 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoirai 2.0: When Less Is More for Time Series Forecasting
Nov 12, 2025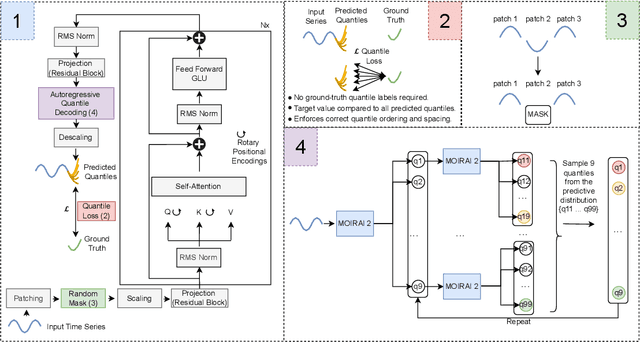
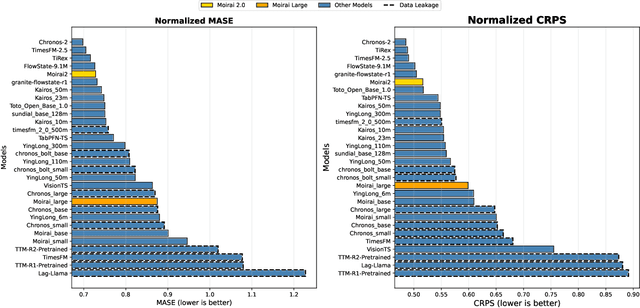

We introduce Moirai 2.0, a decoder-only time-series foundation model trained on a new corpus of 36M series. The model adopts quantile forecasting and multi-token prediction, improving both probabilistic accuracy and inference efficiency. On the Gift-Eval benchmark, it ranks among the top pretrained models while achieving a strong trade-off between accuracy, speed, and model size. Compared to Moirai 1.0, Moirai 2.0 replaces masked-encoder training, multi-patch inputs, and mixture-distribution outputs with a simpler decoder-only architecture, single patch, and quantile loss. Ablation studies isolate these changes -- showing that the decoder-only backbone along with recursive multi-quantile decoding contribute most to the gains. Additional experiments show that Moirai 2.0 outperforms larger models from the same family and exhibits robust domain-level results. In terms of efficiency and model size, Moirai 2.0 is twice as fast and thirty times smaller than its prior best version, Moirai 1.0-Large, while also performing better. Model performance plateaus with increasing parameter count and declines at longer horizons, motivating future work on data scaling and long-horizon modeling. We release code and evaluation details to support further research.
CompeteSMoE -- Statistically Guaranteed Mixture of Experts Training via Competition
May 19, 2025
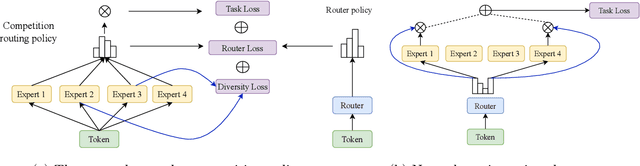


Sparse mixture of experts (SMoE) offers an appealing solution to scale up the model complexity beyond the mean of increasing the network's depth or width. However, we argue that effective SMoE training remains challenging because of the suboptimal routing process where experts that perform computation do not directly contribute to the routing process. In this work, we propose competition, a novel mechanism to route tokens to experts with the highest neural response. Theoretically, we show that the competition mechanism enjoys a better sample efficiency than the traditional softmax routing. Furthermore, we develop CompeteSMoE, a simple yet effective algorithm to train large language models by deploying a router to learn the competition policy, thus enjoying strong performances at a low training overhead. Our extensive empirical evaluations on both the visual instruction tuning and language pre-training tasks demonstrate the efficacy, robustness, and scalability of CompeteSMoE compared to state-of-the-art SMoE strategies. We have made the implementation available at: https://github.com/Fsoft-AIC/CompeteSMoE. This work is an improved version of the previous study at arXiv:2402.02526
On DeepSeekMoE: Statistical Benefits of Shared Experts and Normalized Sigmoid Gating
May 16, 2025Mixture of experts (MoE) methods are a key component in most large language model architectures, including the recent series of DeepSeek models. Compared to other MoE implementations, DeepSeekMoE stands out because of two unique features: the deployment of a shared expert strategy and of the normalized sigmoid gating mechanism. Despite the prominent role of DeepSeekMoE in the success of the DeepSeek series of models, there have been only a few attempts to justify theoretically the value of the shared expert strategy, while its normalized sigmoid gating has remained unexplored. To bridge this gap, we undertake a comprehensive theoretical study of these two features of DeepSeekMoE from a statistical perspective. We perform a convergence analysis of the expert estimation task to highlight the gains in sample efficiency for both the shared expert strategy and the normalized sigmoid gating, offering useful insights into the design of expert and gating structures. To verify empirically our theoretical findings, we carry out several experiments on both synthetic data and real-world datasets for (vision) language modeling tasks. Finally, we conduct an extensive empirical analysis of the router behaviors, ranging from router saturation, router change rate, to expert utilization.
Sequence Transferability and Task Order Selection in Continual Learning
Feb 10, 2025In continual learning, understanding the properties of task sequences and their relationships to model performance is important for developing advanced algorithms with better accuracy. However, efforts in this direction remain underdeveloped despite encouraging progress in methodology development. In this work, we investigate the impacts of sequence transferability on continual learning and propose two novel measures that capture the total transferability of a task sequence, either in the forward or backward direction. Based on the empirical properties of these measures, we then develop a new method for the task order selection problem in continual learning. Our method can be shown to offer a better performance than the conventional strategy of random task selection.
LIBMoE: A Library for comprehensive benchmarking Mixture of Experts in Large Language Models
Nov 01, 2024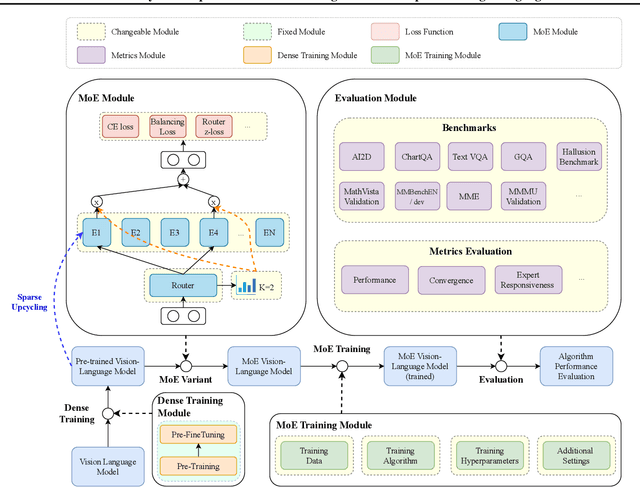
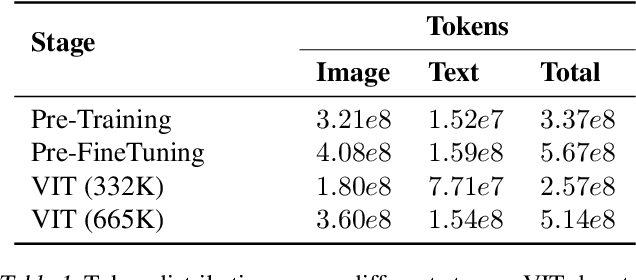
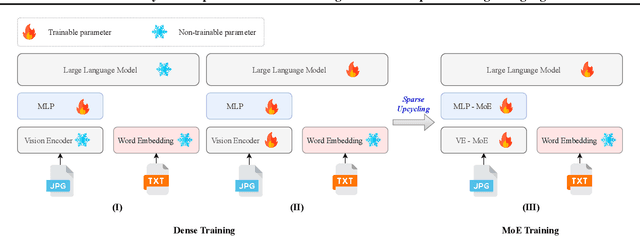
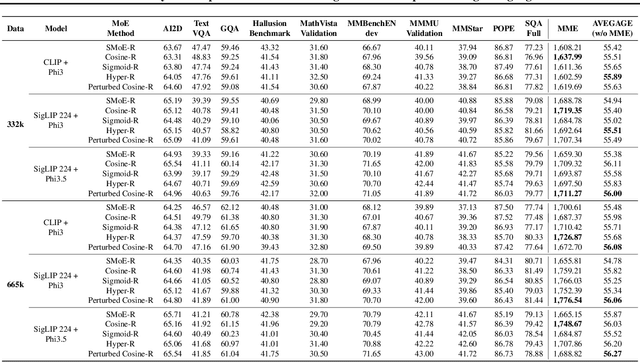
Mixture of Experts (MoEs) plays an important role in the development of more efficient and effective large language models (LLMs). Due to the enormous resource requirements, studying large scale MoE algorithms remain in-accessible to many researchers. This work develops \emph{LibMoE}, a comprehensive and modular framework to streamline the research, training, and evaluation of MoE algorithms. Built upon three core principles: (i) modular design, (ii) efficient training; (iii) comprehensive evaluation, LibMoE brings MoE in LLMs more accessible to a wide range of researchers by standardizing the training and evaluation pipelines. Using LibMoE, we extensively benchmarked five state-of-the-art MoE algorithms over three different LLMs and 11 datasets under the zero-shot setting. The results show that despite the unique characteristics, all MoE algorithms perform roughly similar when averaged across a wide range of tasks. With the modular design and extensive evaluation, we believe LibMoE will be invaluable for researchers to make meaningful progress towards the next generation of MoE and LLMs. Project page: \url{https://fsoft-aic.github.io/fsoft-LibMoE.github.io}.
Class-incremental Learning for Time Series: Benchmark and Evaluation
Feb 19, 2024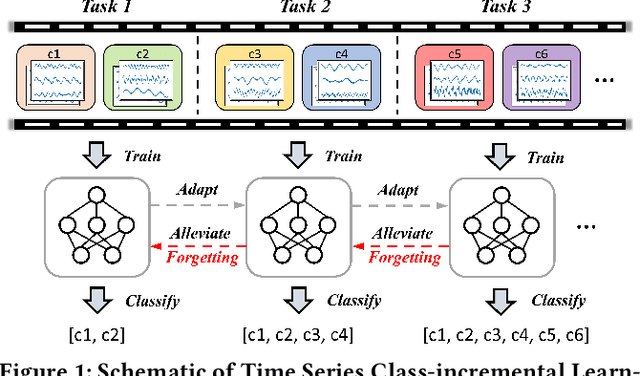
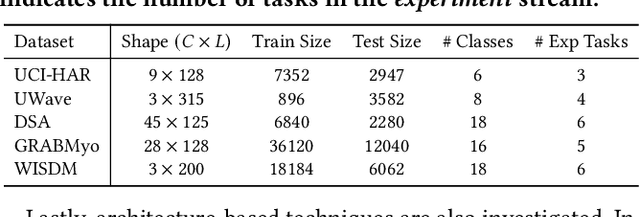
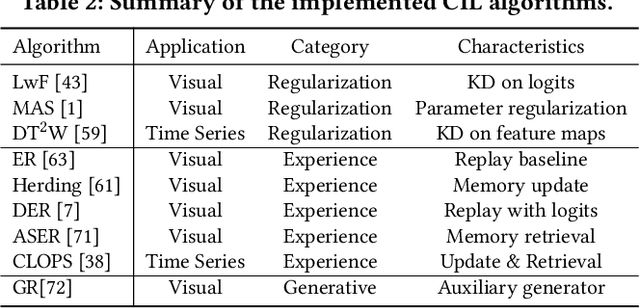
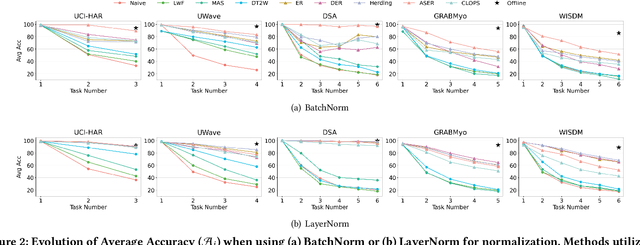
Real-world environments are inherently non-stationary, frequently introducing new classes over time. This is especially common in time series classification, such as the emergence of new disease classification in healthcare or the addition of new activities in human activity recognition. In such cases, a learning system is required to assimilate novel classes effectively while avoiding catastrophic forgetting of the old ones, which gives rise to the Class-incremental Learning (CIL) problem. However, despite the encouraging progress in the image and language domains, CIL for time series data remains relatively understudied. Existing studies suffer from inconsistent experimental designs, necessitating a comprehensive evaluation and benchmarking of methods across a wide range of datasets. To this end, we first present an overview of the Time Series Class-incremental Learning (TSCIL) problem, highlight its unique challenges, and cover the advanced methodologies. Further, based on standardized settings, we develop a unified experimental framework that supports the rapid development of new algorithms, easy integration of new datasets, and standardization of the evaluation process. Using this framework, we conduct a comprehensive evaluation of various generic and time-series-specific CIL methods in both standard and privacy-sensitive scenarios. Our extensive experiments not only provide a standard baseline to support future research but also shed light on the impact of various design factors such as normalization layers or memory budget thresholds. Codes are available at https://github.com/zqiao11/TSCIL.
CompeteSMoE -- Effective Training of Sparse Mixture of Experts via Competition
Feb 04, 2024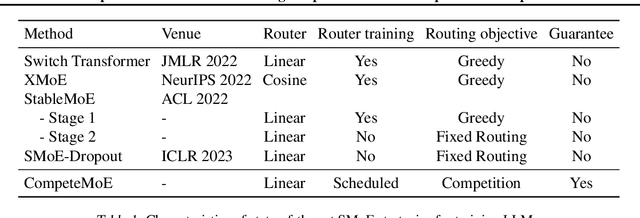
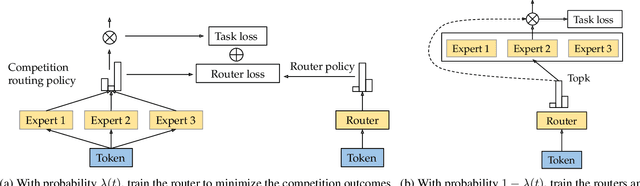
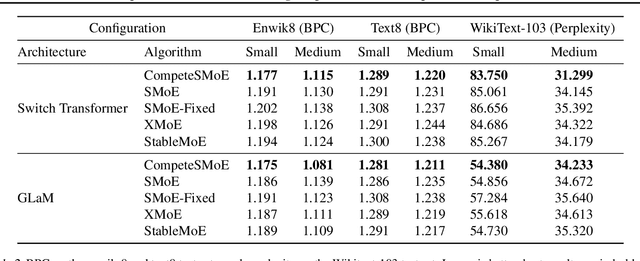
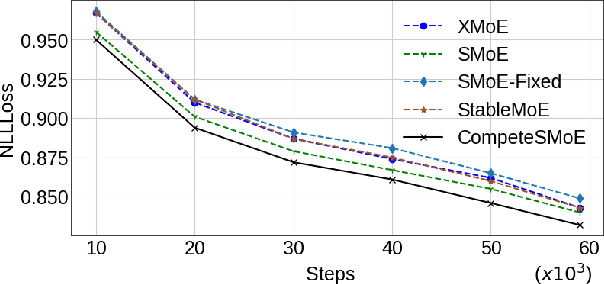
Sparse mixture of experts (SMoE) offers an appealing solution to scale up the model complexity beyond the mean of increasing the network's depth or width. However, effective training of SMoE has proven to be challenging due to the representation collapse issue, which causes parameter redundancy and limited representation potentials. In this work, we propose a competition mechanism to address this fundamental challenge of representation collapse. By routing inputs only to experts with the highest neural response, we show that, under mild assumptions, competition enjoys the same convergence rate as the optimal estimator. We further propose CompeteSMoE, an effective and efficient algorithm to train large language models by deploying a simple router that predicts the competition outcomes. Consequently, CompeteSMoE enjoys strong performance gains from the competition routing policy while having low computation overheads. Our extensive empirical evaluations on two transformer architectures and a wide range of tasks demonstrate the efficacy, robustness, and scalability of CompeteSMoE compared to state-of-the-art SMoE strategies.
HyperRouter: Towards Efficient Training and Inference of Sparse Mixture of Experts
Dec 12, 2023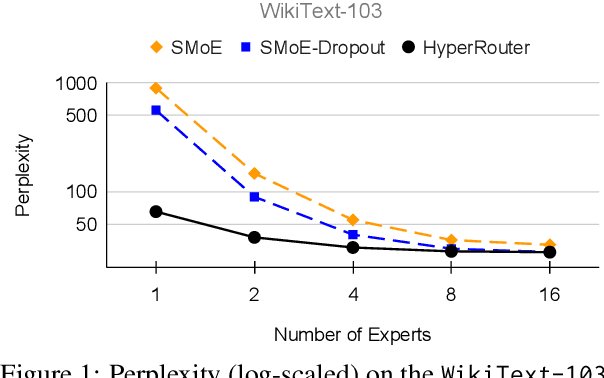
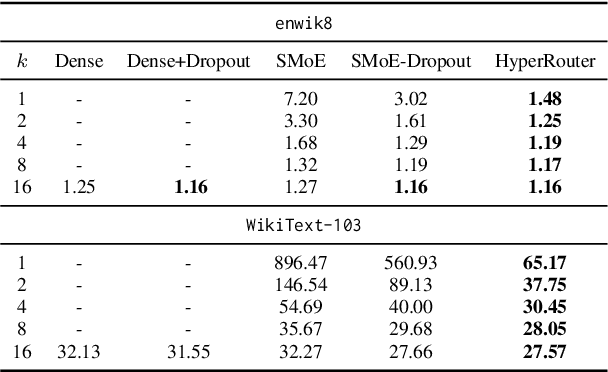
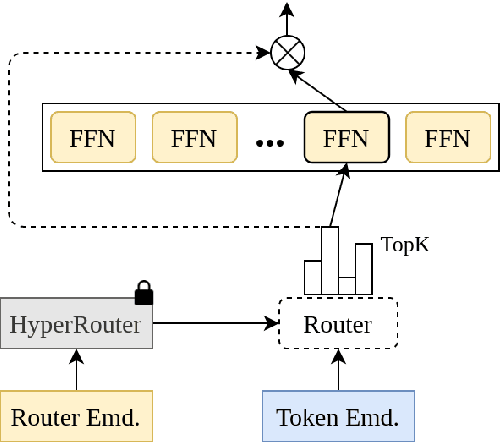

By routing input tokens to only a few split experts, Sparse Mixture-of-Experts has enabled efficient training of large language models. Recent findings suggest that fixing the routers can achieve competitive performance by alleviating the collapsing problem, where all experts eventually learn similar representations. However, this strategy has two key limitations: (i) the policy derived from random routers might be sub-optimal, and (ii) it requires extensive resources during training and evaluation, leading to limited efficiency gains. This work introduces \HyperRout, which dynamically generates the router's parameters through a fixed hypernetwork and trainable embeddings to achieve a balance between training the routers and freezing them to learn an improved routing policy. Extensive experiments across a wide range of tasks demonstrate the superior performance and efficiency gains of \HyperRouter compared to existing routing methods. Our implementation is publicly available at {\url{{https://github.com/giangdip2410/HyperRouter}}}.
On the Out of Distribution Robustness of Foundation Models in Medical Image Segmentation
Nov 18, 2023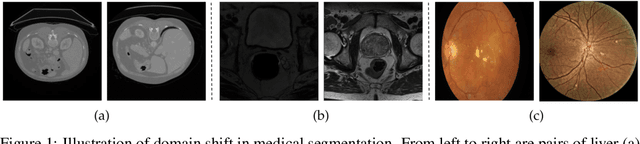
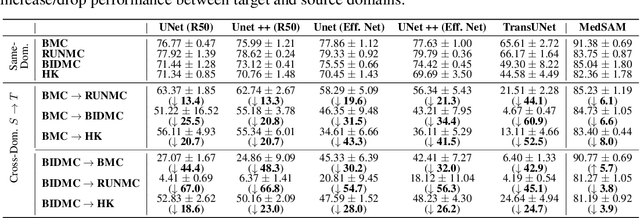
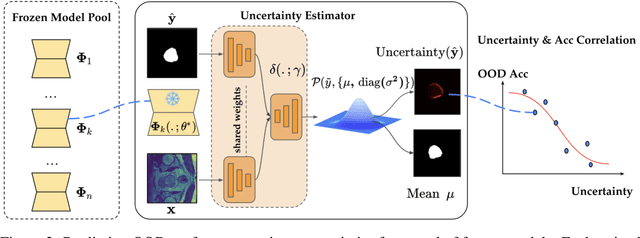
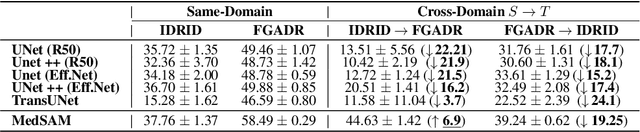
Constructing a robust model that can effectively generalize to test samples under distribution shifts remains a significant challenge in the field of medical imaging. The foundational models for vision and language, pre-trained on extensive sets of natural image and text data, have emerged as a promising approach. It showcases impressive learning abilities across different tasks with the need for only a limited amount of annotated samples. While numerous techniques have focused on developing better fine-tuning strategies to adapt these models for specific domains, we instead examine their robustness to domain shifts in the medical image segmentation task. To this end, we compare the generalization performance to unseen domains of various pre-trained models after being fine-tuned on the same in-distribution dataset and show that foundation-based models enjoy better robustness than other architectures. From here, we further developed a new Bayesian uncertainty estimation for frozen models and used them as an indicator to characterize the model's performance on out-of-distribution (OOD) data, proving particularly beneficial for real-world applications. Our experiments not only reveal the limitations of current indicators like accuracy on the line or agreement on the line commonly used in natural image applications but also emphasize the promise of the introduced Bayesian uncertainty. Specifically, lower uncertainty predictions usually tend to higher out-of-distribution (OOD) performance.
Adaptive-saturated RNN: Remember more with less instability
Apr 24, 2023



Orthogonal parameterization is a compelling solution to the vanishing gradient problem (VGP) in recurrent neural networks (RNNs). With orthogonal parameters and non-saturated activation functions, gradients in such models are constrained to unit norms. On the other hand, although the traditional vanilla RNNs are seen to have higher memory capacity, they suffer from the VGP and perform badly in many applications. This work proposes Adaptive-Saturated RNNs (asRNN), a variant that dynamically adjusts its saturation level between the two mentioned approaches. Consequently, asRNN enjoys both the capacity of a vanilla RNN and the training stability of orthogonal RNNs. Our experiments show encouraging results of asRNN on challenging sequence learning benchmarks compared to several strong competitors. The research code is accessible at https://github.com/ndminhkhoi46/asRNN/.
* 8 pages, 2 figures, 5 tables, ICLR 2023 Tiny Paper Track