 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDream to Chat: Model-based Reinforcement Learning on Dialogues with User Belief Modeling
Aug 23, 2025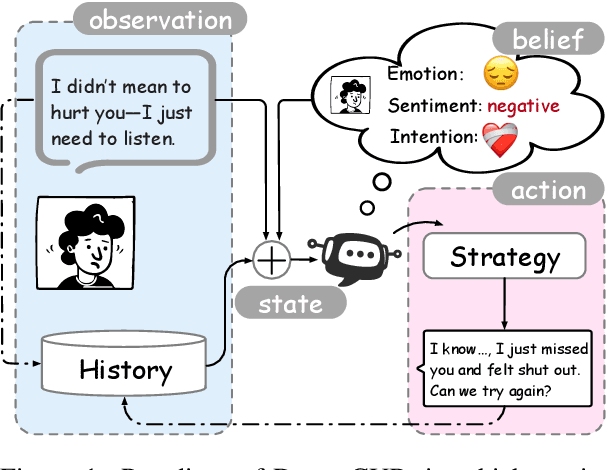
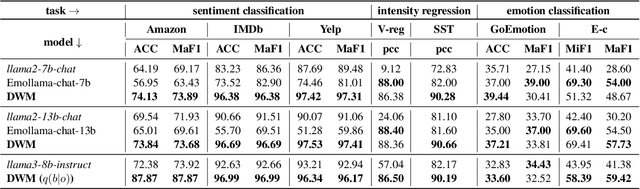
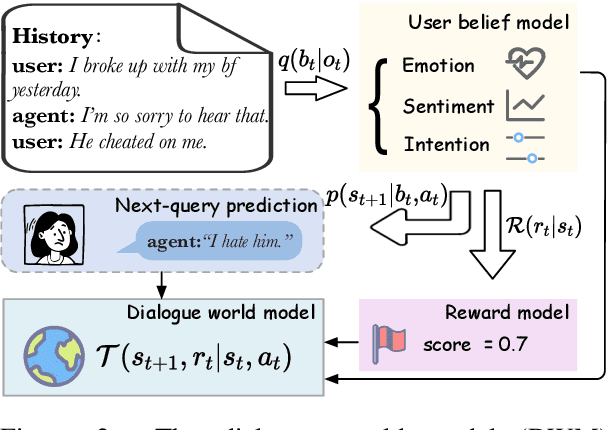
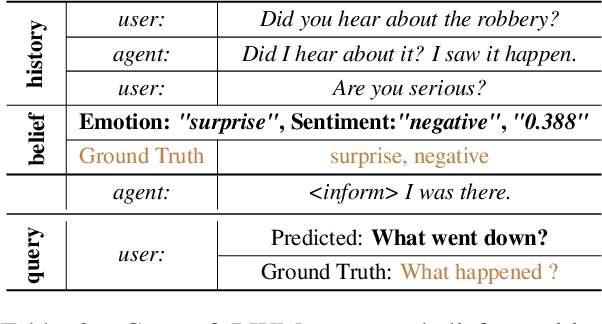
World models have been widely utilized in robotics, gaming, and auto-driving. However, their applications on natural language tasks are relatively limited. In this paper, we construct the dialogue world model, which could predict the user's emotion, sentiment, and intention, and future utterances. By defining a POMDP, we argue emotion, sentiment and intention can be modeled as the user belief and solved by maximizing the information bottleneck. By this user belief modeling, we apply the model-based reinforcement learning framework to the dialogue system, and propose a framework called DreamCUB. Experiments show that the pretrained dialogue world model can achieve state-of-the-art performances on emotion classification and sentiment identification, while dialogue quality is also enhanced by joint training of the policy, critic and dialogue world model. Further analysis shows that this manner holds a reasonable exploration-exploitation balance and also transfers well to out-of-domain scenarios such as empathetic dialogues.
Dual-Layer Training and Decoding of Large Language Model with Simultaneously Thinking and Speaking
Sep 18, 2024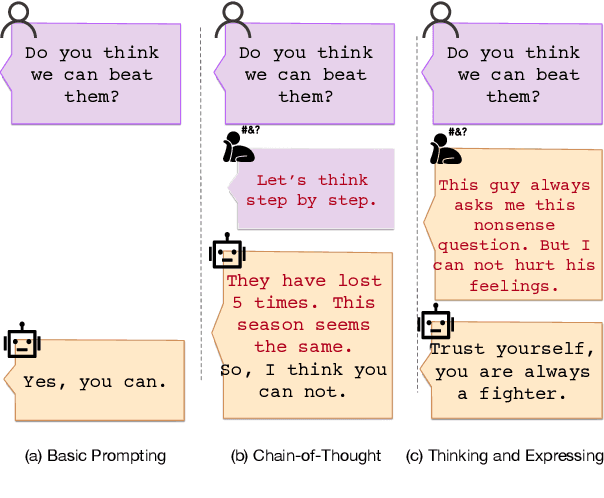



Large Language Model can reasonably understand and generate human expressions but may lack of thorough thinking and reasoning mechanisms. Recently there have been several studies which enhance the thinking ability of language models but most of them are not data-driven or training-based. In this paper, we are motivated by the cognitive mechanism in the natural world, and design a novel model architecture called TaS which allows it to first consider the thoughts and then express the response based upon the query. We design several pipelines to annotate or generate the thought contents from prompt-response samples, then add language heads in a middle layer which behaves as the thinking layer. We train the language model by the thoughts-augmented data and successfully let the thinking layer automatically generate reasonable thoughts and finally output more reasonable responses. Both qualitative examples and quantitative results validate the effectiveness and performance of TaS. Our code is available at https://anonymous.4open.science/r/TadE.
A Practice of Post-Training on Llama-3 70B with Optimal Selection of Additional Language Mixture Ratio
Sep 10, 2024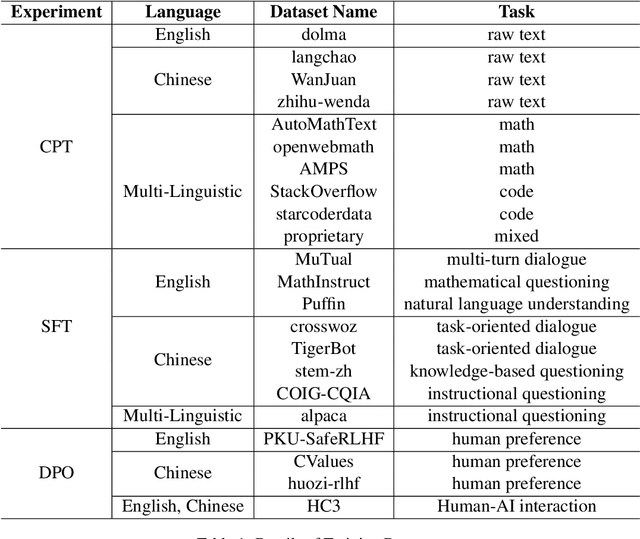
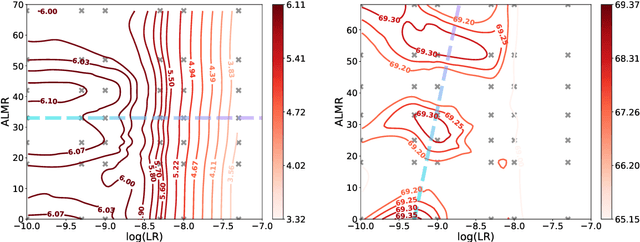
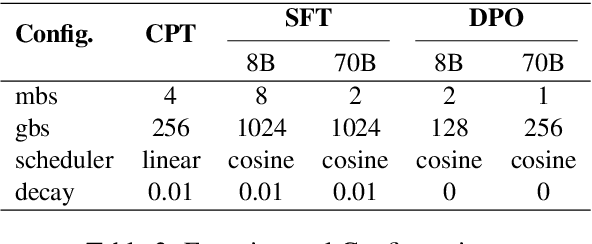
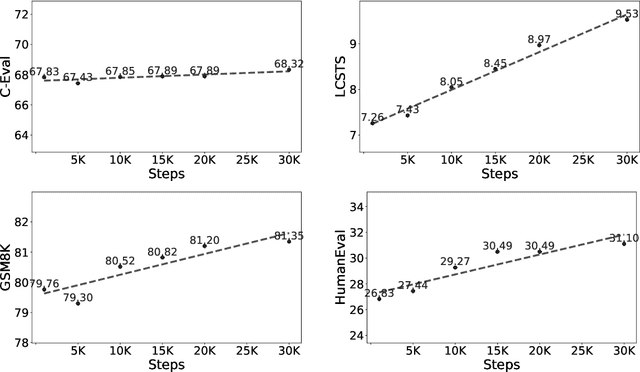
Large Language Models (LLM) often needs to be Continual Pre-Trained (CPT) to obtain the unfamiliar language skill or adapt into new domains. The huge training cost of CPT often asks for cautious choice of key hyper-parameters such as the mixture ratio of extra language or domain corpus. However, there is no systematic study which bridge the gap between the optimal mixture ratio and the actual model performance, and the gap between experimental scaling law and the actual deployment in the full model size. In this paper, we perform CPT on Llama-3 8B and 70B to enhance its Chinese ability. We study the optimal correlation between the Additional Language Mixture Ratio (ALMR) and the Learning Rate (LR) on the 8B size which directly indicate the optimal experimental set up. By thorough choice of hyper-parameter, and subsequent fine-tuning, the model capability is improved not only on the Chinese-related benchmark, but also some specific domains including math, coding and emotional intelligence. We deploy the final 70B version of LLM on an real-life chat system which obtain satisfying performance.