 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVMA: Divide-and-Conquer Vectorized Map Annotation System for Large-Scale Driving Scene
Apr 19, 2023



High-definition (HD) map serves as the essential infrastructure of autonomous driving. In this work, we build up a systematic vectorized map annotation framework (termed VMA) for efficiently generating HD map of large-scale driving scene. We design a divide-and-conquer annotation scheme to solve the spatial extensibility problem of HD map generation, and abstract map elements with a variety of geometric patterns as unified point sequence representation, which can be extended to most map elements in the driving scene. VMA is highly efficient and extensible, requiring negligible human effort, and flexible in terms of spatial scale and element type. We quantitatively and qualitatively validate the annotation performance on real-world urban and highway scenes, as well as NYC Planimetric Database. VMA can significantly improve map generation efficiency and require little human effort. On average VMA takes 160min for annotating a scene with a range of hundreds of meters, and reduces 52.3% of the human cost, showing great application value.
FastRE: Towards Fast Relation Extraction with Convolutional Encoder and Improved Cascade Binary Tagging Framework
May 05, 2022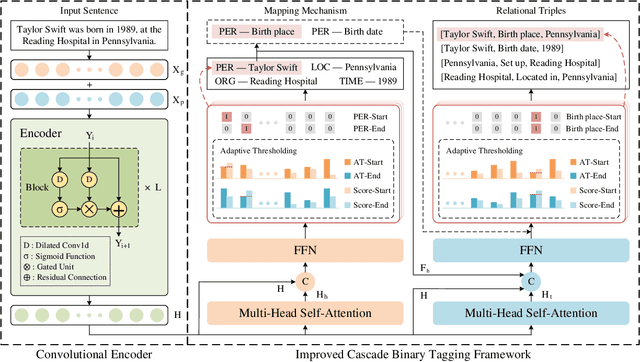
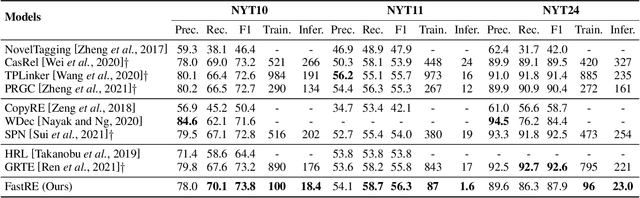
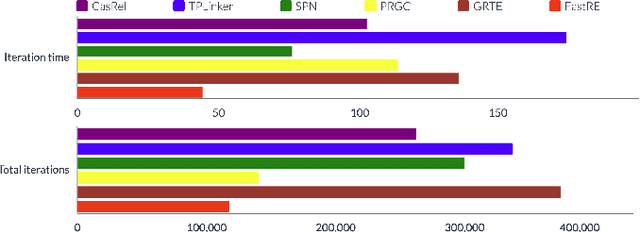
Recent work for extracting relations from texts has achieved excellent performance. However, most existing methods pay less attention to the efficiency, making it still challenging to quickly extract relations from massive or streaming text data in realistic scenarios. The main efficiency bottleneck is that these methods use a Transformer-based pre-trained language model for encoding, which heavily affects the training speed and inference speed. To address this issue, we propose a fast relation extraction model (FastRE) based on convolutional encoder and improved cascade binary tagging framework. Compared to previous work, FastRE employs several innovations to improve efficiency while also keeping promising performance. Concretely, FastRE adopts a novel convolutional encoder architecture combined with dilated convolution, gated unit and residual connection, which significantly reduces the computation cost of training and inference, while maintaining the satisfactory performance. Moreover, to improve the cascade binary tagging framework, FastRE first introduces a type-relation mapping mechanism to accelerate tagging efficiency and alleviate relation redundancy, and then utilizes a position-dependent adaptive thresholding strategy to obtain higher tagging accuracy and better model generalization. Experimental results demonstrate that FastRE is well balanced between efficiency and performance, and achieves 3-10x training speed, 7-15x inference speed faster, and 1/100 parameters compared to the state-of-the-art models, while the performance is still competitive.
Monocular Road Planar Parallax Estimation
Nov 22, 2021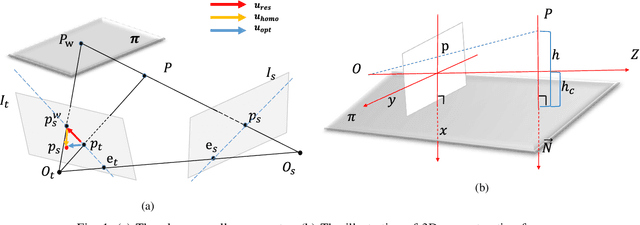
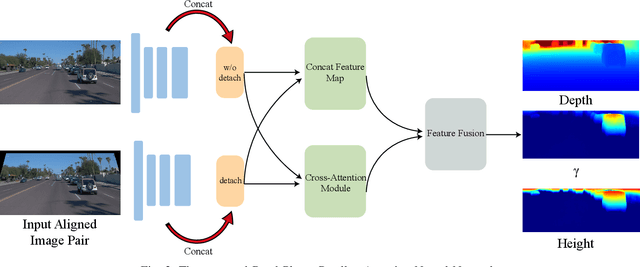
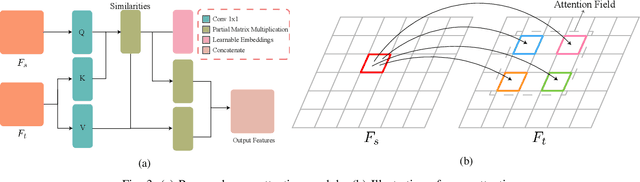

Estimating the 3D structure of the drivable surface and surrounding environment is a crucial task for assisted and autonomous driving. It is commonly solved either by using expensive 3D sensors such as LiDAR or directly predicting the depth of points via deep learning. Instead of following existing methodologies, we propose Road Planar Parallax Attention Network (RPANet), a new deep neural network for 3D sensing from monocular image sequences based on planar parallax, which takes full advantage of the commonly seen road plane geometry in driving scenes. RPANet takes a pair of images aligned by the homography of the road plane as input and outputs a $\gamma$ map for 3D reconstruction. Beyond estimating the depth or height, the $\gamma$ map has a potential to construct a two-dimensional transformation between two consecutive frames while can be easily derived to depth or height. By warping the consecutive frames using the road plane as a reference, the 3D structure can be estimated from the planar parallax and the residual image displacements. Furthermore, to make the network better perceive the displacements caused by planar parallax, we introduce a novel cross-attention module. We sample data from the Waymo Open Dataset and construct data related to planar parallax. Comprehensive experiments are conducted on the sampled dataset to demonstrate the 3D reconstruction accuracy of our approach in challenging scenarios.
Improving Fast Segmentation With Teacher-student Learning
Oct 19, 2018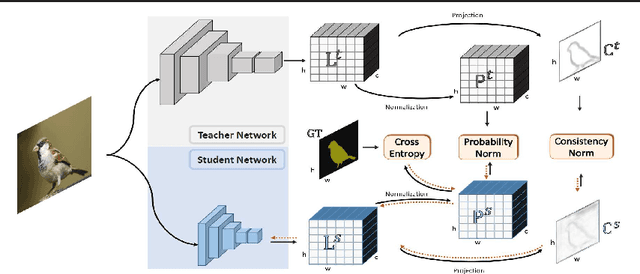

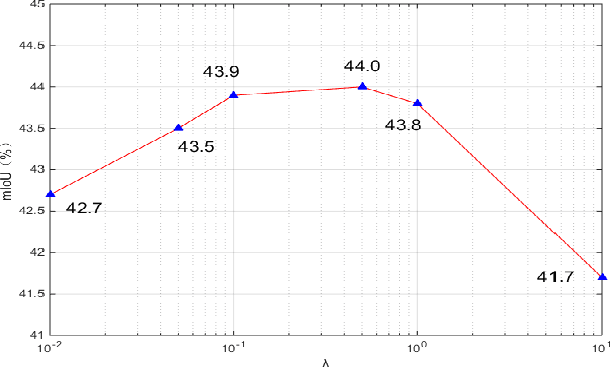

Recently, segmentation neural networks have been significantly improved by demonstrating very promising accuracies on public benchmarks. However, these models are very heavy and generally suffer from low inference speed, which limits their application scenarios in practice. Meanwhile, existing fast segmentation models usually fail to obtain satisfactory segmentation accuracies on public benchmarks. In this paper, we propose a teacher-student learning framework that transfers the knowledge gained by a heavy and better performed segmentation network (i.e. teacher) to guide the learning of fast segmentation networks (i.e. student). Specifically, both zero-order and first-order knowledge depicted in the fine annotated images and unlabeled auxiliary data are transferred to regularize our student learning. The proposed method can improve existing fast segmentation models without incurring extra computational overhead, so it can still process images with the same fast speed. Extensive experiments on the Pascal Context, Cityscape and VOC 2012 datasets demonstrate that the proposed teacher-student learning framework is able to significantly boost the performance of student network.
* 13 pages, 3 figures, conference