 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Descriptive to Prescriptive: Uncover the Social Value Alignment of LLM-based Agents
May 13, 2026Wide applications of LLM-based agents require strong alignment with human social values. However, current works still exhibit deficiencies in self-cognition and dilemma decision, as well as self-emotions. To remedy this, we propose a novel value-based framework that employs GraphRAG to convert principles into value-based instructions and steer the agent to behave as expected by retrieving the suitable instruction upon a specific conversation context. To evaluate the ratio of expected behaviors, we define the expected behaviors from two famous theories, Maslow's Hierarchy of Needs and Plutchik's Wheel of Emotion. By experimenting with our method on the benchmark of DAILYDILEMMAS, our method exhibits significant performance gains compared to prompt-based baselines, including ECoT, Plan-and-Solve, and Metacognitive prompting. Our method provides a basis for the emergence of self-emotion in AI systems.
Learn-to-learn on Arbitrary Textual Conditioning: A Hypernetwork-Driven Meta-Gated LLM
May 03, 2026Conventional LLMs may suffer from corpus heterogeneity and subtle condition changes. While finetuning can create the catastrophe forgetting issue, application of meta-learning on LLMs is also limited due to its complexity and scalability. In this paper, we activate the meta-signal of $β$ within the SwiGLU blocks, resulting in a meta-gating mechanism that adaptively adjusts the nonlinearity of FFN. A hypernetwork is employed which dynamically produces $β$ on textual conditions, providing meta-controllability on LLMs. By testing on different condition types such as task, domain, persona, and style, our method outperforms finetuning and meta-learning baselines, and can generalize reasonably on unseen tasks, condition types, or instructions. Our code can be found in https://github.com/AaronJi/MeGan.
Efficient Rationale-based Retrieval: On-policy Distillation from Generative Rerankers based on JEPA
Apr 25, 2026Unlike traditional fact-based retrieval, rationale-based retrieval typically necessitates cross-encoding of query-document pairs using large language models, incurring substantial computational costs. To address this limitation, we propose Rabtriever, which independently encodes queries and documents, while providing comparable cross query-document comprehension capabilities to rerankers. We start from training a LLM-based generative reranker, which puts the document prior to the query and prompts the LLM to generate the relevance score by log probabilities. We then employ it as the teacher of an on-policy distillation framework, with Rabtriever as the student to reconstruct the teacher's contextual-aware query embedding. To achieve this effect, Rabtriever is first initialized from the teacher, with parameters frozen. The Joint-Embedding Predictive Architecture (JEPA) paradigm is then adopted, which integrates a lightweight, trainable predictor between LLM layers and heads, projecting the query embedding into a new hidden space, with the document embedding as the latent vector. JEPA then minimizes the distribution difference between this projected embedding and the teacher embedding. To strengthen the sampling efficiency of on-policy distillation, we also add an auxiliary loss on the reverse KL of LLM logits, to reshape the student's logit distribution. Rabtriever optimizes the teacher's quadratic complexity on the document length to linear, verified both theoretically and empirically. Experiments show that Rabtriever outperforms different retriever baselines across diverse rationale-based tasks, including empathetic conversations and robotic manipulations, with minor accuracy degradation from the reranker. Rabtriever also generalizes well on traditional retrieval benchmarks such as MS MARCO and BEIR, with comparable performance to the best retriever baseline.
IGV-RRT: Prior-Real-Time Observation Fusion for Active Object Search in Changing Environments
Mar 23, 2026Object Goal Navigation (ObjectNav) in temporally changing indoor environments is challenging because object relocation can invalidate historical scene knowledge. To address this issue, we propose a probabilistic planning framework that combines uncertainty-aware scene priors with online target relevance estimates derived from a Vision Language Model (VLM). The framework contains a dual-layer semantic mapping module and a real-time planner. The mapping module includes an Information Gain Map (IGM) built from a 3D scene graph (3DSG) during prior exploration to model object co-occurrence relations and provide global guidance on likely target regions. It also maintains a VLM score map (VLM-SM) that fuses confidence-weighted semantic observations into the map for local validation of the current scene. Based on these two cues, we develop a planner that jointly exploits information gain and semantic evidence for online decision making. The planner biases tree expansion toward semantically salient regions with high prior likelihood and strong online relevance (IGV-RRT), while preserving kinematic feasibility through gradient-based analysis. Simulation and real-world experiments demonstrate that the proposed method effectively mitigates the impact of object rearrangement, achieving higher search efficiency and success rates than representative baselines in complex indoor environments.
OneOcc: Semantic Occupancy Prediction for Legged Robots with a Single Panoramic Camera
Nov 05, 2025Robust 3D semantic occupancy is crucial for legged/humanoid robots, yet most semantic scene completion (SSC) systems target wheeled platforms with forward-facing sensors. We present OneOcc, a vision-only panoramic SSC framework designed for gait-introduced body jitter and 360{\deg} continuity. OneOcc combines: (i) Dual-Projection fusion (DP-ER) to exploit the annular panorama and its equirectangular unfolding, preserving 360{\deg} continuity and grid alignment; (ii) Bi-Grid Voxelization (BGV) to reason in Cartesian and cylindrical-polar spaces, reducing discretization bias and sharpening free/occupied boundaries; (iii) a lightweight decoder with Hierarchical AMoE-3D for dynamic multi-scale fusion and better long-range/occlusion reasoning; and (iv) plug-and-play Gait Displacement Compensation (GDC) learning feature-level motion correction without extra sensors. We also release two panoramic occupancy benchmarks: QuadOcc (real quadruped, first-person 360{\deg}) and Human360Occ (H3O) (CARLA human-ego 360{\deg} with RGB, Depth, semantic occupancy; standardized within-/cross-city splits). OneOcc sets new state-of-the-art (SOTA): on QuadOcc it beats strong vision baselines and popular LiDAR ones; on H3O it gains +3.83 mIoU (within-city) and +8.08 (cross-city). Modules are lightweight, enabling deployable full-surround perception for legged/humanoid robots. Datasets and code will be publicly available at https://github.com/MasterHow/OneOcc.
Dream to Chat: Model-based Reinforcement Learning on Dialogues with User Belief Modeling
Aug 23, 2025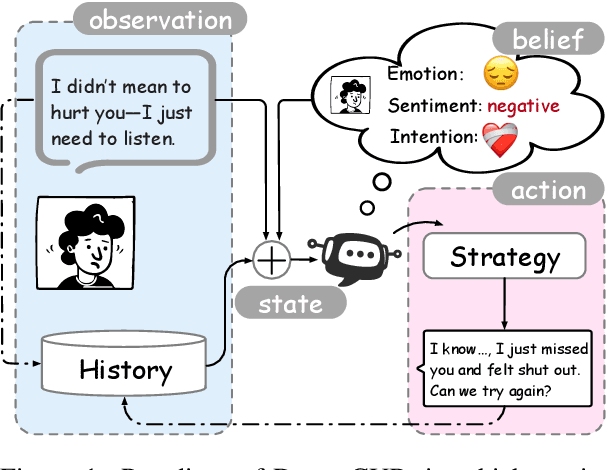
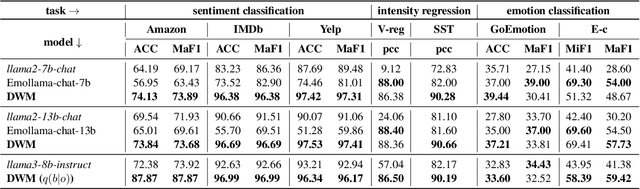
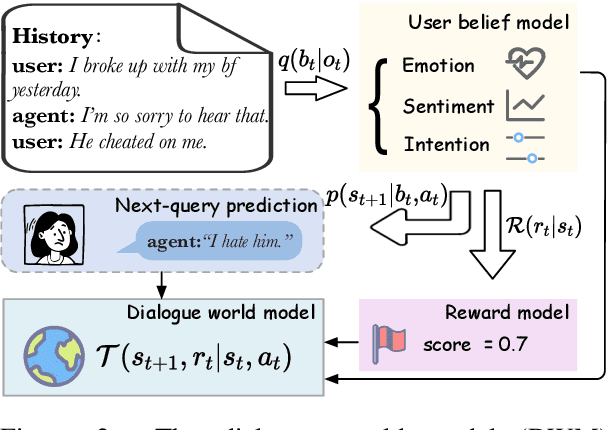
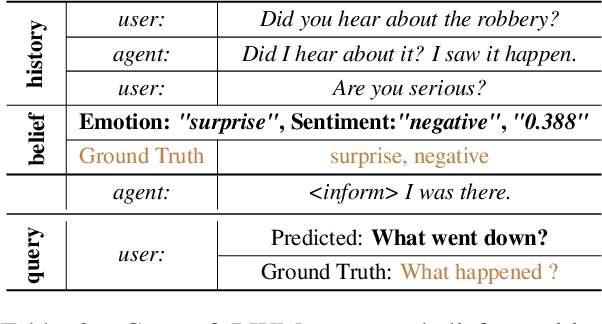
World models have been widely utilized in robotics, gaming, and auto-driving. However, their applications on natural language tasks are relatively limited. In this paper, we construct the dialogue world model, which could predict the user's emotion, sentiment, and intention, and future utterances. By defining a POMDP, we argue emotion, sentiment and intention can be modeled as the user belief and solved by maximizing the information bottleneck. By this user belief modeling, we apply the model-based reinforcement learning framework to the dialogue system, and propose a framework called DreamCUB. Experiments show that the pretrained dialogue world model can achieve state-of-the-art performances on emotion classification and sentiment identification, while dialogue quality is also enhanced by joint training of the policy, critic and dialogue world model. Further analysis shows that this manner holds a reasonable exploration-exploitation balance and also transfers well to out-of-domain scenarios such as empathetic dialogues.
FiSMiness: A Finite State Machine Based Paradigm for Emotional Support Conversations
Apr 16, 2025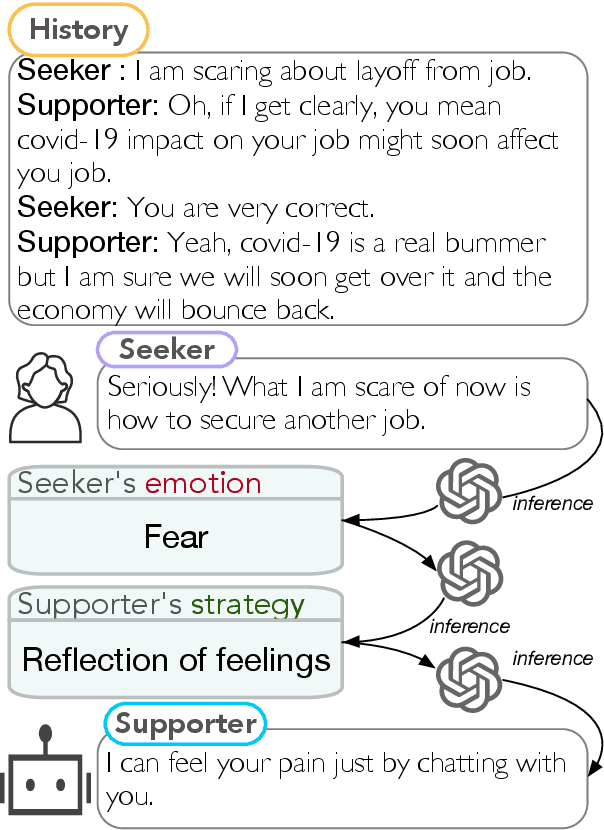
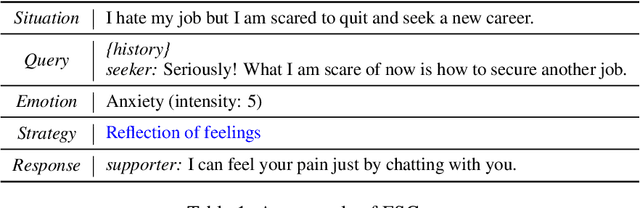
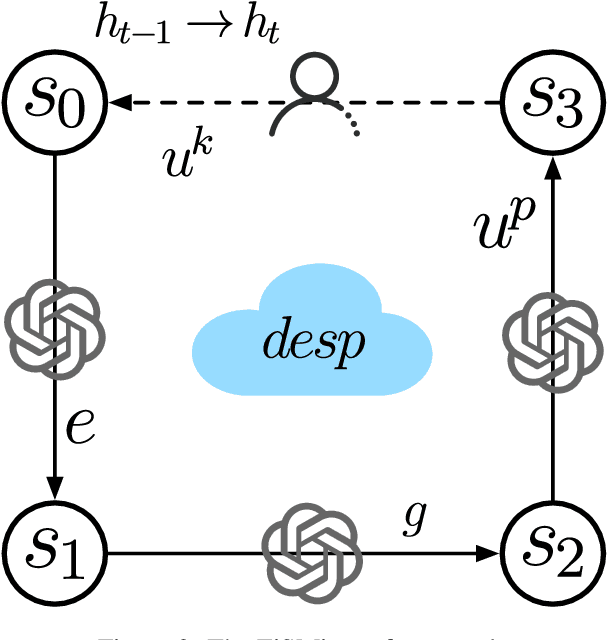
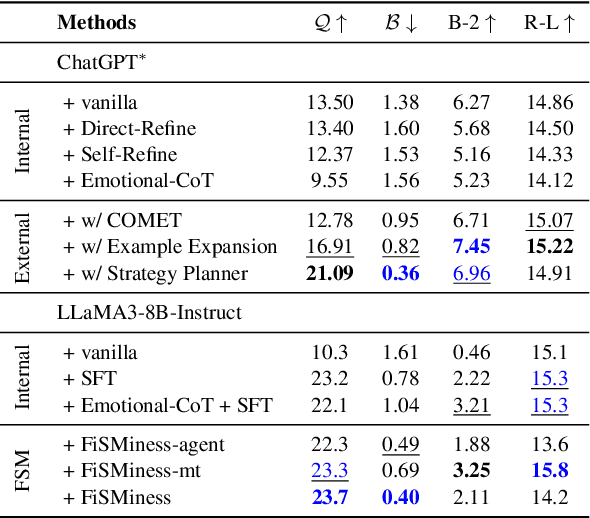
Emotional support conversation (ESC) aims to alleviate the emotional distress of individuals through effective conversations. Although large language models (LLMs) have obtained remarkable progress on ESC, most of these studies might not define the diagram from the state model perspective, therefore providing a suboptimal solution for long-term satisfaction. To address such an issue, we leverage the Finite State Machine (FSM) on LLMs, and propose a framework called FiSMiness. Our framework allows a single LLM to bootstrap the planning during ESC, and self-reason the seeker's emotion, support strategy and the final response upon each conversational turn. Substantial experiments on ESC datasets suggest that FiSMiness outperforms many baselines, including direct inference, self-refine, chain of thought, finetuning, and external-assisted methods, even those with many more parameters.
Large Language Model Can Be a Foundation for Hidden Rationale-Based Retrieval
Dec 21, 2024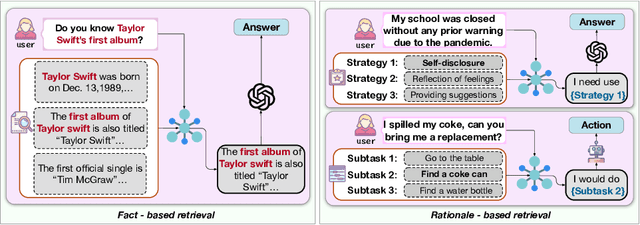
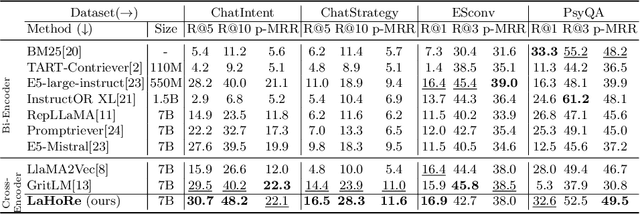
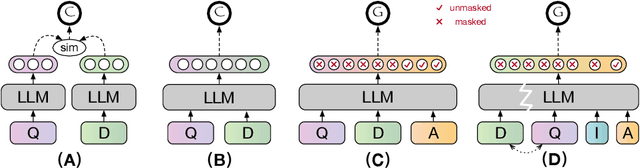
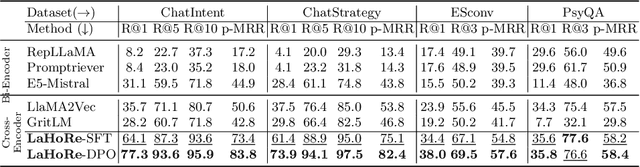
Despite the recent advancement in Retrieval-Augmented Generation (RAG) systems, most retrieval methodologies are often developed for factual retrieval, which assumes query and positive documents are semantically similar. In this paper, we instead propose and study a more challenging type of retrieval task, called hidden rationale retrieval, in which query and document are not similar but can be inferred by reasoning chains, logic relationships, or empirical experiences. To address such problems, an instruction-tuned Large language model (LLM) with a cross-encoder architecture could be a reasonable choice. To further strengthen pioneering LLM-based retrievers, we design a special instruction that transforms the retrieval task into a generative task by prompting LLM to answer a binary-choice question. The model can be fine-tuned with direct preference optimization (DPO). The framework is also optimized for computational efficiency with no performance degradation. We name this retrieval framework by RaHoRe and verify its zero-shot and fine-tuned performance superiority on Emotional Support Conversation (ESC), compared with previous retrieval works. Our study suggests the potential to employ LLM as a foundation for a wider scope of retrieval tasks. Our codes, models, and datasets are available on https://github.com/flyfree5/LaHoRe.
Multi-Party Supervised Fine-tuning of Language Models for Multi-Party Dialogue Generation
Dec 06, 2024Large Language Models (LLM) are usually fine-tuned to participate in dyadic or two-party dialogues, which can not adapt well to multi-party dialogues (MPD), which hinders their applications in such scenarios including multi-personal meetings, discussions and daily communication. Previous LLM-based researches mainly focus on the multi-agent framework, while their base LLMs are still pairwisely fine-tuned. In this work, we design a multi-party fine-tuning framework (MuPaS) for LLMs on the multi-party dialogue datasets, and prove such a straightforward framework can let the LLM align with the multi-party conversation style efficiently and effectively. We also design two training strategies which can convert MuPaS into the MPD simulator. Substantial experiments show that MuPaS can achieve state-of-the-art multi-party response, higher accuracy of the-next-speaker prediction, higher human and automatic evaluated utterance qualities, and can even generate reasonably with out-of-distribution scene, topic and role descriptions. The MuPaS framework bridges the LLM training with more complicated multi-party applications, such as conversation generation, virtual rehearsal or meta-universe.
Dual-Layer Training and Decoding of Large Language Model with Simultaneously Thinking and Speaking
Sep 18, 2024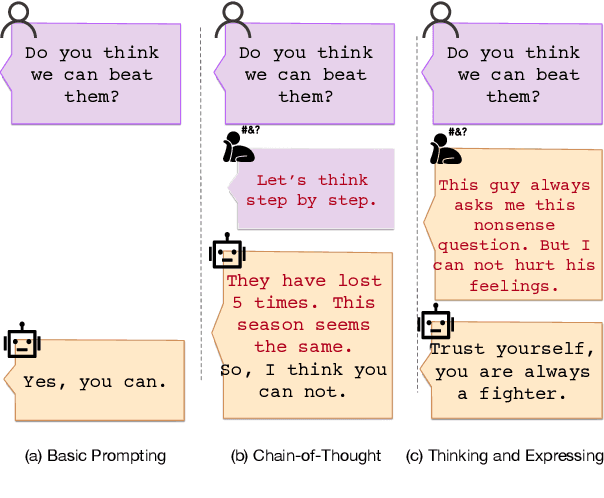



Large Language Model can reasonably understand and generate human expressions but may lack of thorough thinking and reasoning mechanisms. Recently there have been several studies which enhance the thinking ability of language models but most of them are not data-driven or training-based. In this paper, we are motivated by the cognitive mechanism in the natural world, and design a novel model architecture called TaS which allows it to first consider the thoughts and then express the response based upon the query. We design several pipelines to annotate or generate the thought contents from prompt-response samples, then add language heads in a middle layer which behaves as the thinking layer. We train the language model by the thoughts-augmented data and successfully let the thinking layer automatically generate reasonable thoughts and finally output more reasonable responses. Both qualitative examples and quantitative results validate the effectiveness and performance of TaS. Our code is available at https://anonymous.4open.science/r/TadE.