unsafe states. The boundary we construct is equivalent to distinguishing dead-end states, indicating the maximum extent to which safe exploration is guaranteed, and thus has minimum limitation on exploration. Similar to Recovery Reinforcement Learning, we utilize a decoupled RL framework to learn two policies, (1) a task policy that only considers improving the task performance, and (2) a recovery policy that maximizes safety. The recovery policy and a corresponding safety critic are pretrained on an offline dataset, in which the safety critic evaluates upper bound of safety in each state as awareness of environmental safety for the agent. During online training, a behavior correction mechanism is adopted, ensuring the agent to interact with the environment using safe actions only. Finally, experiments of continuous control tasks demonstrate that our approach has better task performance with less safety violations than state-of-the-art algorithms.