 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDream to Chat: Model-based Reinforcement Learning on Dialogues with User Belief Modeling
Aug 23, 2025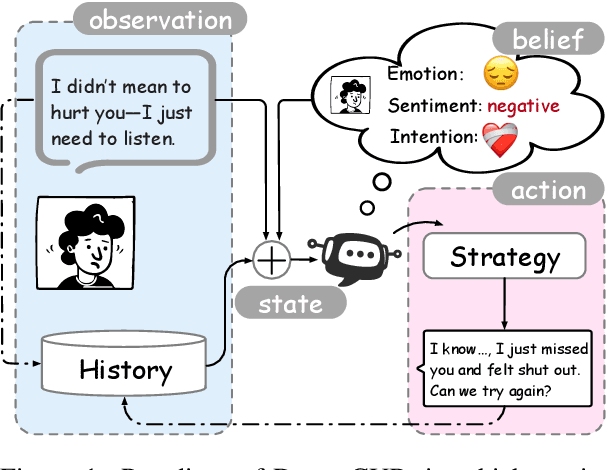
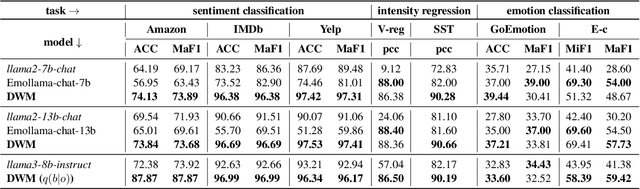
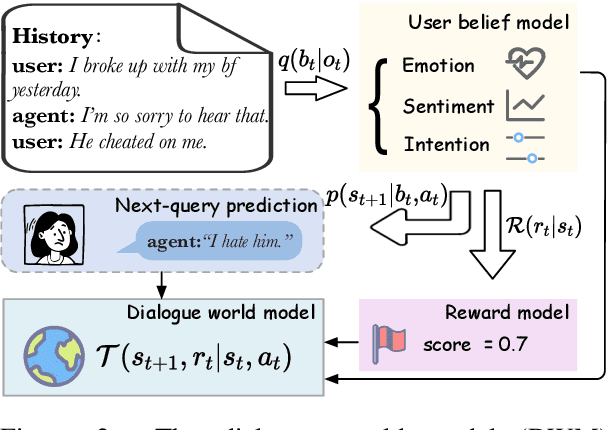
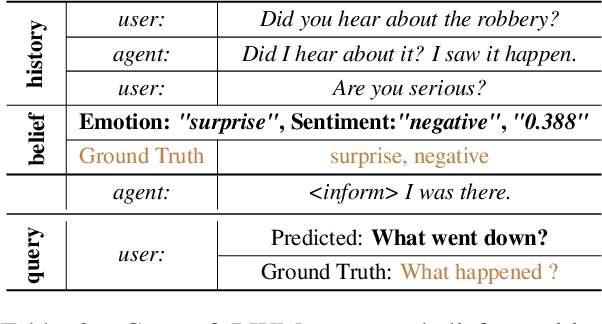
World models have been widely utilized in robotics, gaming, and auto-driving. However, their applications on natural language tasks are relatively limited. In this paper, we construct the dialogue world model, which could predict the user's emotion, sentiment, and intention, and future utterances. By defining a POMDP, we argue emotion, sentiment and intention can be modeled as the user belief and solved by maximizing the information bottleneck. By this user belief modeling, we apply the model-based reinforcement learning framework to the dialogue system, and propose a framework called DreamCUB. Experiments show that the pretrained dialogue world model can achieve state-of-the-art performances on emotion classification and sentiment identification, while dialogue quality is also enhanced by joint training of the policy, critic and dialogue world model. Further analysis shows that this manner holds a reasonable exploration-exploitation balance and also transfers well to out-of-domain scenarios such as empathetic dialogues.
Large Language Model Can Be a Foundation for Hidden Rationale-Based Retrieval
Dec 21, 2024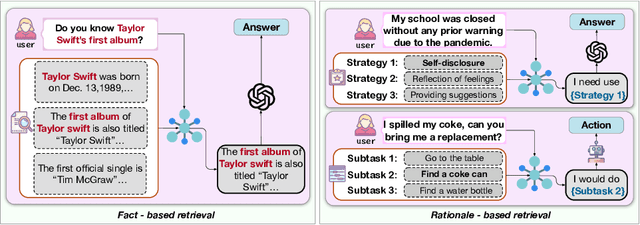
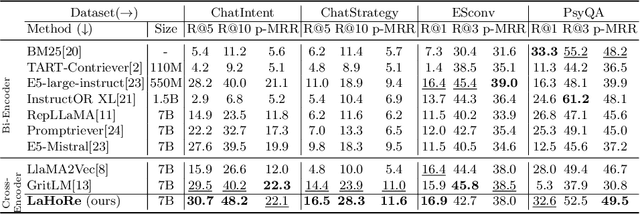
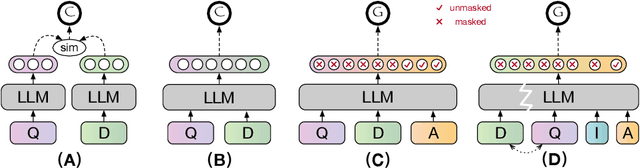
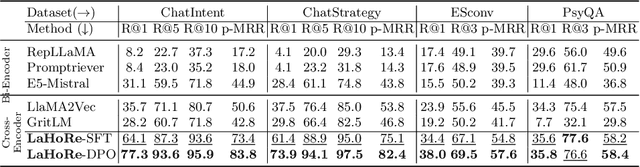
Despite the recent advancement in Retrieval-Augmented Generation (RAG) systems, most retrieval methodologies are often developed for factual retrieval, which assumes query and positive documents are semantically similar. In this paper, we instead propose and study a more challenging type of retrieval task, called hidden rationale retrieval, in which query and document are not similar but can be inferred by reasoning chains, logic relationships, or empirical experiences. To address such problems, an instruction-tuned Large language model (LLM) with a cross-encoder architecture could be a reasonable choice. To further strengthen pioneering LLM-based retrievers, we design a special instruction that transforms the retrieval task into a generative task by prompting LLM to answer a binary-choice question. The model can be fine-tuned with direct preference optimization (DPO). The framework is also optimized for computational efficiency with no performance degradation. We name this retrieval framework by RaHoRe and verify its zero-shot and fine-tuned performance superiority on Emotional Support Conversation (ESC), compared with previous retrieval works. Our study suggests the potential to employ LLM as a foundation for a wider scope of retrieval tasks. Our codes, models, and datasets are available on https://github.com/flyfree5/LaHoRe.
Multi-Party Supervised Fine-tuning of Language Models for Multi-Party Dialogue Generation
Dec 06, 2024Large Language Models (LLM) are usually fine-tuned to participate in dyadic or two-party dialogues, which can not adapt well to multi-party dialogues (MPD), which hinders their applications in such scenarios including multi-personal meetings, discussions and daily communication. Previous LLM-based researches mainly focus on the multi-agent framework, while their base LLMs are still pairwisely fine-tuned. In this work, we design a multi-party fine-tuning framework (MuPaS) for LLMs on the multi-party dialogue datasets, and prove such a straightforward framework can let the LLM align with the multi-party conversation style efficiently and effectively. We also design two training strategies which can convert MuPaS into the MPD simulator. Substantial experiments show that MuPaS can achieve state-of-the-art multi-party response, higher accuracy of the-next-speaker prediction, higher human and automatic evaluated utterance qualities, and can even generate reasonably with out-of-distribution scene, topic and role descriptions. The MuPaS framework bridges the LLM training with more complicated multi-party applications, such as conversation generation, virtual rehearsal or meta-universe.
Dual-Layer Training and Decoding of Large Language Model with Simultaneously Thinking and Speaking
Sep 18, 2024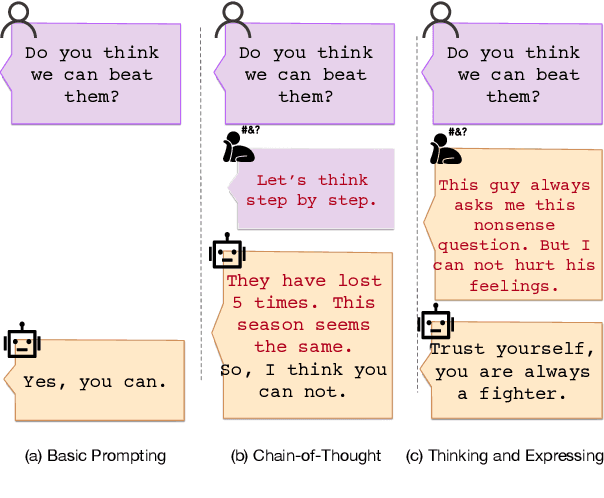



Large Language Model can reasonably understand and generate human expressions but may lack of thorough thinking and reasoning mechanisms. Recently there have been several studies which enhance the thinking ability of language models but most of them are not data-driven or training-based. In this paper, we are motivated by the cognitive mechanism in the natural world, and design a novel model architecture called TaS which allows it to first consider the thoughts and then express the response based upon the query. We design several pipelines to annotate or generate the thought contents from prompt-response samples, then add language heads in a middle layer which behaves as the thinking layer. We train the language model by the thoughts-augmented data and successfully let the thinking layer automatically generate reasonable thoughts and finally output more reasonable responses. Both qualitative examples and quantitative results validate the effectiveness and performance of TaS. Our code is available at https://anonymous.4open.science/r/TadE.
Alleviating Hallucinations in Large Language Models with Scepticism Modeling
Sep 10, 2024



Hallucinations is a major challenge for large language models (LLMs), prevents adoption in diverse fields. Uncertainty estimation could be used for alleviating the damages of hallucinations. The skeptical emotion of human could be useful for enhancing the ability of self estimation. Inspirited by this observation, we proposed a new approach called Skepticism Modeling (SM). This approach is formalized by combining the information of token and logits for self estimation. We construct the doubt emotion aware data, perform continual pre-training, and then fine-tune the LLMs, improve their ability of self estimation. Experimental results demonstrate this new approach effectively enhances a model's ability to estimate their uncertainty, and validate its generalization ability of other tasks by out-of-domain experiments.
A Practice of Post-Training on Llama-3 70B with Optimal Selection of Additional Language Mixture Ratio
Sep 10, 2024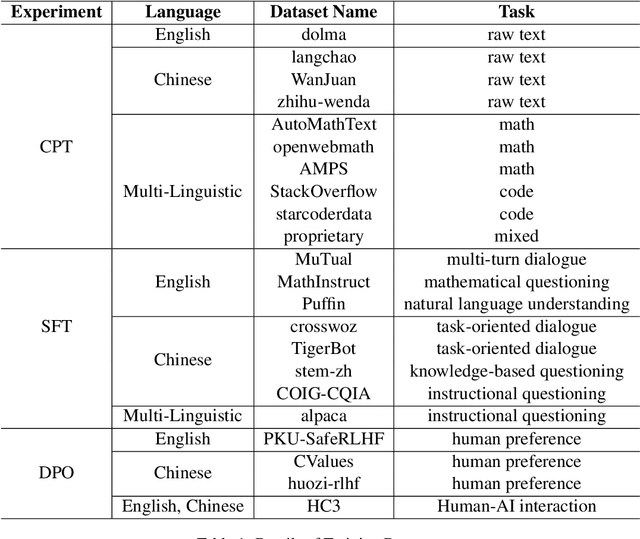
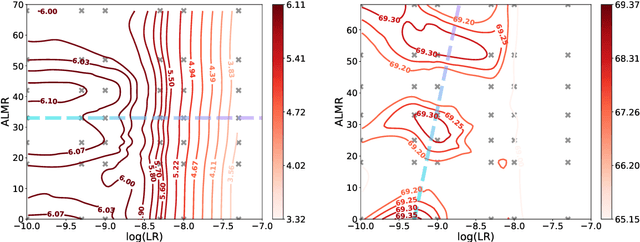
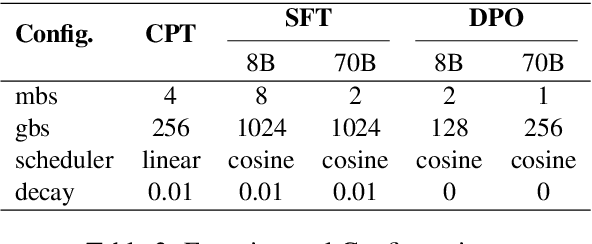
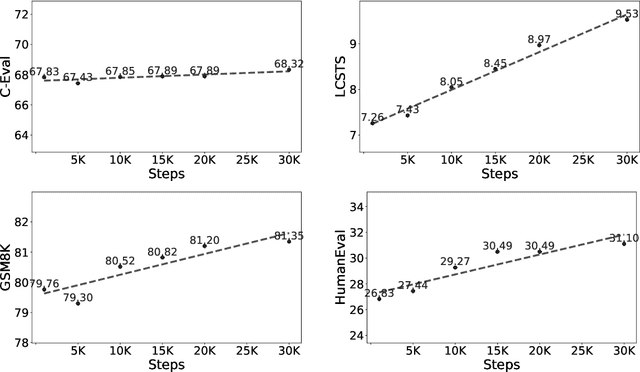
Large Language Models (LLM) often needs to be Continual Pre-Trained (CPT) to obtain the unfamiliar language skill or adapt into new domains. The huge training cost of CPT often asks for cautious choice of key hyper-parameters such as the mixture ratio of extra language or domain corpus. However, there is no systematic study which bridge the gap between the optimal mixture ratio and the actual model performance, and the gap between experimental scaling law and the actual deployment in the full model size. In this paper, we perform CPT on Llama-3 8B and 70B to enhance its Chinese ability. We study the optimal correlation between the Additional Language Mixture Ratio (ALMR) and the Learning Rate (LR) on the 8B size which directly indicate the optimal experimental set up. By thorough choice of hyper-parameter, and subsequent fine-tuning, the model capability is improved not only on the Chinese-related benchmark, but also some specific domains including math, coding and emotional intelligence. We deploy the final 70B version of LLM on an real-life chat system which obtain satisfying performance.