 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape-Interpretable Visual Self-Modeling Enables Geometry-Aware Continuum Robot Control
Mar 02, 2026Continuum robots possess high flexibility and redundancy, making them well suited for safe interaction in complex environments, yet their continuous deformation and nonlinear dynamics pose fundamental challenges to perception, modeling, and control. Existing vision-based control approaches often rely on end-to-end learning, achieving shape regulation without explicit awareness of robot geometry or its interaction with the environment. Here, we introduce a shape-interpretable visual self-modeling framework for continuum robots that enables geometry-aware control. Robot shapes are encoded from multi-view planar images using a Bezier-curve representation, transforming visual observations into a compact and physically meaningful shape space that uniquely characterizes the robot's three-dimensional configuration. Based on this representation, neural ordinary differential equations are employed to self-model both shape and end-effector dynamics directly from data, enabling hybrid shape-position control without analytical models or dense body markers. The explicit geometric structure of the learned shape space allows the robot to reason about its body and surroundings, supporting environment-aware behaviors such as obstacle avoidance and self-motion while maintaining end-effector objectives. Experiments on a cable-driven continuum robot demonstrate accurate shape-position regulation and tracking, with shape errors within 1.56% of image resolution and end-effector errors within 2% of robot length, as well as robust performance in constrained environments. By elevating visual shape representations from two-dimensional observations to an interpretable three-dimensional self-model, this work establishes a principled alternative to vision-based end-to-end control and advances autonomous, geometry-aware manipulation for continuum robots.
HybridGen: VLM-Guided Hybrid Planning for Scalable Data Generation of Imitation Learning
Mar 17, 2025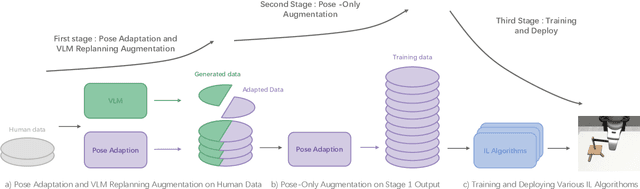
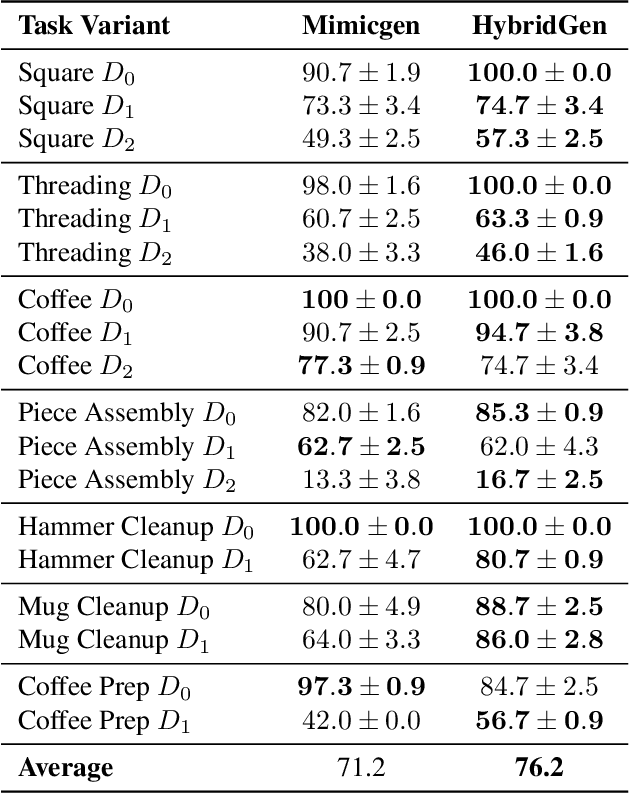
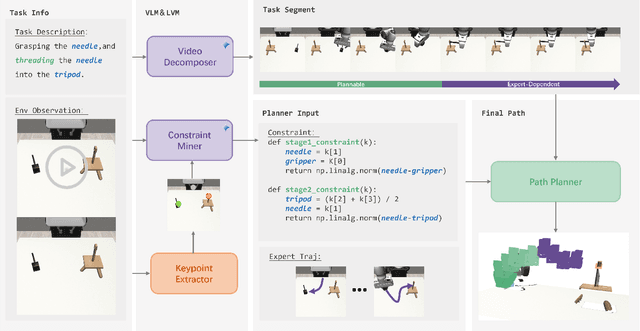
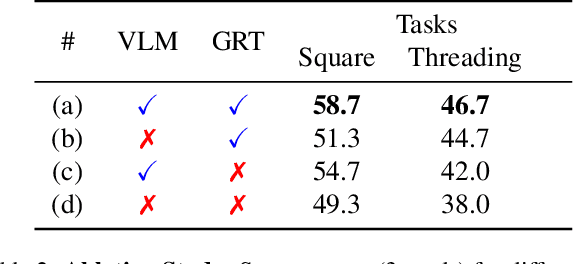
The acquisition of large-scale and diverse demonstration data are essential for improving robotic imitation learning generalization. However, generating such data for complex manipulations is challenging in real-world settings. We introduce HybridGen, an automated framework that integrates Vision-Language Model (VLM) and hybrid planning. HybridGen uses a two-stage pipeline: first, VLM to parse expert demonstrations, decomposing tasks into expert-dependent (object-centric pose transformations for precise control) and plannable segments (synthesizing diverse trajectories via path planning); second, pose transformations substantially expand the first-stage data. Crucially, HybridGen generates a large volume of training data without requiring specific data formats, making it broadly applicable to a wide range of imitation learning algorithms, a characteristic which we also demonstrate empirically across multiple algorithms. Evaluations across seven tasks and their variants demonstrate that agents trained with HybridGen achieve substantial performance and generalization gains, averaging a 5% improvement over state-of-the-art methods. Notably, in the most challenging task variants, HybridGen achieves significant improvement, reaching a 59.7% average success rate, significantly outperforming Mimicgen's 49.5%. These results demonstrating its effectiveness and practicality.
Self-Modeling Robots by Photographing
Mar 07, 2025



Self-modeling enables robots to build task-agnostic models of their morphology and kinematics based on data that can be automatically collected, with minimal human intervention and prior information, thereby enhancing machine intelligence. Recent research has highlighted the potential of data-driven technology in modeling the morphology and kinematics of robots. However, existing self-modeling methods suffer from either low modeling quality or excessive data acquisition costs. Beyond morphology and kinematics, texture is also a crucial component of robots, which is challenging to model and remains unexplored. In this work, a high-quality, texture-aware, and link-level method is proposed for robot self-modeling. We utilize three-dimensional (3D) Gaussians to represent the static morphology and texture of robots, and cluster the 3D Gaussians to construct neural ellipsoid bones, whose deformations are controlled by the transformation matrices generated by a kinematic neural network. The 3D Gaussians and kinematic neural network are trained using data pairs composed of joint angles, camera parameters and multi-view images without depth information. By feeding the kinematic neural network with joint angles, we can utilize the well-trained model to describe the corresponding morphology, kinematics and texture of robots at the link level, and render robot images from different perspectives with the aid of 3D Gaussian splatting. Furthermore, we demonstrate that the established model can be exploited to perform downstream tasks such as motion planning and inverse kinematics.
Causality-Based Reinforcement Learning Method for Multi-Stage Robotic Tasks
Mar 05, 2025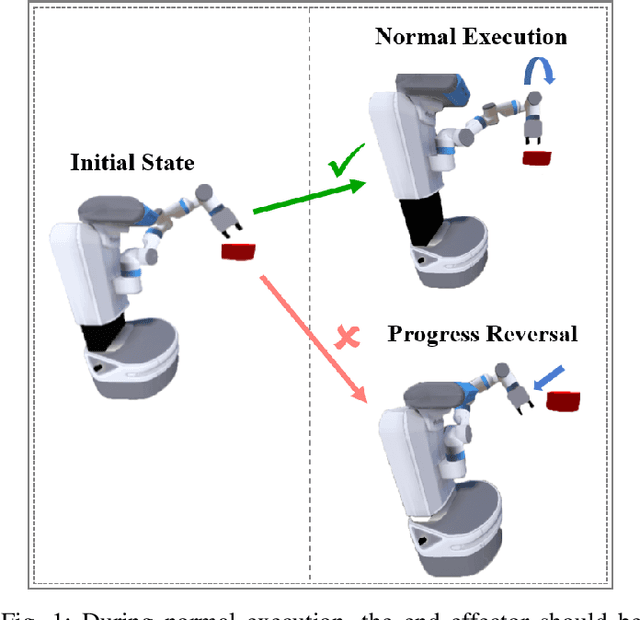
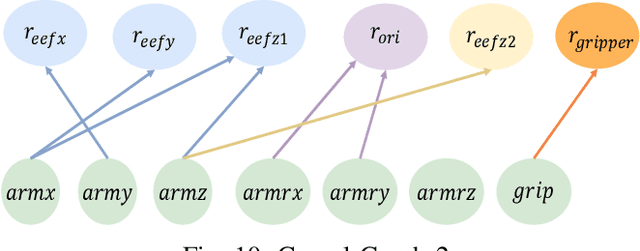
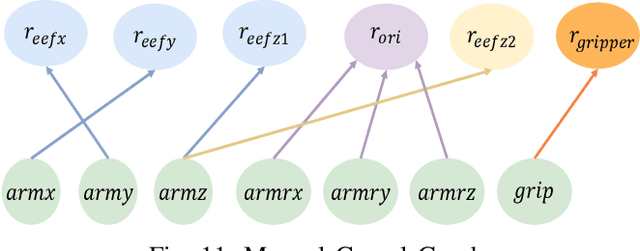
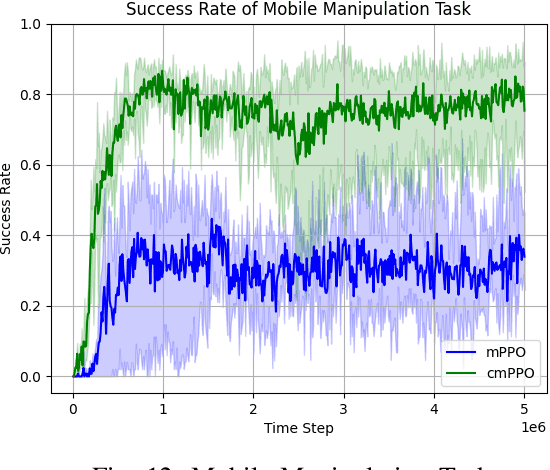
Deep reinforcement learning has made significant strides in various robotic tasks. However, employing deep reinforcement learning methods to tackle multi-stage tasks still a challenge. Reinforcement learning algorithms often encounter issues such as redundant exploration, getting stuck in dead ends, and progress reversal in multi-stage tasks. To address this, we propose a method that integrates causal relationships with reinforcement learning for multi-stage tasks. Our approach enables robots to automatically discover the causal relationships between their actions and the rewards of the tasks and constructs the action space using only causal actions, thereby reducing redundant exploration and progress reversal. By integrating correct causal relationships using the causal policy gradient method into the learning process, our approach can enhance the performance of reinforcement learning algorithms in multi-stage robotic tasks.
Retinal Vessels Segmentation Based on Dilated Multi-Scale Convolutional Neural Network
Apr 11, 2019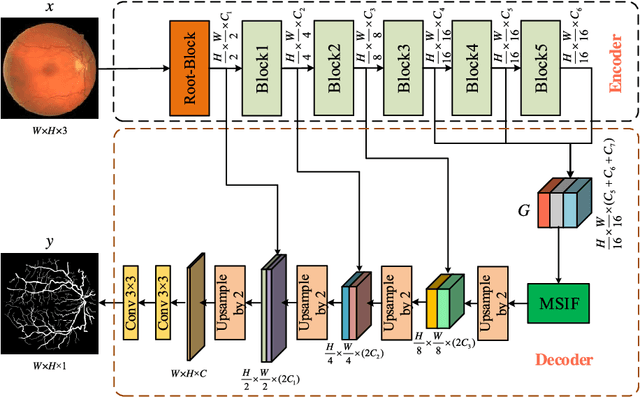

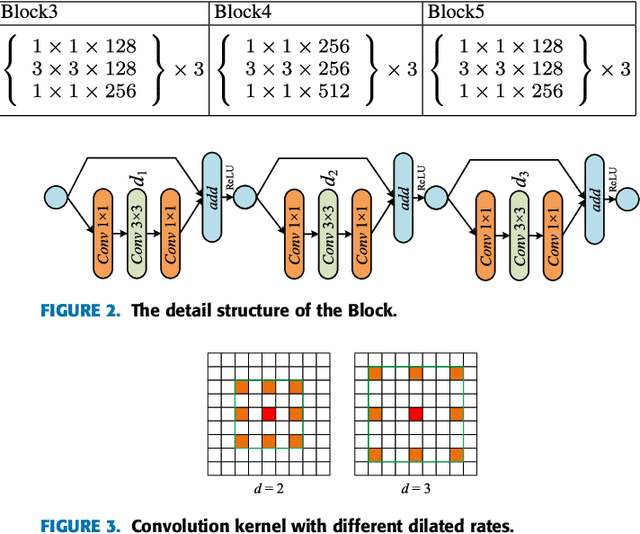
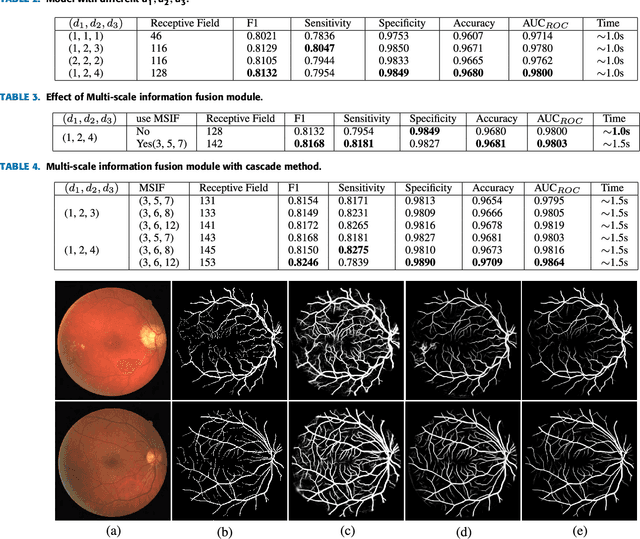
Accurate segmentation of retinal vessels is a basic step in Diabetic retinopathy(DR) detection. Most methods based on deep convolutional neural network (DCNN) have small receptive fields, and hence they are unable to capture global context information of larger regions, with difficult to identify lesions. The final segmented retina vessels contain more noise with low classification accuracy. Therefore, in this paper, we propose a DCNN structure named as D-Net. In the proposed D-Net, the dilation convolution is used in the backbone network to obtain a larger receptive field without losing spatial resolution, so as to reduce the loss of feature information and to reduce the difficulty of tiny thin vessels segmentation. The large receptive field can better distinguished between the lesion area and the blood vessel area. In the proposed Multi-Scale Information Fusion module (MSIF), parallel convolution layers with different dilation rates are used, so that the model can obtain more dense feature information and better capture retinal vessel information of different sizes. In the decoding module, the skip layer connection is used to propagate context information to higher resolution layers, so as to prevent low-level information from passing the entire network structure. Finally, our method was verified on DRIVE, STARE and CHASE dataset. The experimental results show that our network structure outperforms some state-of-art method, such as N4-fields, U-Net, and DRIU in terms of accuracy, sensitivity, specificity, and AUCROC. Particularly, D-Net outperforms U-Net by 1.04%, 1.23% and 2.79% in DRIVE, STARE, and CHASE three dataset, respectively.
Retinal Vessel Segmentation Based on Conditional Deep Convolutional Generative Adversarial Networks
May 11, 2018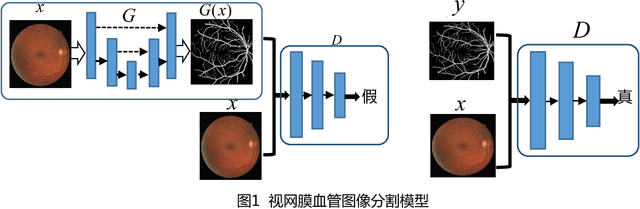
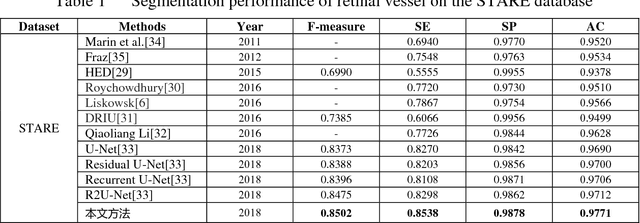
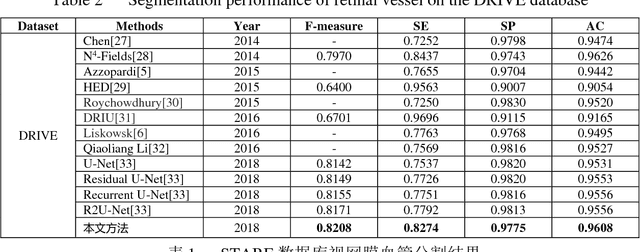
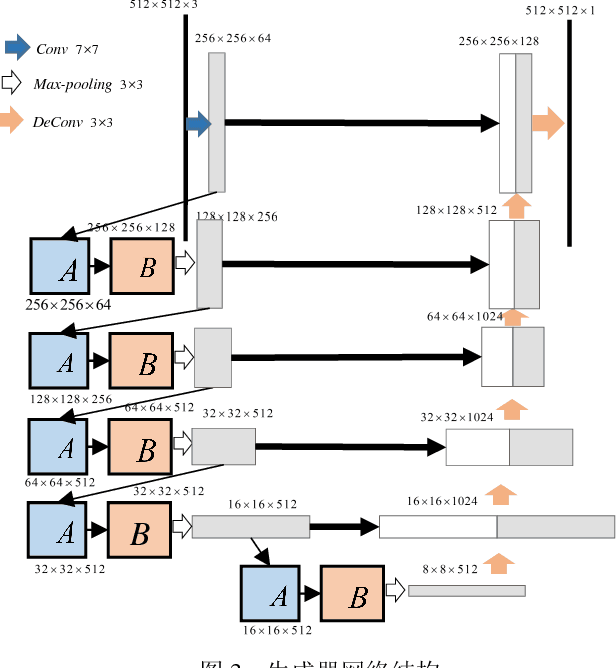
The segmentation of retinal vessels is of significance for doctors to diagnose the fundus diseases. However, existing methods have various problems in the segmentation of the retinal vessels, such as insufficient segmentation of retinal vessels, weak anti-noise interference ability, and sensitivity to lesions, etc. Aiming to the shortcomings of existed methods, this paper proposes the use of conditional deep convolutional generative adversarial networks to segment the retinal vessels. We mainly improve the network structure of the generator. The introduction of the residual module at the convolutional layer for residual learning makes the network structure sensitive to changes in the output, as to better adjust the weight of the generator. In order to reduce the number of parameters and calculations, using a small convolution to halve the number of channels in the input signature before using a large convolution kernel. By used skip connection to connect the output of the convolutional layer with the output of the deconvolution layer to avoid low-level information sharing. By verifying the method on the DRIVE and STARE datasets, the segmentation accuracy rate is 96.08% and 97.71%, the sensitivity reaches 82.74% and 85.34% respectively, and the F-measure reaches 82.08% and 85.02% respectively. The sensitivity is 4.82% and 2.4% higher than that of R2U-Net.