 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Learning-based AEB with Massive Unlabeled Data
Jun 17, 2026This paper studies how to scale learning-based automatic emergency braking (AEB) with massive unlabeled fleet data under production constraints. Our approach is based on meta-feedback semi-supervised learning (MF-SSL), where a teacher generates pseudo labels for unlabeled driving data and is updated using a small labeled anchor set as safety-critical feedback. In production, anchor ambiguity and labeled-unlabeled mismatch can amplify systematic pseudo-label errors, leading to spurious triggers. We propose a stabilized MF-SSL framework with (i) Noise-Aware Decoupling, which removes ambiguity-prone anchors from the teacher's supervised update path, and (ii) kinematics-gated pseudo-labeling with a teacher conflict penalty to suppress mismatch-induced risk hallucinations on unlabeled data while maintaining broad coverage. Extensive experiments show consistent gains as unlabeled data scale from 1M to 1B windows, improving safety while keeping comfort stable. The 1B-trained student model is deployed to hundreds of thousands of vehicles and validated over \$10^9$ km of driving, achieving a positive-to-false activation ratio exceeding 100:1 and a 35% improvement in accident-free driving mileage over a production rule-only baseline.
Denoise and Align: Towards Source-Free UDA for Robust Panoramic Semantic Segmentation
Mar 26, 2026Panoramic semantic segmentation is pivotal for comprehensive 360° scene understanding in critical applications like autonomous driving and virtual reality. However, progress in this domain is constrained by two key challenges: the severe geometric distortions inherent in panoramic projections and the prohibitive cost of dense annotation. While Unsupervised Domain Adaptation (UDA) from label-rich pinhole-camera datasets offers a viable alternative, many real-world tasks impose a stricter source-free (SFUDA) constraint where source data is inaccessible for privacy or proprietary reasons. This constraint significantly amplifies the core problems of domain shift, leading to unreliable pseudo-labels and dramatic performance degradation, particularly for minority classes. To overcome these limitations, we propose the DAPASS framework. DAPASS introduces two synergistic modules to robustly transfer knowledge without source data. First, our Panoramic Confidence-Guided Denoising (PCGD) module generates high-fidelity, class-balanced pseudo-labels by enforcing perturbation consistency and incorporating neighborhood-level confidence to filter noise. Second, a Contextual Resolution Adversarial Module (CRAM) explicitly addresses scale variance and distortion by adversarially aligning fine-grained details from high-resolution crops with global semantics from low-resolution contexts. DAPASS achieves state-of-the-art performances on outdoor (Cityscapes-to-DensePASS) and indoor (Stanford2D3D) benchmarks, yielding 55.04% (+2.05%) and 70.38% (+1.54%) mIoU, respectively.
Explicitly Guided Information Interaction Network for Cross-modal Point Cloud Completion
Jul 03, 2024



Corresponding author}In this paper, we explore a novel framework, EGIInet (Explicitly Guided Information Interaction Network), a model for View-guided Point cloud Completion (ViPC) task, which aims to restore a complete point cloud from a partial one with a single view image. In comparison with previous methods that relied on the global semantics of input images, EGIInet efficiently combines the information from two modalities by leveraging the geometric nature of the completion task. Specifically, we propose an explicitly guided information interaction strategy supported by modal alignment for point cloud completion. First, in contrast to previous methods which simply use 2D and 3D backbones to encode features respectively, we unified the encoding process to promote modal alignment. Second, we propose a novel explicitly guided information interaction strategy that could help the network identify critical information within images, thus achieving better guidance for completion. Extensive experiments demonstrate the effectiveness of our framework, and we achieved a new state-of-the-art (+16\% CD over XMFnet) in benchmark datasets despite using fewer parameters than the previous methods. The pre-trained model and code and are available at https://github.com/WHU-USI3DV/EGIInet.
Class-incremental Learning for Time Series: Benchmark and Evaluation
Feb 19, 2024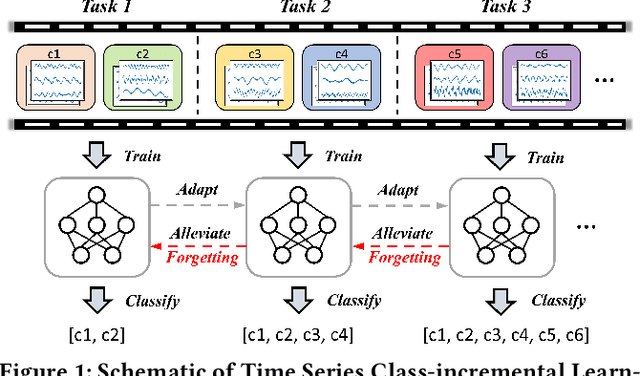
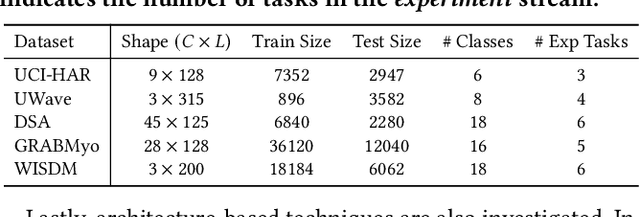
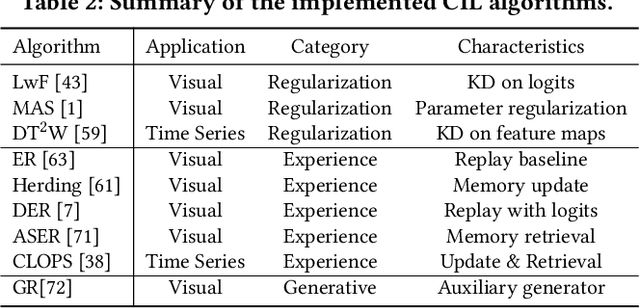
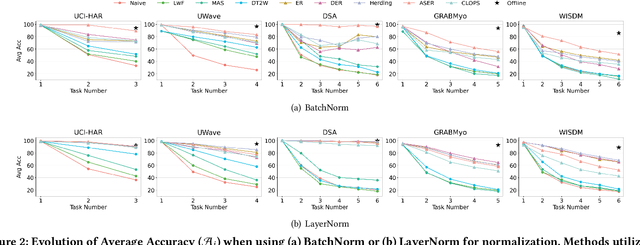
Real-world environments are inherently non-stationary, frequently introducing new classes over time. This is especially common in time series classification, such as the emergence of new disease classification in healthcare or the addition of new activities in human activity recognition. In such cases, a learning system is required to assimilate novel classes effectively while avoiding catastrophic forgetting of the old ones, which gives rise to the Class-incremental Learning (CIL) problem. However, despite the encouraging progress in the image and language domains, CIL for time series data remains relatively understudied. Existing studies suffer from inconsistent experimental designs, necessitating a comprehensive evaluation and benchmarking of methods across a wide range of datasets. To this end, we first present an overview of the Time Series Class-incremental Learning (TSCIL) problem, highlight its unique challenges, and cover the advanced methodologies. Further, based on standardized settings, we develop a unified experimental framework that supports the rapid development of new algorithms, easy integration of new datasets, and standardization of the evaluation process. Using this framework, we conduct a comprehensive evaluation of various generic and time-series-specific CIL methods in both standard and privacy-sensitive scenarios. Our extensive experiments not only provide a standard baseline to support future research but also shed light on the impact of various design factors such as normalization layers or memory budget thresholds. Codes are available at https://github.com/zqiao11/TSCIL.
SparseDC: Depth Completion from sparse and non-uniform inputs
Nov 30, 2023We propose SparseDC, a model for Depth Completion of Sparse and non-uniform depth inputs. Unlike previous methods focusing on completing fixed distributions on benchmark datasets (e.g., NYU with 500 points, KITTI with 64 lines), SparseDC is specifically designed to handle depth maps with poor quality in real usage. The key contributions of SparseDC are two-fold. First, we design a simple strategy, called SFFM, to improve the robustness under sparse input by explicitly filling the unstable depth features with stable image features. Second, we propose a two-branch feature embedder to predict both the precise local geometry of regions with available depth values and accurate structures in regions with no depth. The key of the embedder is an uncertainty-based fusion module called UFFM to balance the local and long-term information extracted by CNNs and ViTs. Extensive indoor and outdoor experiments demonstrate the robustness of our framework when facing sparse and non-uniform input depths. The pre-trained model and code are available at https://github.com/WHU-USI3DV/SparseDC.
WeLayout: WeChat Layout Analysis System for the ICDAR 2023 Competition on Robust Layout Segmentation in Corporate Documents
May 11, 2023



In this paper, we introduce WeLayout, a novel system for segmenting the layout of corporate documents, which stands for WeChat Layout Analysis System. Our approach utilizes a sophisticated ensemble of DINO and YOLO models, specifically developed for the ICDAR 2023 Competition on Robust Layout Segmentation. Our method significantly surpasses the baseline, securing a top position on the leaderboard with a mAP of 70.0. To achieve this performance, we concentrated on enhancing various aspects of the task, such as dataset augmentation, model architecture, bounding box refinement, and model ensemble techniques. Additionally, we trained the data separately for each document category to ensure a higher mean submission score. We also developed an algorithm for cell matching to further improve our performance. To identify the optimal weights and IoU thresholds for our model ensemble, we employed a Bayesian optimization algorithm called the Tree-Structured Parzen Estimator. Our approach effectively demonstrates the benefits of combining query-based and anchor-free models for achieving robust layout segmentation in corporate documents.
MFM-Net: Unpaired Shape Completion Network with Multi-stage Feature Matching
Nov 23, 2021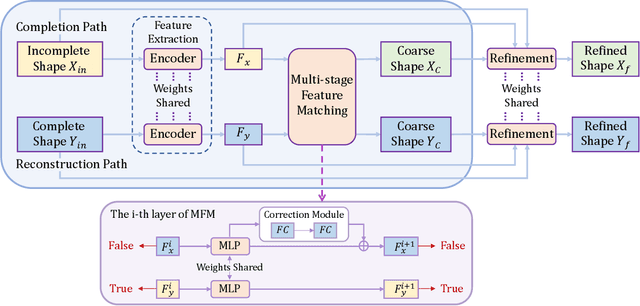
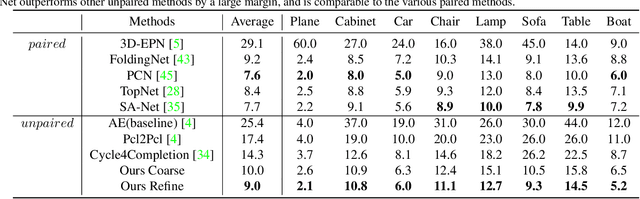
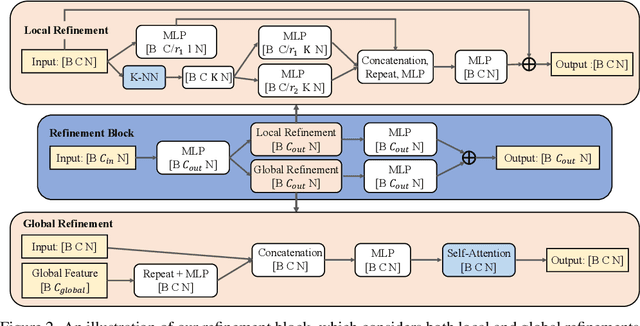
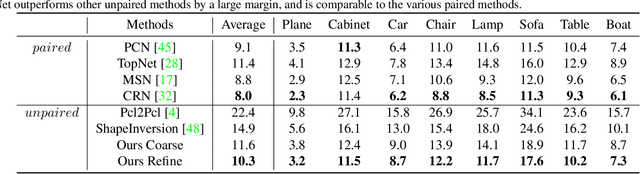
Unpaired 3D object completion aims to predict a complete 3D shape from an incomplete input without knowing the correspondence between the complete and incomplete shapes during training. To build the correspondence between two data modalities, previous methods usually apply adversarial training to match the global shape features extracted by the encoder. However, this ignores the correspondence between multi-scaled geometric information embedded in the pyramidal hierarchy of the decoder, which makes previous methods struggle to generate high-quality complete shapes. To address this problem, we propose a novel unpaired shape completion network, named MFM-Net, using multi-stage feature matching, which decomposes the learning of geometric correspondence into multi-stages throughout the hierarchical generation process in the point cloud decoder. Specifically, MFM-Net adopts a dual path architecture to establish multiple feature matching channels in different layers of the decoder, which is then combined with the adversarial learning to merge the distribution of features from complete and incomplete modalities. In addition, a refinement is applied to enhance the details. As a result, MFM-Net makes use of a more comprehensive understanding to establish the geometric correspondence between complete and incomplete shapes in a local-to-global perspective, which enables more detailed geometric inference for generating high-quality complete shapes. We conduct comprehensive experiments on several datasets, and the results show that our method outperforms previous methods of unpaired point cloud completion with a large margin.
A Real-time Low-cost Artificial Intelligence System for Autonomous Spraying in Palm Plantations
Mar 06, 2021



In precision crop protection, (target-orientated) object detection in image processing can help navigate Unmanned Aerial Vehicles (UAV, crop protection drones) to the right place to apply the pesticide. Unnecessary application of non-target areas could be avoided. Deep learning algorithms dominantly use in modern computer vision tasks which require high computing time, memory footprint, and power consumption. Based on the Edge Artificial Intelligence, we investigate the main three paths that lead to dealing with this problem, including hardware accelerators, efficient algorithms, and model compression. Finally, we integrate them and propose a solution based on a light deep neural network (DNN), called Ag-YOLO, which can make the crop protection UAV have the ability to target detection and autonomous operation. This solution is restricted in size, cost, flexible, fast, and energy-effective. The hardware is only 18 grams in weight and 1.5 watts in energy consumption, and the developed DNN model needs only 838 kilobytes of disc space. We tested the developed hardware and software in comparison to the tiny version of the state-of-art YOLOv3 framework, known as YOLOv3-Tiny to detect individual palm in a plantation. An average F1 score of 0.9205 at the speed of 36.5 frames per second (in comparison to similar accuracy at 18 frames per second and 8.66 megabytes of the YOLOv3-Tiny algorithm) was reached. This developed detection system is easily plugged into any machines already purchased as long as the machines have USB ports and run Linux Operating System.
Keyword-Attentive Deep Semantic Matching
Mar 11, 2020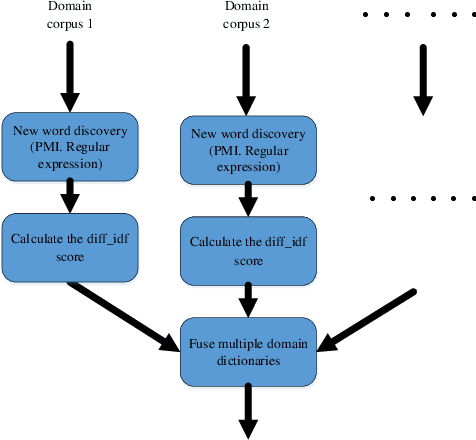
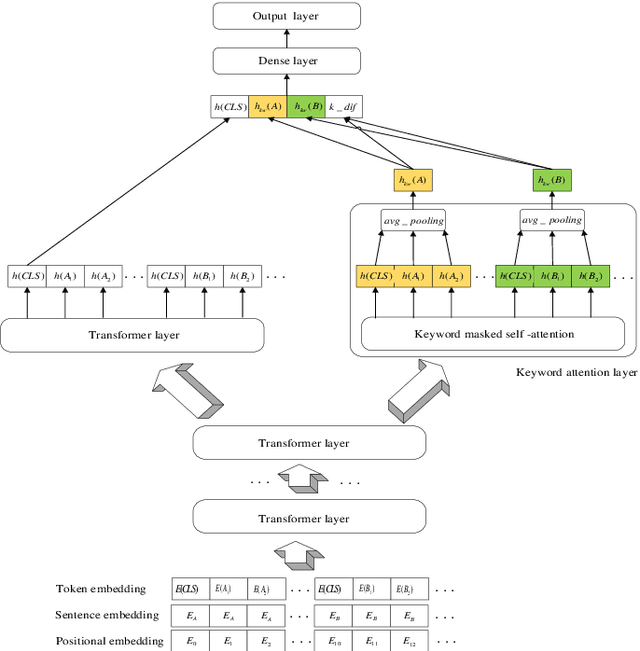


Deep Semantic Matching is a crucial component in various natural language processing applications such as question and answering (QA), where an input query is compared to each candidate question in a QA corpus in terms of relevance. Measuring similarities between a query-question pair in an open domain scenario can be challenging due to diverse word tokens in the queryquestion pair. We propose a keyword-attentive approach to improve deep semantic matching. We first leverage domain tags from a large corpus to generate a domain-enhanced keyword dictionary. Built upon BERT, we stack a keyword-attentive transformer layer to highlight the importance of keywords in the query-question pair. During model training, we propose a new negative sampling approach based on keyword coverage between the input pair. We evaluate our approach on a Chinese QA corpus using various metrics, including precision of retrieval candidates and accuracy of semantic matching. Experiments show that our approach outperforms existing strong baselines. Our approach is general and can be applied to other text matching tasks with little adaptation.