 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuadrature-TreeSHAP: Depth-Independent TreeSHAP and Shapley Interactions
May 06, 2026Shapley values are a standard tool for explaining predictions of tree ensembles, with Path-Dependent SHAP being the most widely used variant. Despite substantial progress, existing methods still exhibit trade-offs between depth-dependent runtime, numerical stability, and support for higher-order interactions. To address these challenges, we introduce Quadrature-TreeSHAP, a quadrature-based reformulation of Path-Dependent TreeSHAP that is numerically stable, naturally extends to any-order Shapley interaction values and is practically insensitive to tree depth. Our implementation supports both CPU and GPU and is integrated into XGBoost. Our method is based on a weighted-Banzhaf interaction polynomial, which expresses Banzhaf interaction values as expectations under a feature participation probability $p$. Shapley values and any-order interaction values are then recovered by integrating these polynomials over $p$ from 0 to 1. We evaluate these integrals using Gauss-Legendre quadrature, and show that, in practice, only 8 fixed quadrature points are sufficient to reach machine precision. In fact, Quadrature-TreeSHAP with 8 fixed points achieves greater numerical stability than TreeSHAP. This fixed-point formulation removes depth dependence from the inner computation and enables efficient SIMD execution. We confirm these advantages empirically. On 12 XGBoost benchmarks, Quadrature-TreeSHAP computes Shapley values 1.06x-10.59x faster than TreeSHAP on CPU and 1.84x-6.95x faster than GPUTreeSHAP on GPU. Shapley pairwise interactions are 3.80x-58.11x faster on CPU, with higher-order interactions achieving speedups of up to 1200x compared to TreeSHAP-IQ.
STEM: Structure-Tracing Evidence Mining for Knowledge Graphs-Driven Retrieval-Augmented Generation
Apr 24, 2026Knowledge Graph-based Question Answering (KGQA) plays a pivotal role in complex reasoning tasks but remains constrained by two persistent challenges: the structural heterogeneity of Knowledge Graphs(KGs) often leads to semantic mismatch during retrieval, while existing reasoning path retrieval methods lack a global structural perspective. To address these issues, we propose Structure-Tracing Evidence Mining (STEM), a novel framework that reframes multi-hop reasoning as a schema-guided graph search task. First, we design a Semantic-to-Structural Projection pipeline that leverages KG structural priors to decompose queries into atomic relational assertions and construct an adaptive query schema graph. Subsequently, we execute globally-aware node anchoring and subgraph retrieval to obtain the final evidence reasoning graph from KG. To more effectively integrate global structural information during the graph construction process, we design a Triple-Dependent GNN (Triple-GNN) to generate a Global Guidance Subgraph (Guidance Graph) that guides the construction. STEM significantly improves both the accuracy and evidence completeness of multi-hop reasoning graph retrieval, and achieves State-of-the-Art performance on multiple multi-hop benchmarks.
Shape-Interpretable Visual Self-Modeling Enables Geometry-Aware Continuum Robot Control
Mar 02, 2026Continuum robots possess high flexibility and redundancy, making them well suited for safe interaction in complex environments, yet their continuous deformation and nonlinear dynamics pose fundamental challenges to perception, modeling, and control. Existing vision-based control approaches often rely on end-to-end learning, achieving shape regulation without explicit awareness of robot geometry or its interaction with the environment. Here, we introduce a shape-interpretable visual self-modeling framework for continuum robots that enables geometry-aware control. Robot shapes are encoded from multi-view planar images using a Bezier-curve representation, transforming visual observations into a compact and physically meaningful shape space that uniquely characterizes the robot's three-dimensional configuration. Based on this representation, neural ordinary differential equations are employed to self-model both shape and end-effector dynamics directly from data, enabling hybrid shape-position control without analytical models or dense body markers. The explicit geometric structure of the learned shape space allows the robot to reason about its body and surroundings, supporting environment-aware behaviors such as obstacle avoidance and self-motion while maintaining end-effector objectives. Experiments on a cable-driven continuum robot demonstrate accurate shape-position regulation and tracking, with shape errors within 1.56% of image resolution and end-effector errors within 2% of robot length, as well as robust performance in constrained environments. By elevating visual shape representations from two-dimensional observations to an interpretable three-dimensional self-model, this work establishes a principled alternative to vision-based end-to-end control and advances autonomous, geometry-aware manipulation for continuum robots.
TeleBoost: A Systematic Alignment Framework for High-Fidelity, Controllable, and Robust Video Generation
Feb 07, 2026Post-training is the decisive step for converting a pretrained video generator into a production-oriented model that is instruction-following, controllable, and robust over long temporal horizons. This report presents a systematical post-training framework that organizes supervised policy shaping, reward-driven reinforcement learning, and preference-based refinement into a single stability-constrained optimization stack. The framework is designed around practical video-generation constraints, including high rollout cost, temporally compounding failure modes, and feedback that is heterogeneous, uncertain, and often weakly discriminative. By treating optimization as a staged, diagnostic-driven process rather than a collection of isolated tricks, the report summarizes a cohesive recipe for improving perceptual fidelity, temporal coherence, and prompt adherence while preserving the controllability established at initialization. The resulting framework provides a clear blueprint for building scalable post-training pipelines that remain stable, extensible, and effective in real-world deployment settings.
Binary Split Categorical feature with Mean Absolute Error Criteria in CART
Nov 11, 2025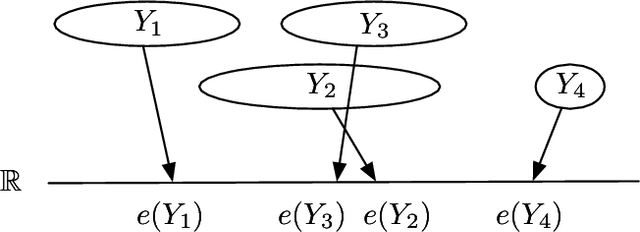


In the context of the Classification and Regression Trees (CART) algorithm, the efficient splitting of categorical features using standard criteria like GINI and Entropy is well-established. However, using the Mean Absolute Error (MAE) criterion for categorical features has traditionally relied on various numerical encoding methods. This paper demonstrates that unsupervised numerical encoding methods are not viable for the MAE criteria. Furthermore, we present a novel and efficient splitting algorithm that addresses the challenges of handling categorical features with the MAE criterion. Our findings underscore the limitations of existing approaches and offer a promising solution to enhance the handling of categorical data in CART algorithms.
QZhou-Embedding Technical Report
Aug 29, 2025We present QZhou-Embedding, a general-purpose contextual text embedding model with exceptional text representation capabilities. Built upon the Qwen2.5-7B-Instruct foundation model, we designed a unified multi-task framework comprising specialized data transformation and training strategies. The data transformation scheme enables the incorporation of more diverse textual training datasets, while the task-specific training strategies enhance model learning efficiency. We developed a data synthesis pipeline leveraging LLM API, incorporating techniques such as paraphrasing, augmentation, and hard negative example generation to improve the semantic richness and sample difficulty of the training set. Additionally, we employ a two-stage training strategy, comprising initial retrieval-focused pretraining followed by full-task fine-tuning, enabling the embedding model to extend its capabilities based on robust retrieval performance. Our model achieves state-of-the-art results on the MTEB and CMTEB benchmarks, ranking first on both leaderboards (August 27 2025), and simultaneously achieves state-of-the-art performance on tasks including reranking, clustering, etc. Our findings demonstrate that higher-quality, more diverse data is crucial for advancing retrieval model performance, and that leveraging LLMs generative capabilities can further optimize data quality for embedding model breakthroughs. Our model weights are released on HuggingFace under Apache 2.0 license. For reproducibility, we provide evaluation code and instructions on GitHub.
DinoCompanion: An Attachment-Theory Informed Multimodal Robot for Emotionally Responsive Child-AI Interaction
Jun 14, 2025Children's emotional development fundamentally relies on secure attachment relationships, yet current AI companions lack the theoretical foundation to provide developmentally appropriate emotional support. We introduce DinoCompanion, the first attachment-theory-grounded multimodal robot for emotionally responsive child-AI interaction. We address three critical challenges in child-AI systems: the absence of developmentally-informed AI architectures, the need to balance engagement with safety, and the lack of standardized evaluation frameworks for attachment-based capabilities. Our contributions include: (i) a multimodal dataset of 128 caregiver-child dyads containing 125,382 annotated clips with paired preference-risk labels, (ii) CARPO (Child-Aware Risk-calibrated Preference Optimization), a novel training objective that maximizes engagement while applying epistemic-uncertainty-weighted risk penalties, and (iii) AttachSecure-Bench, a comprehensive evaluation benchmark covering ten attachment-centric competencies with strong expert consensus (\k{appa}=0.81). DinoCompanion achieves state-of-the-art performance (57.15%), outperforming GPT-4o (50.29%) and Claude-3.7-Sonnet (53.43%), with exceptional secure base behaviors (72.99%, approaching human expert levels of 78.4%) and superior attachment risk detection (69.73%). Ablations validate the critical importance of multimodal fusion, uncertainty-aware risk modeling, and hierarchical memory for coherent, emotionally attuned interactions.
GORACS: Group-level Optimal Transport-guided Coreset Selection for LLM-based Recommender Systems
Jun 04, 2025Although large language models (LLMs) have shown great potential in recommender systems, the prohibitive computational costs for fine-tuning LLMs on entire datasets hinder their successful deployment in real-world scenarios. To develop affordable and effective LLM-based recommender systems, we focus on the task of coreset selection which identifies a small subset of fine-tuning data to optimize the test loss, thereby facilitating efficient LLMs' fine-tuning. Although there exist some intuitive solutions of subset selection, including distribution-based and importance-based approaches, they often lead to suboptimal performance due to the misalignment with downstream fine-tuning objectives or weak generalization ability caused by individual-level sample selection. To overcome these challenges, we propose GORACS, which is a novel Group-level Optimal tRAnsport-guided Coreset Selection framework for LLM-based recommender systems. GORACS is designed based on two key principles for coreset selection: 1) selecting the subsets that minimize the test loss to align with fine-tuning objectives, and 2) enhancing model generalization through group-level data selection. Corresponding to these two principles, GORACS has two key components: 1) a Proxy Optimization Objective (POO) leveraging optimal transport and gradient information to bound the intractable test loss, thus reducing computational costs by avoiding repeated LLM retraining, and 2) a two-stage Initialization-Then-Refinement Algorithm (ITRA) for efficient group-level selection. Our extensive experiments across diverse recommendation datasets and tasks validate that GORACS significantly reduces fine-tuning costs of LLMs while achieving superior performance over the state-of-the-art baselines and full data training. The source code of GORACS are available at https://github.com/Mithas-114/GORACS.
Self-Modeling Robots by Photographing
Mar 07, 2025



Self-modeling enables robots to build task-agnostic models of their morphology and kinematics based on data that can be automatically collected, with minimal human intervention and prior information, thereby enhancing machine intelligence. Recent research has highlighted the potential of data-driven technology in modeling the morphology and kinematics of robots. However, existing self-modeling methods suffer from either low modeling quality or excessive data acquisition costs. Beyond morphology and kinematics, texture is also a crucial component of robots, which is challenging to model and remains unexplored. In this work, a high-quality, texture-aware, and link-level method is proposed for robot self-modeling. We utilize three-dimensional (3D) Gaussians to represent the static morphology and texture of robots, and cluster the 3D Gaussians to construct neural ellipsoid bones, whose deformations are controlled by the transformation matrices generated by a kinematic neural network. The 3D Gaussians and kinematic neural network are trained using data pairs composed of joint angles, camera parameters and multi-view images without depth information. By feeding the kinematic neural network with joint angles, we can utilize the well-trained model to describe the corresponding morphology, kinematics and texture of robots at the link level, and render robot images from different perspectives with the aid of 3D Gaussian splatting. Furthermore, we demonstrate that the established model can be exploited to perform downstream tasks such as motion planning and inverse kinematics.
Towards a Unified Paradigm: Integrating Recommendation Systems as a New Language in Large Models
Dec 22, 2024



This paper explores the use of Large Language Models (LLMs) for sequential recommendation, which predicts users' future interactions based on their past behavior. We introduce a new concept, "Integrating Recommendation Systems as a New Language in Large Models" (RSLLM), which combines the strengths of traditional recommenders and LLMs. RSLLM uses a unique prompting method that combines ID-based item embeddings from conventional recommendation models with textual item features. It treats users' sequential behaviors as a distinct language and aligns the ID embeddings with the LLM's input space using a projector. We also propose a two-stage LLM fine-tuning framework that refines a pretrained LLM using a combination of two contrastive losses and a language modeling loss. The LLM is first fine-tuned using text-only prompts, followed by target domain fine-tuning with unified prompts. This trains the model to incorporate behavioral knowledge from the traditional sequential recommender into the LLM. Our empirical results validate the effectiveness of our proposed framework.