 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePROL : Rehearsal Free Continual Learning in Streaming Data via Prompt Online Learning
Jul 16, 2025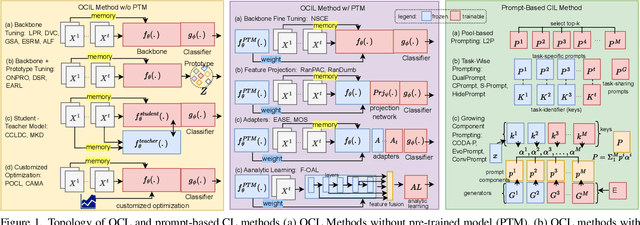
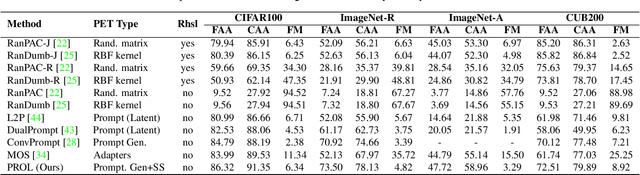
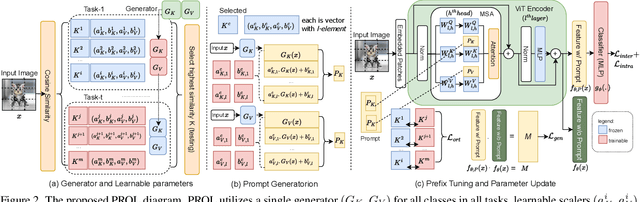
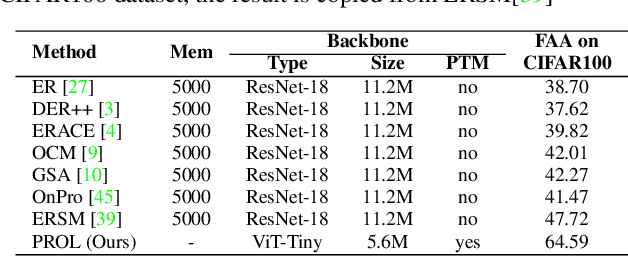
The data privacy constraint in online continual learning (OCL), where the data can be seen only once, complicates the catastrophic forgetting problem in streaming data. A common approach applied by the current SOTAs in OCL is with the use of memory saving exemplars or features from previous classes to be replayed in the current task. On the other hand, the prompt-based approach performs excellently in continual learning but with the cost of a growing number of trainable parameters. The first approach may not be applicable in practice due to data openness policy, while the second approach has the issue of throughput associated with the streaming data. In this study, we propose a novel prompt-based method for online continual learning that includes 4 main components: (1) single light-weight prompt generator as a general knowledge, (2) trainable scaler-and-shifter as specific knowledge, (3) pre-trained model (PTM) generalization preserving, and (4) hard-soft updates mechanism. Our proposed method achieves significantly higher performance than the current SOTAs in CIFAR100, ImageNet-R, ImageNet-A, and CUB dataset. Our complexity analysis shows that our method requires a relatively smaller number of parameters and achieves moderate training time, inference time, and throughput. For further study, the source code of our method is available at https://github.com/anwarmaxsum/PROL.
CompeteSMoE -- Statistically Guaranteed Mixture of Experts Training via Competition
May 19, 2025
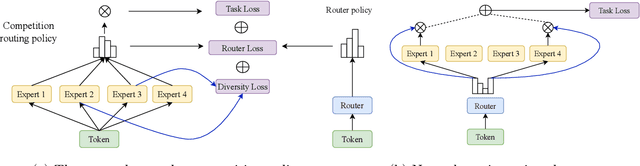


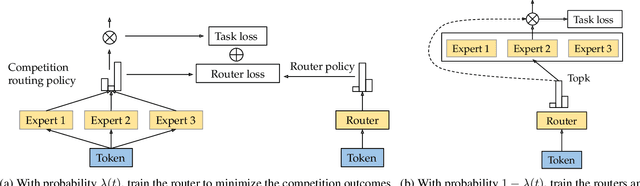
Sparse mixture of experts (SMoE) offers an appealing solution to scale up the model complexity beyond the mean of increasing the network's depth or width. However, we argue that effective SMoE training remains challenging because of the suboptimal routing process where experts that perform computation do not directly contribute to the routing process. In this work, we propose competition, a novel mechanism to route tokens to experts with the highest neural response. Theoretically, we show that the competition mechanism enjoys a better sample efficiency than the traditional softmax routing. Furthermore, we develop CompeteSMoE, a simple yet effective algorithm to train large language models by deploying a router to learn the competition policy, thus enjoying strong performances at a low training overhead. Our extensive empirical evaluations on both the visual instruction tuning and language pre-training tasks demonstrate the efficacy, robustness, and scalability of CompeteSMoE compared to state-of-the-art SMoE strategies. We have made the implementation available at: https://github.com/Fsoft-AIC/CompeteSMoE. This work is an improved version of the previous study at arXiv:2402.02526
Sequence Transferability and Task Order Selection in Continual Learning
Feb 10, 2025In continual learning, understanding the properties of task sequences and their relationships to model performance is important for developing advanced algorithms with better accuracy. However, efforts in this direction remain underdeveloped despite encouraging progress in methodology development. In this work, we investigate the impacts of sequence transferability on continual learning and propose two novel measures that capture the total transferability of a task sequence, either in the forward or backward direction. Based on the empirical properties of these measures, we then develop a new method for the task order selection problem in continual learning. Our method can be shown to offer a better performance than the conventional strategy of random task selection.
PIP: Prototypes-Injected Prompt for Federated Class Incremental Learning
Jul 30, 2024



Federated Class Incremental Learning (FCIL) is a new direction in continual learning (CL) for addressing catastrophic forgetting and non-IID data distribution simultaneously. Existing FCIL methods call for high communication costs and exemplars from previous classes. We propose a novel rehearsal-free method for FCIL named prototypes-injected prompt (PIP) that involves 3 main ideas: a) prototype injection on prompt learning, b) prototype augmentation, and c) weighted Gaussian aggregation on the server side. Our experiment result shows that the proposed method outperforms the current state of the arts (SOTAs) with a significant improvement (up to 33%) in CIFAR100, MiniImageNet and TinyImageNet datasets. Our extensive analysis demonstrates the robustness of PIP in different task sizes, and the advantage of requiring smaller participating local clients, and smaller global rounds. For further study, source codes of PIP, baseline, and experimental logs are shared publicly in https://github.com/anwarmaxsum/PIP.
Prompt-Enhanced Spatio-Temporal Graph Transfer Learning
May 21, 2024Spatio-temporal graph neural networks have demonstrated efficacy in capturing complex dependencies for urban computing tasks such as forecasting and kriging. However, their performance is constrained by the reliance on extensive data for training on specific tasks, which limits their adaptability to new urban domains with varied demands. Although transfer learning has been proposed to address this problem by leveraging knowledge across domains, cross-task generalization remains underexplored in spatio-temporal graph transfer learning methods due to the absence of a unified framework. To bridge this gap, we propose Spatio-Temporal Graph Prompting (STGP), a prompt-enhanced transfer learning framework capable of adapting to diverse tasks in data-scarce domains. Specifically, we first unify different tasks into a single template and introduce a task-agnostic network architecture that aligns with this template. This approach enables the capture of spatio-temporal dependencies shared across tasks. Furthermore, we employ learnable prompts to achieve domain and task transfer in a two-stage prompting pipeline, enabling the prompts to effectively capture domain knowledge and task-specific properties at each stage. Extensive experiments demonstrate that STGP outperforms state-of-the-art baselines in three downstream tasks forecasting, kriging, and extrapolation by a notable margin.
Continual Learning for Robust Gate Detection under Dynamic Lighting in Autonomous Drone Racing
May 02, 2024



In autonomous and mobile robotics, a principal challenge is resilient real-time environmental perception, particularly in situations characterized by unknown and dynamic elements, as exemplified in the context of autonomous drone racing. This study introduces a perception technique for detecting drone racing gates under illumination variations, which is common during high-speed drone flights. The proposed technique relies upon a lightweight neural network backbone augmented with capabilities for continual learning. The envisaged approach amalgamates predictions of the gates' positional coordinates, distance, and orientation, encapsulating them into a cohesive pose tuple. A comprehensive number of tests serve to underscore the efficacy of this approach in confronting diverse and challenging scenarios, specifically those involving variable lighting conditions. The proposed methodology exhibits notable robustness in the face of illumination variations, thereby substantiating its effectiveness.
CompeteSMoE -- Effective Training of Sparse Mixture of Experts via Competition
Feb 04, 2024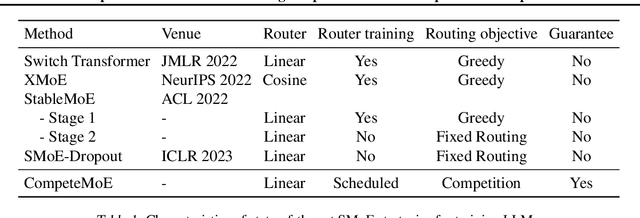
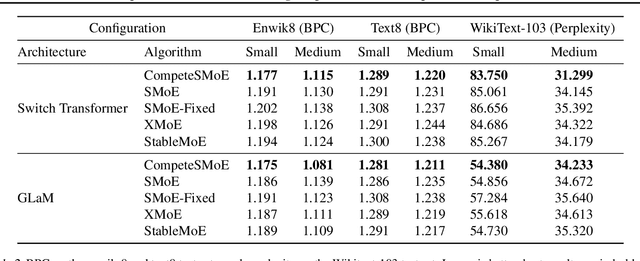
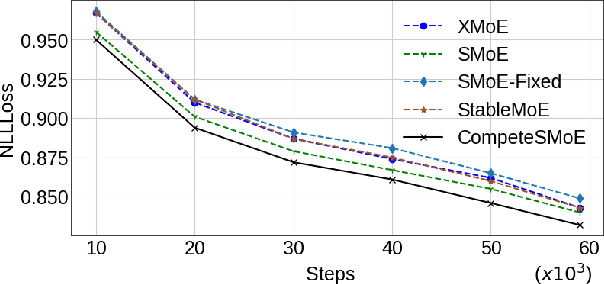
Sparse mixture of experts (SMoE) offers an appealing solution to scale up the model complexity beyond the mean of increasing the network's depth or width. However, effective training of SMoE has proven to be challenging due to the representation collapse issue, which causes parameter redundancy and limited representation potentials. In this work, we propose a competition mechanism to address this fundamental challenge of representation collapse. By routing inputs only to experts with the highest neural response, we show that, under mild assumptions, competition enjoys the same convergence rate as the optimal estimator. We further propose CompeteSMoE, an effective and efficient algorithm to train large language models by deploying a simple router that predicts the competition outcomes. Consequently, CompeteSMoE enjoys strong performance gains from the competition routing policy while having low computation overheads. Our extensive empirical evaluations on two transformer architectures and a wide range of tasks demonstrate the efficacy, robustness, and scalability of CompeteSMoE compared to state-of-the-art SMoE strategies.
Dynamic Long-Term Time-Series Forecasting via Meta Transformer Networks
Jan 25, 2024



A reliable long-term time-series forecaster is highly demanded in practice but comes across many challenges such as low computational and memory footprints as well as robustness against dynamic learning environments. This paper proposes Meta-Transformer Networks (MANTRA) to deal with the dynamic long-term time-series forecasting tasks. MANTRA relies on the concept of fast and slow learners where a collection of fast learners learns different aspects of data distributions while adapting quickly to changes. A slow learner tailors suitable representations to fast learners. Fast adaptations to dynamic environments are achieved using the universal representation transformer layers producing task-adapted representations with a small number of parameters. Our experiments using four datasets with different prediction lengths demonstrate the advantage of our approach with at least $3\%$ improvements over the baseline algorithms for both multivariate and univariate settings. Source codes of MANTRA are publicly available in \url{https://github.com/anwarmaxsum/MANTRA}.
HyperRouter: Towards Efficient Training and Inference of Sparse Mixture of Experts
Dec 12, 2023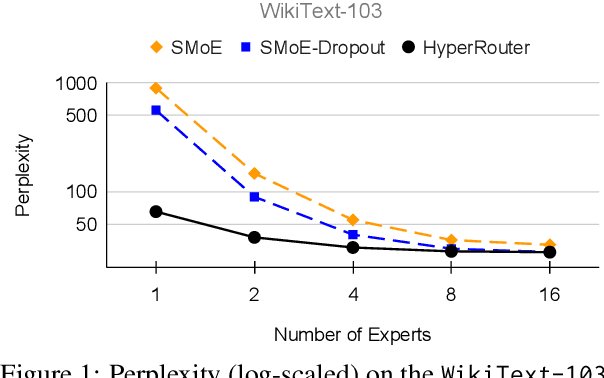
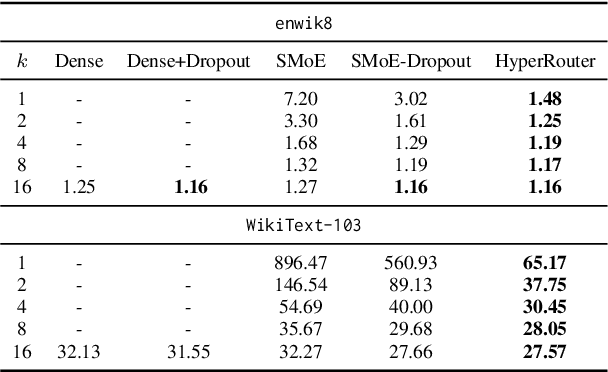
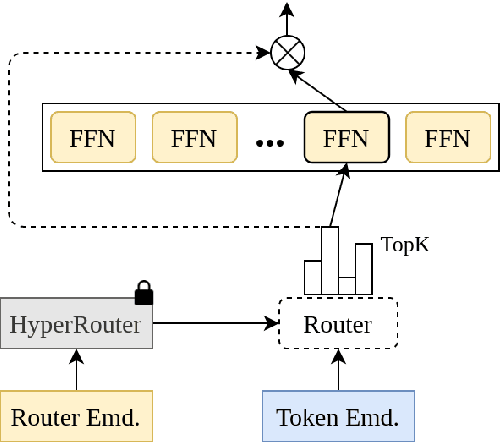

By routing input tokens to only a few split experts, Sparse Mixture-of-Experts has enabled efficient training of large language models. Recent findings suggest that fixing the routers can achieve competitive performance by alleviating the collapsing problem, where all experts eventually learn similar representations. However, this strategy has two key limitations: (i) the policy derived from random routers might be sub-optimal, and (ii) it requires extensive resources during training and evaluation, leading to limited efficiency gains. This work introduces \HyperRout, which dynamically generates the router's parameters through a fixed hypernetwork and trainable embeddings to achieve a balance between training the routers and freezing them to learn an improved routing policy. Extensive experiments across a wide range of tasks demonstrate the superior performance and efficiency gains of \HyperRouter compared to existing routing methods. Our implementation is publicly available at {\url{{https://github.com/giangdip2410/HyperRouter}}}.
Contrastive predictive coding for Anomaly Detection in Multi-variate Time Series Data
Feb 08, 2022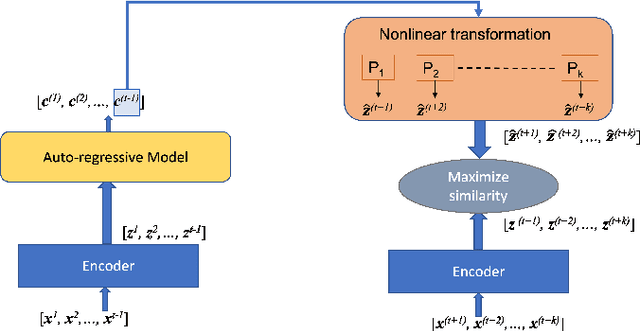


Anomaly detection in multi-variate time series (MVTS) data is a huge challenge as it requires simultaneous representation of long term temporal dependencies and correlations across multiple variables. More often, this is solved by breaking the complexity through modeling one dependency at a time. In this paper, we propose a Time-series Representational Learning through Contrastive Predictive Coding (TRL-CPC) towards anomaly detection in MVTS data. First, we jointly optimize an encoder, an auto-regressor and a non-linear transformation function to effectively learn the representations of the MVTS data sets, for predicting future trends. It must be noted that the context vectors are representative of the observation window in the MTVS. Next, the latent representations for the succeeding instants obtained through non-linear transformations of these context vectors, are contrasted with the latent representations of the encoder for the multi-variables such that the density for the positive pair is maximized. Thus, the TRL-CPC helps to model the temporal dependencies and the correlations of the parameters for a healthy signal pattern. Finally, fitting the latent representations are fit into a Gaussian scoring function to detect anomalies. Evaluation of the proposed TRL-CPC on three MVTS data sets against SOTA anomaly detection methods shows the superiority of TRL-CPC.