 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-dimensional Many-to-many-to-many Mediation Analysis
Apr 03, 2026We study high-dimensional mediation analysis in which exposures, mediators, and outcomes are all multivariate, and both exposures and mediators may be high-dimensional. We formalize this as a many (exposures)-to-many (mediators)-to-many (outcomes) (MMM) mediation analysis problem. Methodologically, MMM mediation analysis simultaneously performs variable selection for high-dimensional exposures and mediators, estimates the indirect effect matrix (i.e., the coefficient matrices linking exposure-to-mediator and mediator-to-outcome pathways), and enables prediction of multivariate outcomes. Theoretically, we show that the estimated indirect effect matrices are consistent and element-wise asymptotically normal, and we derive error bounds for the estimators. To evaluate the efficacy of the MMM mediation framework, we first investigate its finite-sample performance, including convergence properties, the behavior of the asymptotic approximations, and robustness to noise, via simulation studies. We then apply MMM mediation analysis to data from the Alzheimer's Disease Neuroimaging Initiative to study how cortical thickness of 202 brain regions may mediate the effects of 688 genome-wide significant single nucleotide polymorphisms (SNPs) (selected from approximately 1.5 million SNPs) on eleven cognitive-behavioral and diagnostic outcomes. The MMM mediation framework identifies biologically interpretable, many-to-many-to-many genetic-neural-cognitive pathways and improves downstream out-of-sample classification and prediction performance. Taken together, our results demonstrate the potential of MMM mediation analysis and highlight the value of statistical methodology for investigating complex, high-dimensional multi-layer pathways in science. The MMM package is available at https://github.com/THELabTop/MMM-Mediation.
Revisiting Incremental Stochastic Majorization-Minimization Algorithms with Applications to Mixture of Experts
Jan 27, 2026Processing high-volume, streaming data is increasingly common in modern statistics and machine learning, where batch-mode algorithms are often impractical because they require repeated passes over the full dataset. This has motivated incremental stochastic estimation methods, including the incremental stochastic Expectation-Maximization (EM) algorithm formulated via stochastic approximation. In this work, we revisit and analyze an incremental stochastic variant of the Majorization-Minimization (MM) algorithm, which generalizes incremental stochastic EM as a special case. Our approach relaxes key EM requirements, such as explicit latent-variable representations, enabling broader applicability and greater algorithmic flexibility. We establish theoretical guarantees for the incremental stochastic MM algorithm, proving consistency in the sense that the iterates converge to a stationary point characterized by a vanishing gradient of the objective. We demonstrate these advantages on a softmax-gated mixture of experts (MoE) regression problem, for which no stochastic EM algorithm is available. Empirically, our method consistently outperforms widely used stochastic optimizers, including stochastic gradient descent, root mean square propagation, adaptive moment estimation, and second-order clipped stochastic optimization. These results support the development of new incremental stochastic algorithms, given the central role of softmax-gated MoE architectures in contemporary deep neural networks for heterogeneous data modeling. Beyond synthetic experiments, we also validate practical effectiveness on two real-world datasets, including a bioinformatics study of dent maize genotypes under drought stress that integrates high-dimensional proteomics with ecophysiological traits, where incremental stochastic MM yields stable gains in predictive performance.
Fusionista2.0: Efficiency Retrieval System for Large-Scale Datasets
Nov 15, 2025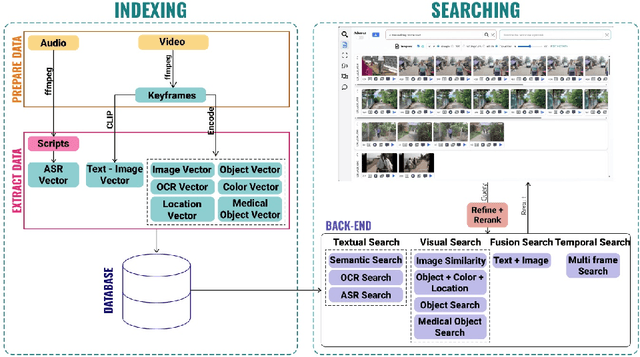

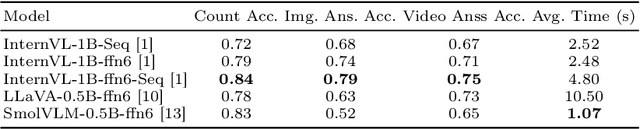
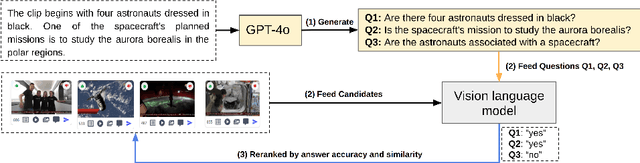
The Video Browser Showdown (VBS) challenges systems to deliver accurate results under strict time constraints. To meet this demand, we present Fusionista2.0, a streamlined video retrieval system optimized for speed and usability. All core modules were re-engineered for efficiency: preprocessing now relies on ffmpeg for fast keyframe extraction, optical character recognition uses Vintern-1B-v3.5 for robust multilingual text recognition, and automatic speech recognition employs faster-whisper for real-time transcription. For question answering, lightweight vision-language models provide quick responses without the heavy cost of large models. Beyond these technical upgrades, Fusionista2.0 introduces a redesigned user interface with improved responsiveness, accessibility, and workflow efficiency, enabling even non-expert users to retrieve relevant content rapidly. Evaluations demonstrate that retrieval time was reduced by up to 75% while accuracy and user satisfaction both increased, confirming Fusionista2.0 as a competitive and user-friendly system for large-scale video search.
ViConBERT: Context-Gloss Aligned Vietnamese Word Embedding for Polysemous and Sense-Aware Representations
Nov 15, 2025Recent advances in contextualized word embeddings have greatly improved semantic tasks such as Word Sense Disambiguation (WSD) and contextual similarity, but most progress has been limited to high-resource languages like English. Vietnamese, in contrast, still lacks robust models and evaluation resources for fine-grained semantic understanding. In this paper, we present ViConBERT, a novel framework for learning Vietnamese contextualized embeddings that integrates contrastive learning (SimCLR) and gloss-based distillation to better capture word meaning. We also introduce ViConWSD, the first large-scale synthetic dataset for evaluating semantic understanding in Vietnamese, covering both WSD and contextual similarity. Experimental results show that ViConBERT outperforms strong baselines on WSD (F1 = 0.87) and achieves competitive performance on ViCon (AP = 0.88) and ViSim-400 (Spearman's rho = 0.60), demonstrating its effectiveness in modeling both discrete senses and graded semantic relations. Our code, models, and data are available at https://github.com/tkhangg0910/ViConBERT
Dendrograms of Mixing Measures for Softmax-Gated Gaussian Mixture of Experts: Consistency without Model Sweeps
Oct 14, 2025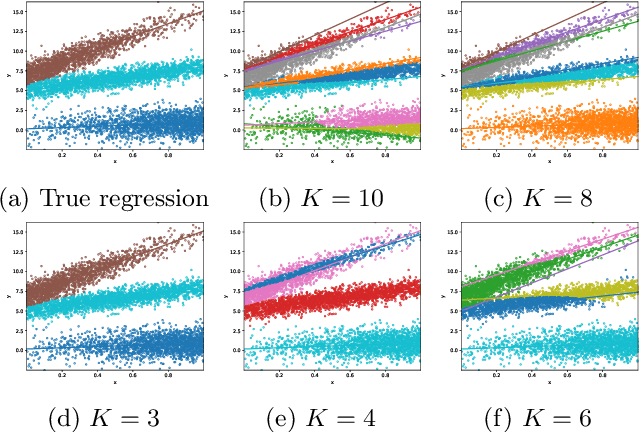

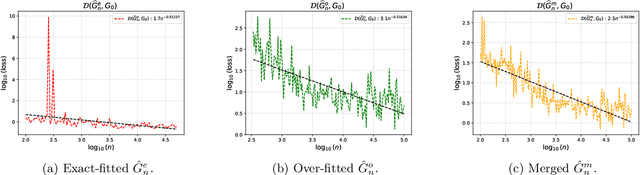
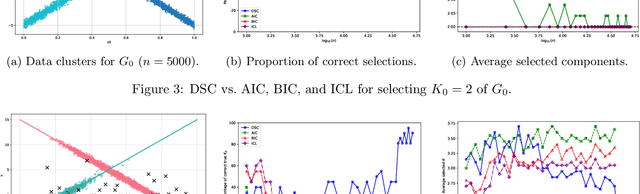
We develop a unified statistical framework for softmax-gated Gaussian mixture of experts (SGMoE) that addresses three long-standing obstacles in parameter estimation and model selection: (i) non-identifiability of gating parameters up to common translations, (ii) intrinsic gate-expert interactions that induce coupled differential relations in the likelihood, and (iii) the tight numerator-denominator coupling in the softmax-induced conditional density. Our approach introduces Voronoi-type loss functions aligned with the gate-partition geometry and establishes finite-sample convergence rates for the maximum likelihood estimator (MLE). In over-specified models, we reveal a link between the MLE's convergence rate and the solvability of an associated system of polynomial equations characterizing near-nonidentifiable directions. For model selection, we adapt dendrograms of mixing measures to SGMoE, yielding a consistent, sweep-free selector of the number of experts that attains pointwise-optimal parameter rates under overfitting while avoiding multi-size training. Simulations on synthetic data corroborate the theory, accurately recovering the expert count and achieving the predicted rates for parameter estimation while closely approximating the regression function. Under model misspecification (e.g., $\epsilon$-contamination), the dendrogram selection criterion is robust, recovering the true number of mixture components, while the Akaike information criterion, the Bayesian information criterion, and the integrated completed likelihood tend to overselect as sample size grows. On a maize proteomics dataset of drought-responsive traits, our dendrogram-guided SGMoE selects two experts, exposes a clear mixing-measure hierarchy, stabilizes the likelihood early, and yields interpretable genotype-phenotype maps, outperforming standard criteria without multi-size training.
The Reasoning Boundary Paradox: How Reinforcement Learning Constrains Language Models
Oct 02, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a key method for improving Large Language Models' reasoning capabilities, yet recent evidence suggests it may paradoxically shrink the reasoning boundary rather than expand it. This paper investigates the shrinkage issue of RLVR by analyzing its learning dynamics and reveals two critical phenomena that explain this failure. First, we expose negative interference in RLVR, where learning to solve certain training problems actively reduces the likelihood of correct solutions for others, leading to the decline of Pass@$k$ performance, or the probability of generating a correct solution within $k$ attempts. Second, we uncover the winner-take-all phenomenon: RLVR disproportionately reinforces problems with high likelihood, correct solutions, under the base model, while suppressing other initially low-likelihood ones. Through extensive theoretical and empirical analysis on multiple mathematical reasoning benchmarks, we show that this effect arises from the inherent on-policy sampling in standard RL objectives, causing the model to converge toward narrow solution strategies. Based on these insights, we propose a simple yet effective data curation algorithm that focuses RLVR learning on low-likelihood problems, achieving notable improvement in Pass@$k$ performance. Our code is available at https://github.com/mail-research/SELF-llm-interference.
HFedATM: Hierarchical Federated Domain Generalization via Optimal Transport and Regularized Mean Aggregation
Aug 07, 2025



Federated Learning (FL) is a decentralized approach where multiple clients collaboratively train a shared global model without sharing their raw data. Despite its effectiveness, conventional FL faces scalability challenges due to excessive computational and communication demands placed on a single central server as the number of participating devices grows. Hierarchical Federated Learning (HFL) addresses these issues by distributing model aggregation tasks across intermediate nodes (stations), thereby enhancing system scalability and robustness against single points of failure. However, HFL still suffers from a critical yet often overlooked limitation: domain shift, where data distributions vary significantly across different clients and stations, reducing model performance on unseen target domains. While Federated Domain Generalization (FedDG) methods have emerged to improve robustness to domain shifts, their integration into HFL frameworks remains largely unexplored. In this paper, we formally introduce Hierarchical Federated Domain Generalization (HFedDG), a novel scenario designed to investigate domain shift within hierarchical architectures. Specifically, we propose HFedATM, a hierarchical aggregation method that first aligns the convolutional filters of models from different stations through Filter-wise Optimal Transport Alignment and subsequently merges aligned models using a Shrinkage-aware Regularized Mean Aggregation. Our extensive experimental evaluations demonstrate that HFedATM significantly boosts the performance of existing FedDG baselines across multiple datasets and maintains computational and communication efficiency. Moreover, theoretical analyses indicate that HFedATM achieves tighter generalization error bounds compared to standard hierarchical averaging, resulting in faster convergence and stable training behavior.
Mitigating Reward Over-optimization in Direct Alignment Algorithms with Importance Sampling
Jun 11, 2025Direct Alignment Algorithms (DAAs) such as Direct Preference Optimization (DPO) have emerged as alternatives to the standard Reinforcement Learning from Human Feedback (RLHF) for aligning large language models (LLMs) with human values. However, these methods are more susceptible to over-optimization, in which the model drifts away from the reference policy, leading to degraded performance as training progresses. This paper proposes a novel importance-sampling approach to mitigate the over-optimization problem of offline DAAs. This approach, called (IS-DAAs), multiplies the DAA objective with an importance ratio that accounts for the reference policy distribution. IS-DAAs additionally avoid the high variance issue associated with importance sampling by clipping the importance ratio to a maximum value. Our extensive experiments demonstrate that IS-DAAs can effectively mitigate over-optimization, especially under low regularization strength, and achieve better performance than other methods designed to address this problem. Our implementations are provided publicly at this link.
A Unified Framework for Variable Selection in Model-Based Clustering with Missing Not at Random
May 25, 2025Model-based clustering integrated with variable selection is a powerful tool for uncovering latent structures within complex data. However, its effectiveness is often hindered by challenges such as identifying relevant variables that define heterogeneous subgroups and handling data that are missing not at random, a prevalent issue in fields like transcriptomics. While several notable methods have been proposed to address these problems, they typically tackle each issue in isolation, thereby limiting their flexibility and adaptability. This paper introduces a unified framework designed to address these challenges simultaneously. Our approach incorporates a data-driven penalty matrix into penalized clustering to enable more flexible variable selection, along with a mechanism that explicitly models the relationship between missingness and latent class membership. We demonstrate that, under certain regularity conditions, the proposed framework achieves both asymptotic consistency and selection consistency, even in the presence of missing data. This unified strategy significantly enhances the capability and efficiency of model-based clustering, advancing methodologies for identifying informative variables that define homogeneous subgroups in the presence of complex missing data patterns. The performance of the framework, including its computational efficiency, is evaluated through simulations and demonstrated using both synthetic and real-world transcriptomic datasets.
REMEMBER: Retrieval-based Explainable Multimodal Evidence-guided Modeling for Brain Evaluation and Reasoning in Zero- and Few-shot Neurodegenerative Diagnosis
Apr 12, 2025Timely and accurate diagnosis of neurodegenerative disorders, such as Alzheimer's disease, is central to disease management. Existing deep learning models require large-scale annotated datasets and often function as "black boxes". Additionally, datasets in clinical practice are frequently small or unlabeled, restricting the full potential of deep learning methods. Here, we introduce REMEMBER -- Retrieval-based Explainable Multimodal Evidence-guided Modeling for Brain Evaluation and Reasoning -- a new machine learning framework that facilitates zero- and few-shot Alzheimer's diagnosis using brain MRI scans through a reference-based reasoning process. Specifically, REMEMBER first trains a contrastively aligned vision-text model using expert-annotated reference data and extends pseudo-text modalities that encode abnormality types, diagnosis labels, and composite clinical descriptions. Then, at inference time, REMEMBER retrieves similar, human-validated cases from a curated dataset and integrates their contextual information through a dedicated evidence encoding module and attention-based inference head. Such an evidence-guided design enables REMEMBER to imitate real-world clinical decision-making process by grounding predictions in retrieved imaging and textual context. Specifically, REMEMBER outputs diagnostic predictions alongside an interpretable report, including reference images and explanations aligned with clinical workflows. Experimental results demonstrate that REMEMBER achieves robust zero- and few-shot performance and offers a powerful and explainable framework to neuroimaging-based diagnosis in the real world, especially under limited data.