 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymDrift: One-Shot Generative Modeling under Symmetries
May 07, 2026Generative modeling of physical systems, such as molecules, requires learning distributions that are invariant under global symmetries, such as rotations in three-dimensional space. Equivariant diffusion and flow matching models can incorporate such invariances effectively, even when trained on a non-invariant empirical distribution, but they typically rely on costly multi-step sampling. Recently, drifting models have emerged as an efficient alternative, enabling single-step generation and achieving state-of-the-art performance in generative modeling tasks. However, we show that drifting models face a symmetry-specific challenge, since an equivariant generator does not generally produce the same drifting field as the one obtained from the symmetrized target distribution. Addressing this issue would require expensive symmetrization of the empirical distribution. To avoid this cost, we propose SymDrift, a framework that makes the drifting field itself symmetry-aware. We introduce two complementary strategies: (i) a symmetrized drift in coordinate space based on optimal alignment, and (ii) a $G$-invariant embedding that removes symmetry ambiguity by construction. Empirically, SymDrift outperforms existing one-shot methods on standard benchmarks for conformer and transition state generation, while remaining competitive with significantly more expensive multi-step approaches. By enabling one-shot inference, SymDrift reduces computational overhead by up to 40$\times$ compared to existing baselines, making it promising for high-throughput applications such as virtual drug screening and large-scale reaction network exploration.
Learning to Discretize Denoising Diffusion ODEs
May 24, 2024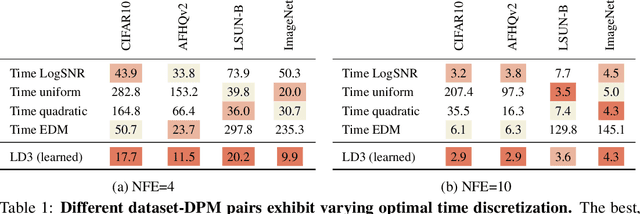
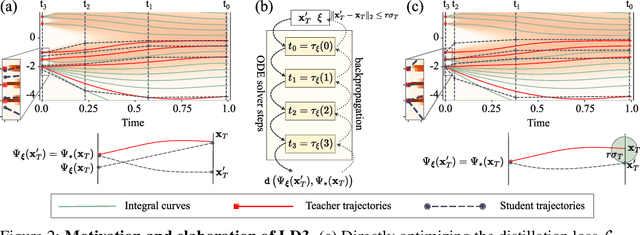
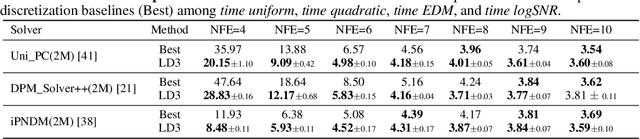
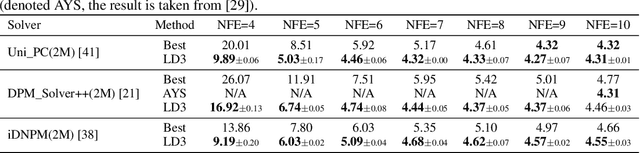
Diffusion Probabilistic Models (DPMs) are powerful generative models showing competitive performance in various domains, including image synthesis and 3D point cloud generation. However, sampling from pre-trained DPMs involves multiple neural function evaluations (NFE) to transform Gaussian noise samples into images, resulting in higher computational costs compared to single-step generative models such as GANs or VAEs. Therefore, a crucial problem is to reduce NFE while preserving generation quality. To this end, we propose LD3, a lightweight framework for learning time discretization while sampling from the diffusion ODE encapsulated by DPMs. LD3 can be combined with various diffusion ODE solvers and consistently improves performance without retraining resource-intensive neural networks. We demonstrate analytically and empirically that LD3 enhances sampling efficiency compared to distillation-based methods, without the extensive computational overhead. We evaluate our method with extensive experiments on 5 datasets, covering unconditional and conditional sampling in both pixel-space and latent-space DPMs. For example, in about 5 minutes of training on a single GPU, our method reduces the FID score from 6.63 to 2.68 on CIFAR10 (7 NFE), and in around 20 minutes, decreases the FID from 8.51 to 5.03 on class-conditional ImageNet-256 (5 NFE). LD3 complements distillation methods, offering a more efficient approach to sampling from pre-trained diffusion models.
On the Out of Distribution Robustness of Foundation Models in Medical Image Segmentation
Nov 18, 2023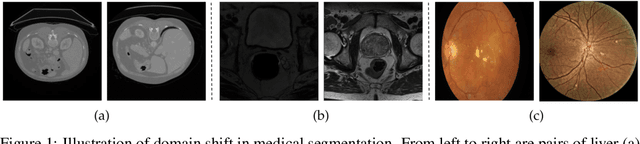
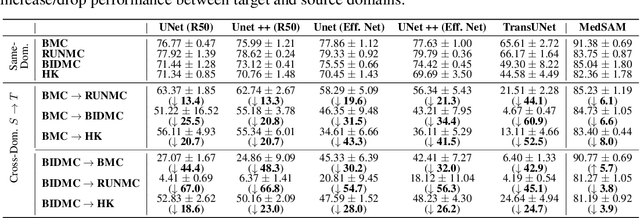
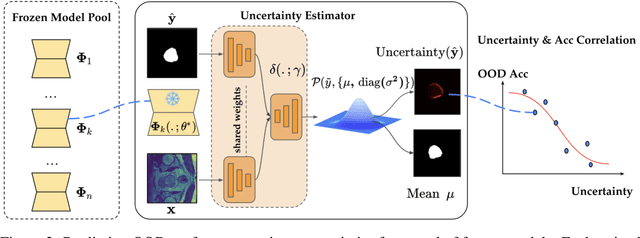
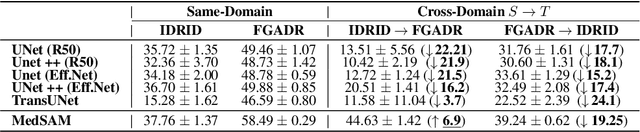
Constructing a robust model that can effectively generalize to test samples under distribution shifts remains a significant challenge in the field of medical imaging. The foundational models for vision and language, pre-trained on extensive sets of natural image and text data, have emerged as a promising approach. It showcases impressive learning abilities across different tasks with the need for only a limited amount of annotated samples. While numerous techniques have focused on developing better fine-tuning strategies to adapt these models for specific domains, we instead examine their robustness to domain shifts in the medical image segmentation task. To this end, we compare the generalization performance to unseen domains of various pre-trained models after being fine-tuned on the same in-distribution dataset and show that foundation-based models enjoy better robustness than other architectures. From here, we further developed a new Bayesian uncertainty estimation for frozen models and used them as an indicator to characterize the model's performance on out-of-distribution (OOD) data, proving particularly beneficial for real-world applications. Our experiments not only reveal the limitations of current indicators like accuracy on the line or agreement on the line commonly used in natural image applications but also emphasize the promise of the introduced Bayesian uncertainty. Specifically, lower uncertainty predictions usually tend to higher out-of-distribution (OOD) performance.
Joint Multilingual Knowledge Graph Completion and Alignment
Oct 18, 2022
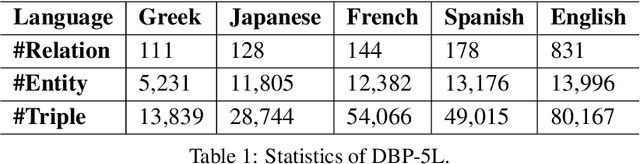
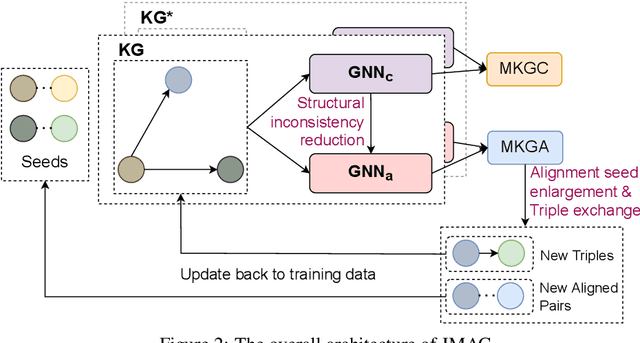
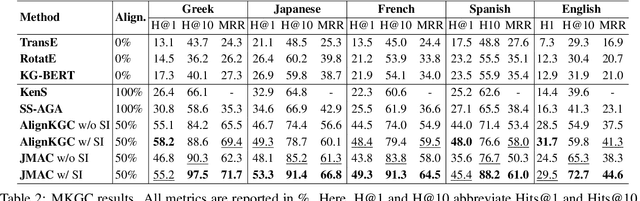
Knowledge graph (KG) alignment and completion are usually treated as two independent tasks. While recent work has leveraged entity and relation alignments from multiple KGs, such as alignments between multilingual KGs with common entities and relations, a deeper understanding of the ways in which multilingual KG completion (MKGC) can aid the creation of multilingual KG alignments (MKGA) is still limited. Motivated by the observation that structural inconsistencies -- the main challenge for MKGA models -- can be mitigated through KG completion methods, we propose a novel model for jointly completing and aligning knowledge graphs. The proposed model combines two components that jointly accomplish KG completion and alignment. These two components employ relation-aware graph neural networks that we propose to encode multi-hop neighborhood structures into entity and relation representations. Moreover, we also propose (i) a structural inconsistency reduction mechanism to incorporate information from the completion into the alignment component, and (ii) an alignment seed enlargement and triple transferring mechanism to enlarge alignment seeds and transfer triples during KGs alignment. Extensive experiments on a public multilingual benchmark show that our proposed model outperforms existing competitive baselines, obtaining new state-of-the-art results on both MKGC and MKGA tasks. We publicly release the implementation of our model at https://github.com/vinhsuhi/JMAC
Two-view Graph Neural Networks for Knowledge Graph Completion
Dec 16, 2021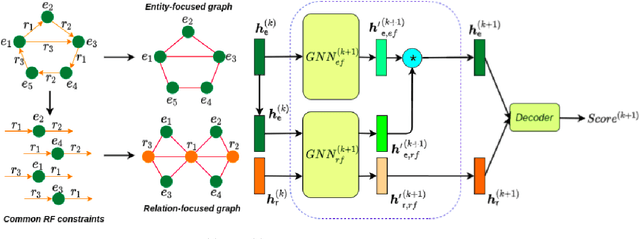

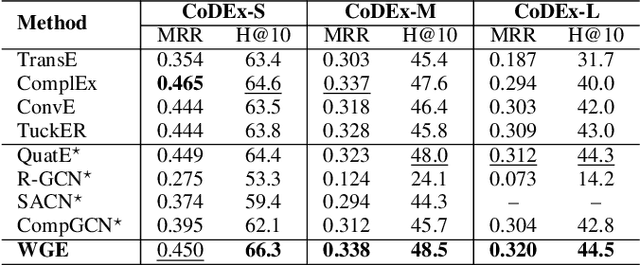
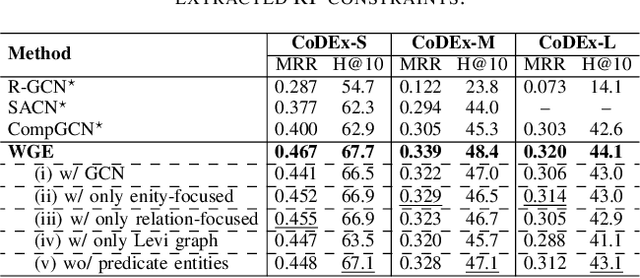
In this paper, we introduce a novel GNN-based knowledge graph embedding model, named WGE, to capture entity-focused graph structure and relation-focused graph structure. In particular, given the knowledge graph, WGE builds a single undirected entity-focused graph that views entities as nodes. In addition, WGE also constructs another single undirected graph from relation-focused constraints, which views entities and relations as nodes. WGE then proposes a new architecture of utilizing two vanilla GNNs directly on these two single graphs to better update vector representations of entities and relations, followed by a weighted score function to return the triple scores. Experimental results show that WGE obtains state-of-the-art performances on three new and challenging benchmark datasets CoDEx for knowledge graph completion.
Node Co-occurrence based Graph Neural Networks for Knowledge Graph Link Prediction
Apr 15, 2021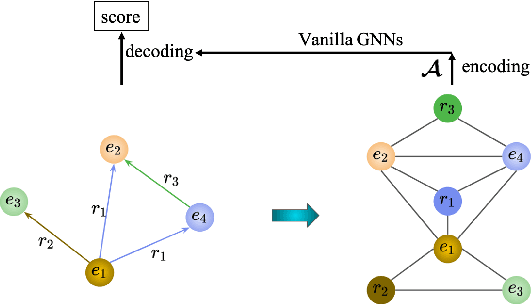
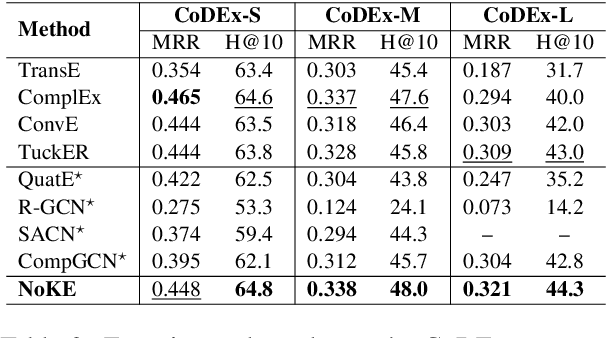
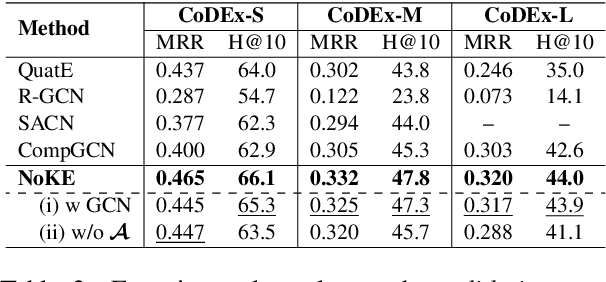
We introduce a novel embedding model, named NoKE, which aims to integrate co-occurrence among entities and relations into graph neural networks to improve knowledge graph completion (i.e., link prediction). Given a knowledge graph, NoKE constructs a single graph considering entities and relations as individual nodes. NoKE then computes weights for edges among nodes based on the co-occurrence of entities and relations. Next, NoKE utilizes vanilla GNNs to update vector representations for entity and relation nodes and then adopts a score function to produce the triple scores. Comprehensive experimental results show that our NoKE obtains state-of-the-art results on three new, challenging, and difficult benchmark datasets CoDEx for knowledge graph completion, demonstrating the power of its simplicity and effectiveness.