 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybridGen: VLM-Guided Hybrid Planning for Scalable Data Generation of Imitation Learning
Mar 17, 2025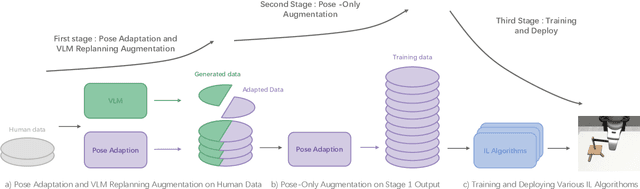
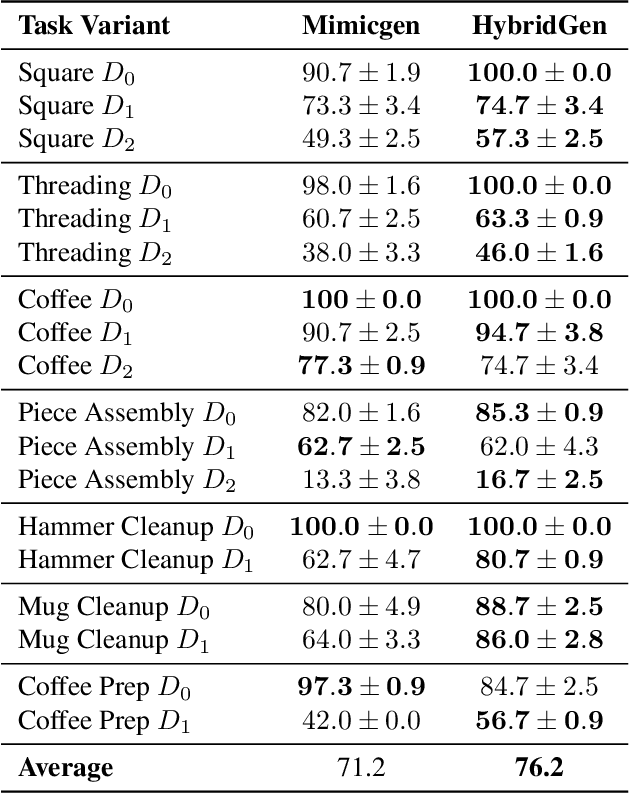
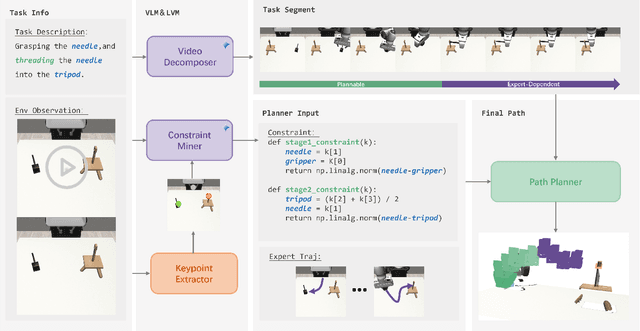
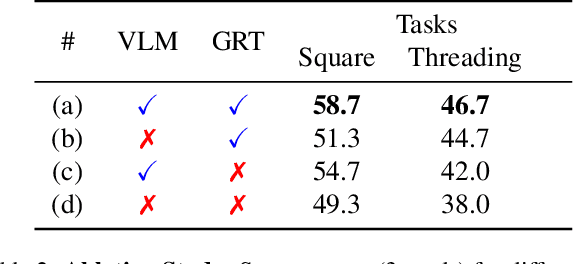
The acquisition of large-scale and diverse demonstration data are essential for improving robotic imitation learning generalization. However, generating such data for complex manipulations is challenging in real-world settings. We introduce HybridGen, an automated framework that integrates Vision-Language Model (VLM) and hybrid planning. HybridGen uses a two-stage pipeline: first, VLM to parse expert demonstrations, decomposing tasks into expert-dependent (object-centric pose transformations for precise control) and plannable segments (synthesizing diverse trajectories via path planning); second, pose transformations substantially expand the first-stage data. Crucially, HybridGen generates a large volume of training data without requiring specific data formats, making it broadly applicable to a wide range of imitation learning algorithms, a characteristic which we also demonstrate empirically across multiple algorithms. Evaluations across seven tasks and their variants demonstrate that agents trained with HybridGen achieve substantial performance and generalization gains, averaging a 5% improvement over state-of-the-art methods. Notably, in the most challenging task variants, HybridGen achieves significant improvement, reaching a 59.7% average success rate, significantly outperforming Mimicgen's 49.5%. These results demonstrating its effectiveness and practicality.
UVCPNet: A UAV-Vehicle Collaborative Perception Network for 3D Object Detection
Jun 07, 2024With the advancement of collaborative perception, the role of aerial-ground collaborative perception, a crucial component, is becoming increasingly important. The demand for collaborative perception across different perspectives to construct more comprehensive perceptual information is growing. However, challenges arise due to the disparities in the field of view between cross-domain agents and their varying sensitivity to information in images. Additionally, when we transform image features into Bird's Eye View (BEV) features for collaboration, we need accurate depth information. To address these issues, we propose a framework specifically designed for aerial-ground collaboration. First, to mitigate the lack of datasets for aerial-ground collaboration, we develop a virtual dataset named V2U-COO for our research. Second, we design a Cross-Domain Cross-Adaptation (CDCA) module to align the target information obtained from different domains, thereby achieving more accurate perception results. Finally, we introduce a Collaborative Depth Optimization (CDO) module to obtain more precise depth estimation results, leading to more accurate perception outcomes. We conduct extensive experiments on both our virtual dataset and a public dataset to validate the effectiveness of our framework. Our experiments on the V2U-COO dataset and the DAIR-V2X dataset demonstrate that our method improves detection accuracy by 6.1% and 2.7%, respectively.
A Real-time Low-cost Artificial Intelligence System for Autonomous Spraying in Palm Plantations
Mar 06, 2021



In precision crop protection, (target-orientated) object detection in image processing can help navigate Unmanned Aerial Vehicles (UAV, crop protection drones) to the right place to apply the pesticide. Unnecessary application of non-target areas could be avoided. Deep learning algorithms dominantly use in modern computer vision tasks which require high computing time, memory footprint, and power consumption. Based on the Edge Artificial Intelligence, we investigate the main three paths that lead to dealing with this problem, including hardware accelerators, efficient algorithms, and model compression. Finally, we integrate them and propose a solution based on a light deep neural network (DNN), called Ag-YOLO, which can make the crop protection UAV have the ability to target detection and autonomous operation. This solution is restricted in size, cost, flexible, fast, and energy-effective. The hardware is only 18 grams in weight and 1.5 watts in energy consumption, and the developed DNN model needs only 838 kilobytes of disc space. We tested the developed hardware and software in comparison to the tiny version of the state-of-art YOLOv3 framework, known as YOLOv3-Tiny to detect individual palm in a plantation. An average F1 score of 0.9205 at the speed of 36.5 frames per second (in comparison to similar accuracy at 18 frames per second and 8.66 megabytes of the YOLOv3-Tiny algorithm) was reached. This developed detection system is easily plugged into any machines already purchased as long as the machines have USB ports and run Linux Operating System.
Heterogeneous Memory Enhanced Multimodal Attention Model for Video Question Answering
Apr 08, 2019
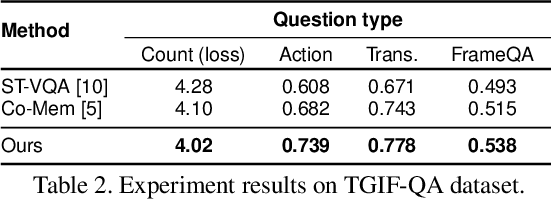
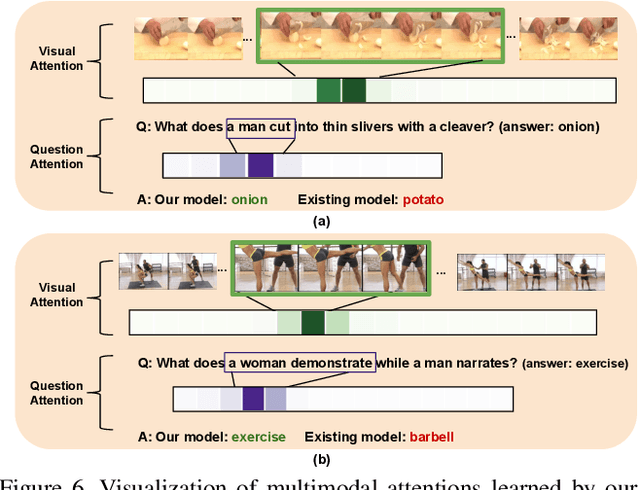
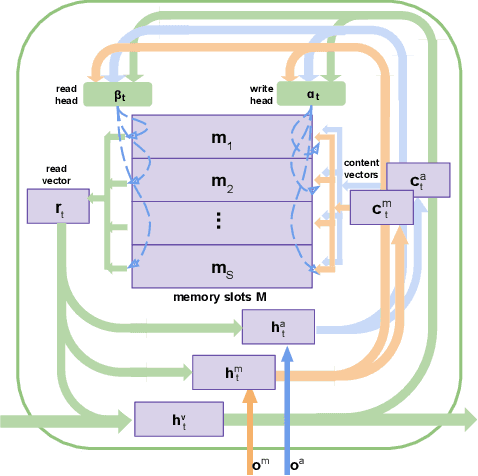
In this paper, we propose a novel end-to-end trainable Video Question Answering (VideoQA) framework with three major components: 1) a new heterogeneous memory which can effectively learn global context information from appearance and motion features; 2) a redesigned question memory which helps understand the complex semantics of question and highlights queried subjects; and 3) a new multimodal fusion layer which performs multi-step reasoning by attending to relevant visual and textual hints with self-updated attention. Our VideoQA model firstly generates the global context-aware visual and textual features respectively by interacting current inputs with memory contents. After that, it makes the attentional fusion of the multimodal visual and textual representations to infer the correct answer. Multiple cycles of reasoning can be made to iteratively refine attention weights of the multimodal data and improve the final representation of the QA pair. Experimental results demonstrate our approach achieves state-of-the-art performance on four VideoQA benchmark datasets.