 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboGaze: Evaluating Robot World Models via Structured Vision-Language Analysis
Jun 22, 2026Recent advances in robot world models enable synthetic video generation for embodied prediction and planning. However, evaluating these videos is challenging: visually realistic outputs often violate physical laws, temporal consistency, or task logic, while conventional metrics and monolithic Vision-Language Model (VLM) judges fail to generalize or provide precise diagnostic value. We present RoboGaze, a training-free, multi-agent VLM framework that provides structured, interpretable evaluation for generated robot-manipulation videos. Given a task instruction and video, RoboGaze operates via a three-stage pipeline: task-scene grounding, dimension-specific specialist routing, and critic-based verification. It outputs temporally localized glitch reports categorized under a novel 6-dimension, 30-type robotics-specific taxonomy. To benchmark RoboGaze, we introduce a human-validated dataset of 382 clips spanning simulated and real-world multi-view manipulation. Evaluating eight open-source and proprietary VLM backbones, RoboGaze dramatically outperforms zero-shot baselines, improving description-F1 by up to +43 points and temporal alignment (F1 x IoU) by up to +37 points, closing approximately 85% of the gap to the human ceiling. Furthermore, its critic verifier mitigates the "cry-wolf" false-positive flaw of standard VLMs, lifting clean-clip accuracy from under 25% to over 80%. RoboGaze offers a scalable, highly interpretable diagnostic tool for the rigorous evaluation of robot world models.
OmniSpace: Efficient Geometry Awareness for Autonomous Vehicles MLLMs
Jun 21, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable performance on 2D visual tasks, yet enhancing their spatial intelligence for real-world applications such as Autonomous Vehicles (AV) remains an open challenge. Existing geometry-aware MLLMs typically rely on auxiliary 3D models at inference time, introducing pipeline complexity and the risk of cascading failures. In this paper, we present OmniSpace, a simple yet effective plug-and-play paradigm for geometry-aware spatial reasoning from purely 2D observations. Motivated by our finding that current MLLMs are bottlenecked by weak cross-view correspondence and depth estimation, OmniSpace introduces a Camera Pose Injector, a Multi-view Epipolar Attention module, and a 3D Geometric Distillation objective that jointly address these two limitations by transferring geometric knowledge into the model. Extensive experiments show that OmniSpace surpasses existing methods on planning benchmarks (nuScenes, Bench2Drive), risk detection (nuInstruct), language (Omnidrive), and generalization (DriveBench).
TSA: Temporal Slot Activation for Persistent Object-Centric Video Representation
Jun 10, 2026Unsupervised video object-centric learning aims to decompose dynamic scenes into temporally persistent entity representations. Existing recurrent video slot-attention methods propagate a fixed set of slots across frames, but typically assume unconditional slot propagation: every slot is updated and decoded at every frame, regardless of whether its corresponding object is visible. We show that this design violates a basic lifecycle requirement for persistent slots: when an object is absent or fully occluded, its slot should preserve its previous state and avoid explaining unrelated visible content. Instead, unconditional propagation creates two failure pathways: update-induced state drift, where current-frame evidence overwrites the absent object's representation, and decoder-induced reconstruction interference, where the inactive slot remains coupled to reconstruction through decoder attention. We propose Temporal Slot Activation (TSA), a mechanism that learns a per-slot, per-frame activation score $α_{k,t} \in (0, 1)$ without visibility supervision. TSA uses this activation as a shared latent control variable for slot lifecycle modeling. When a slot is inactive, TSA anchors its state to the previous slot via activation-gated updating and suppresses its decoder participation through an activation-dependent additive bias on attention logits before softmax normalization. This jointly reduces state drift and reconstruction-driven interference. To improve decisions under partial occlusion and gradual reappearance, TSA further conditions activation prediction on a per-slot temporal memory produced by a Temporal Context Encoder. We evaluate TSA on MOVi-C/E, YT-VIS, and OVIS benchmarks using both standard and tracking-based metrics (FG-ARI, mBO, IDF1, HOTA). TSA consistently improves object decomposition and temporal identity preservation, with large gains on long, heavily occluded videos.
DRIVESPATIAL: A Benchmark for Spatiotemporal Intelligence in VLMs for Autonomous Driving
May 22, 2026Spatiotemporal intelligence in autonomous driving (AD) requires an agent to integrate multi-view observations into a coherent scene representation, maintain object continuity across viewpoints and time, and reason about spatial relations, interactions, and future dynamics. However, existing AD vision-language benchmarks largely focus on single-view, static, ego-centric, or single-source question answering, leaving it unclear whether current Vision-Language Models (VLMs) can truly construct and reason over dynamic driving scenes. We introduce DriveSpatial, a benchmark of 15.6K human-verified QA pairs across 20 tasks from five large-scale AD datasets. DriveSpatial evaluates four abilities: Cognitive Scene Construction, Multi-view Relational Understanding, Temporal Reasoning, and Generalization. Unlike prior benchmarks, DriveSpatial is generated from a dynamic multi-relational scene graph that encodes object states, spatial relations, interactions, camera visibility, and temporal correspondences, enabling QA pairs that enforce genuine cross-view and spatiotemporal reasoning. Evaluating 15 representative VLMs reveals a substantial human-model gap: the strongest model trails humans by 28.4 points, with Cognitive Scene Construction emerging as the key bottleneck. Further diagnostics show that language-only prompting is insufficient, while explicit BEV grounding consistently improves performance. These results suggest that current VLMs lack the scene-construction ability needed for reliable spatiotemporal driving intelligence. DriveSpatial and its construction pipeline will be released to support future research.
TokenRatio: Principled Token-Level Preference Optimization via Ratio Matching
May 14, 2026Direct Preference Optimization (DPO) is a widely used RL-free method for aligning language models from pairwise preferences, but it models preferences over full sequences even though generation is driven by per-token decisions. Existing token-level extensions typically decompose a sequence-level Bradley-Terry objective across timesteps, leaving per-prefix (state-wise) optimality implicit. We study how to recover token-level preference optimality using only standard sequence-level pairwise comparisons. We introduce Token-level Bregman Preference Optimization (TBPO), which posits a token-level Bradley-Terry preference model over next-token actions conditioned on the prefix, and derive a Bregman-divergence density-ratio matching objective that generalizes the logistic/DPO loss while preserving the optimal policy induced by the token-level model and maintaining DPO-like simplicity. We introduce two instantiations: TBPO-Q, which explicitly learns a lightweight state baseline, and TBPO-A, which removes the baseline through advantage normalization. Across instruction following, helpfulness/harmlessness, and summarization benchmarks, TBPO improves alignment quality and training stability and increases output diversity relative to strong sequence-level and token-level baselines.
BSO: Safety Alignment Is Density Ratio Matching
May 12, 2026Aligning language models for both helpfulness and safety typically requires complex pipelines-separate reward and cost models, online reinforcement learning, and primal-dual updates. Recent direct preference optimization approaches simplify training but incorporate safety through ad-hoc modifications such as multi-stage procedures or heuristic margin terms, lacking a principled derivation. We show that the likelihood ratio of the optimal safe policy admits a closed-form decomposition that reduces safety alignment to a density ratio matching problem. Minimizing Bregman divergences between the data and model ratios yields Bregman Safety Optimization (BSO), a family of single-stage loss functions, each induced by a convex generator, that provably recover the optimal safe policy. BSO is both general and simple: it requires no auxiliary models, introduces only one hyperparameter beyond standard preference optimization, and recovers existing safety-aware methods as special cases. Experiments across safety alignment benchmarks show that BSO consistently improves the safety-helpfulness trade-off.
DuFal: Dual-Frequency-Aware Learning for High-Fidelity Extremely Sparse-view CBCT Reconstruction
Jan 21, 2026Sparse-view Cone-Beam Computed Tomography reconstruction from limited X-ray projections remains a challenging problem in medical imaging due to the inherent undersampling of fine-grained anatomical details, which correspond to high-frequency components. Conventional CNN-based methods often struggle to recover these fine structures, as they are typically biased toward learning low-frequency information. To address this challenge, this paper presents DuFal (Dual-Frequency-Aware Learning), a novel framework that integrates frequency-domain and spatial-domain processing via a dual-path architecture. The core innovation lies in our High-Local Factorized Fourier Neural Operator, which comprises two complementary branches: a Global High-Frequency Enhanced Fourier Neural Operator that captures global frequency patterns and a Local High-Frequency Enhanced Fourier Neural Operator that processes spatially partitioned patches to preserve spatial locality that might be lost in global frequency analysis. To improve efficiency, we design a Spectral-Channel Factorization scheme that reduces the Fourier Neural Operator parameter count. We also design a Cross-Attention Frequency Fusion module to integrate spatial and frequency features effectively. The fused features are then decoded through a Feature Decoder to produce projection representations, which are subsequently processed through an Intensity Field Decoding pipeline to reconstruct a final Computed Tomography volume. Experimental results on the LUNA16 and ToothFairy datasets demonstrate that DuFal significantly outperforms existing state-of-the-art methods in preserving high-frequency anatomical features, particularly under extremely sparse-view settings.
Rethinking Progression of Memory State in Robotic Manipulation: An Object-Centric Perspective
Nov 18, 2025As embodied agents operate in increasingly complex environments, the ability to perceive, track, and reason about individual object instances over time becomes essential, especially in tasks requiring sequenced interactions with visually similar objects. In these non-Markovian settings, key decision cues are often hidden in object-specific histories rather than the current scene. Without persistent memory of prior interactions (what has been interacted with, where it has been, or how it has changed) visuomotor policies may fail, repeat past actions, or overlook completed ones. To surface this challenge, we introduce LIBERO-Mem, a non-Markovian task suite for stress-testing robotic manipulation under object-level partial observability. It combines short- and long-horizon object tracking with temporally sequenced subgoals, requiring reasoning beyond the current frame. However, vision-language-action (VLA) models often struggle in such settings, with token scaling quickly becoming intractable even for tasks spanning just a few hundred frames. We propose Embodied-SlotSSM, a slot-centric VLA framework built for temporal scalability. It maintains spatio-temporally consistent slot identities and leverages them through two mechanisms: (1) slot-state-space modeling for reconstructing short-term history, and (2) a relational encoder to align the input tokens with action decoding. Together, these components enable temporally grounded, context-aware action prediction. Experiments show Embodied-SlotSSM's baseline performance on LIBERO-Mem and general tasks, offering a scalable solution for non-Markovian reasoning in object-centric robotic policies.
MGPATH: Vision-Language Model with Multi-Granular Prompt Learning for Few-Shot WSI Classification
Feb 11, 2025



Whole slide pathology image classification presents challenges due to gigapixel image sizes and limited annotation labels, hindering model generalization. This paper introduces a prompt learning method to adapt large vision-language models for few-shot pathology classification. We first extend the Prov-GigaPath vision foundation model, pre-trained on 1.3 billion pathology image tiles, into a vision-language model by adding adaptors and aligning it with medical text encoders via contrastive learning on 923K image-text pairs. The model is then used to extract visual features and text embeddings from few-shot annotations and fine-tunes with learnable prompt embeddings. Unlike prior methods that combine prompts with frozen features using prefix embeddings or self-attention, we propose multi-granular attention that compares interactions between learnable prompts with individual image patches and groups of them. This approach improves the model's ability to capture both fine-grained details and broader context, enhancing its recognition of complex patterns across sub-regions. To further improve accuracy, we leverage (unbalanced) optimal transport-based visual-text distance to secure model robustness by mitigating perturbations that might occur during the data augmentation process. Empirical experiments on lung, kidney, and breast pathology modalities validate the effectiveness of our approach; thereby, we surpass several of the latest competitors and consistently improve performance across diverse architectures, including CLIP, PLIP, and Prov-GigaPath integrated PLIP. We release our implementations and pre-trained models at this MGPATH.
On the Out of Distribution Robustness of Foundation Models in Medical Image Segmentation
Nov 18, 2023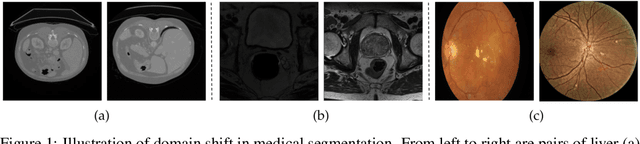
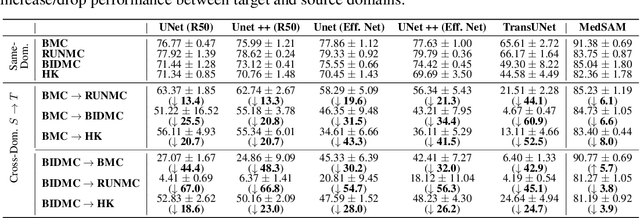
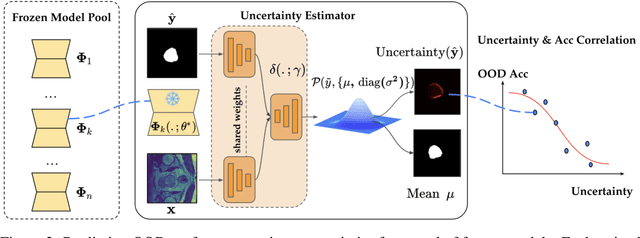
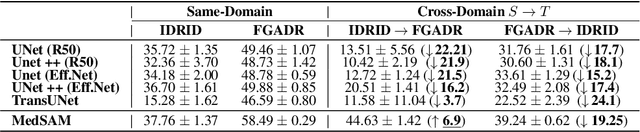
Constructing a robust model that can effectively generalize to test samples under distribution shifts remains a significant challenge in the field of medical imaging. The foundational models for vision and language, pre-trained on extensive sets of natural image and text data, have emerged as a promising approach. It showcases impressive learning abilities across different tasks with the need for only a limited amount of annotated samples. While numerous techniques have focused on developing better fine-tuning strategies to adapt these models for specific domains, we instead examine their robustness to domain shifts in the medical image segmentation task. To this end, we compare the generalization performance to unseen domains of various pre-trained models after being fine-tuned on the same in-distribution dataset and show that foundation-based models enjoy better robustness than other architectures. From here, we further developed a new Bayesian uncertainty estimation for frozen models and used them as an indicator to characterize the model's performance on out-of-distribution (OOD) data, proving particularly beneficial for real-world applications. Our experiments not only reveal the limitations of current indicators like accuracy on the line or agreement on the line commonly used in natural image applications but also emphasize the promise of the introduced Bayesian uncertainty. Specifically, lower uncertainty predictions usually tend to higher out-of-distribution (OOD) performance.