 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybridGen: VLM-Guided Hybrid Planning for Scalable Data Generation of Imitation Learning
Paper and Code
Mar 17, 2025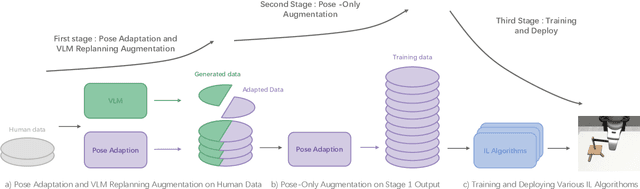
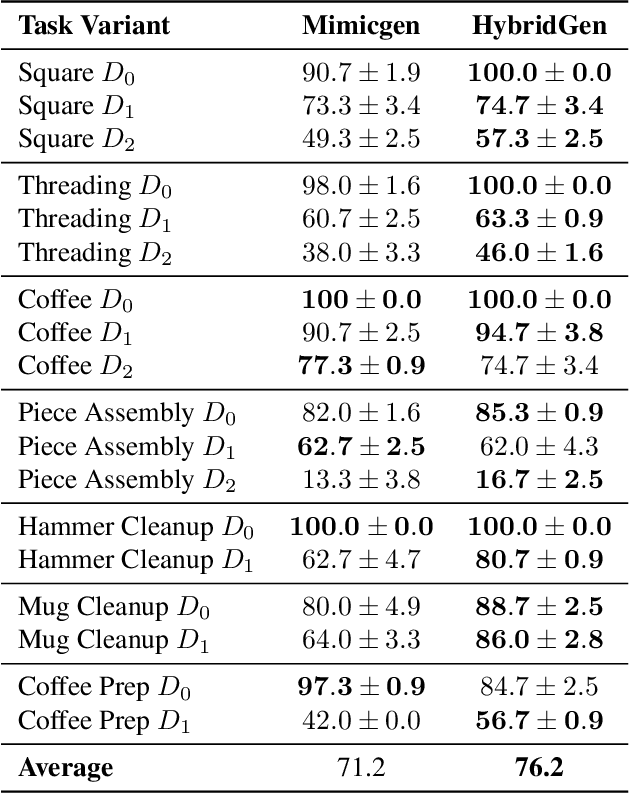
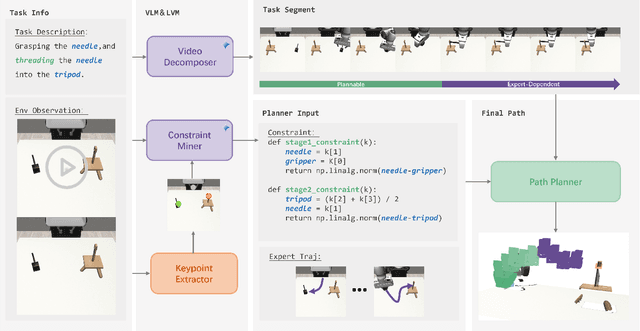
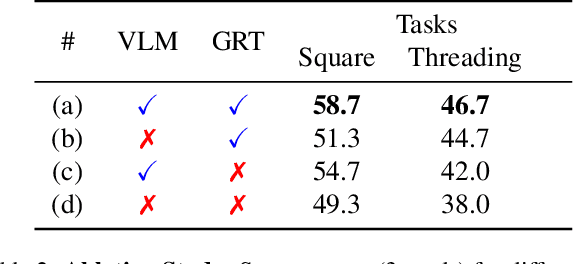
The acquisition of large-scale and diverse demonstration data are essential for improving robotic imitation learning generalization. However, generating such data for complex manipulations is challenging in real-world settings. We introduce HybridGen, an automated framework that integrates Vision-Language Model (VLM) and hybrid planning. HybridGen uses a two-stage pipeline: first, VLM to parse expert demonstrations, decomposing tasks into expert-dependent (object-centric pose transformations for precise control) and plannable segments (synthesizing diverse trajectories via path planning); second, pose transformations substantially expand the first-stage data. Crucially, HybridGen generates a large volume of training data without requiring specific data formats, making it broadly applicable to a wide range of imitation learning algorithms, a characteristic which we also demonstrate empirically across multiple algorithms. Evaluations across seven tasks and their variants demonstrate that agents trained with HybridGen achieve substantial performance and generalization gains, averaging a 5% improvement over state-of-the-art methods. Notably, in the most challenging task variants, HybridGen achieves significant improvement, reaching a 59.7% average success rate, significantly outperforming Mimicgen's 49.5%. These results demonstrating its effectiveness and practicality.