 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFloorSAM: SAM-Guided Floorplan Reconstruction with Semantic-Geometric Fusion
Sep 19, 2025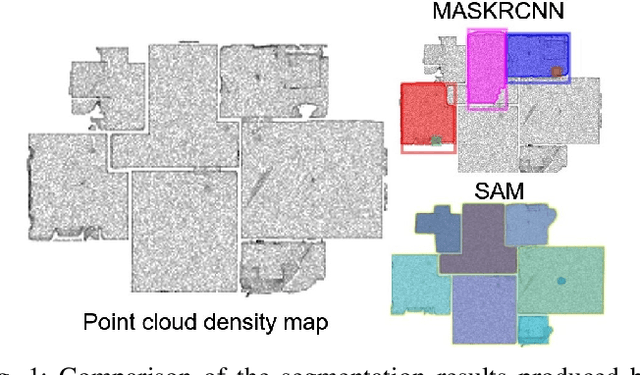

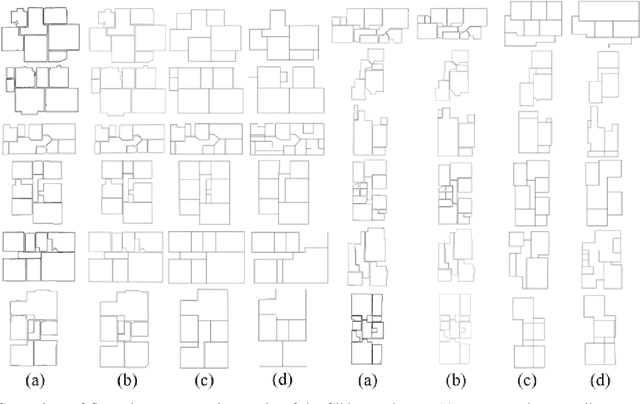
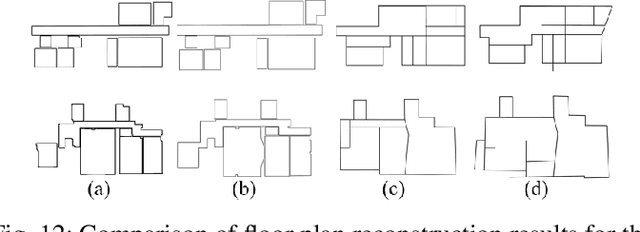
Reconstructing building floor plans from point cloud data is key for indoor navigation, BIM, and precise measurements. Traditional methods like geometric algorithms and Mask R-CNN-based deep learning often face issues with noise, limited generalization, and loss of geometric details. We propose FloorSAM, a framework that integrates point cloud density maps with the Segment Anything Model (SAM) for accurate floor plan reconstruction from LiDAR data. Using grid-based filtering, adaptive resolution projection, and image enhancement, we create robust top-down density maps. FloorSAM uses SAM's zero-shot learning for precise room segmentation, improving reconstruction across diverse layouts. Room masks are generated via adaptive prompt points and multistage filtering, followed by joint mask and point cloud analysis for contour extraction and regularization. This produces accurate floor plans and recovers room topological relationships. Tests on Giblayout and ISPRS datasets show better accuracy, recall, and robustness than traditional methods, especially in noisy and complex settings. Code and materials: github.com/Silentbarber/FloorSAM.
MapTRv2: An End-to-End Framework for Online Vectorized HD Map Construction
Aug 10, 2023



High-definition (HD) map provides abundant and precise static environmental information of the driving scene, serving as a fundamental and indispensable component for planning in autonomous driving system. In this paper, we present \textbf{Map} \textbf{TR}ansformer, an end-to-end framework for online vectorized HD map construction. We propose a unified permutation-equivalent modeling approach, \ie, modeling map element as a point set with a group of equivalent permutations, which accurately describes the shape of map element and stabilizes the learning process. We design a hierarchical query embedding scheme to flexibly encode structured map information and perform hierarchical bipartite matching for map element learning. To speed up convergence, we further introduce auxiliary one-to-many matching and dense supervision. The proposed method well copes with various map elements with arbitrary shapes. It runs at real-time inference speed and achieves state-of-the-art performance on both nuScenes and Argoverse2 datasets. Abundant qualitative results show stable and robust map construction quality in complex and various driving scenes. Code and more demos are available at \url{https://github.com/hustvl/MapTR} for facilitating further studies and applications.
VMA: Divide-and-Conquer Vectorized Map Annotation System for Large-Scale Driving Scene
Apr 19, 2023



High-definition (HD) map serves as the essential infrastructure of autonomous driving. In this work, we build up a systematic vectorized map annotation framework (termed VMA) for efficiently generating HD map of large-scale driving scene. We design a divide-and-conquer annotation scheme to solve the spatial extensibility problem of HD map generation, and abstract map elements with a variety of geometric patterns as unified point sequence representation, which can be extended to most map elements in the driving scene. VMA is highly efficient and extensible, requiring negligible human effort, and flexible in terms of spatial scale and element type. We quantitatively and qualitatively validate the annotation performance on real-world urban and highway scenes, as well as NYC Planimetric Database. VMA can significantly improve map generation efficiency and require little human effort. On average VMA takes 160min for annotating a scene with a range of hundreds of meters, and reduces 52.3% of the human cost, showing great application value.